
随机森林模型
3.1 随机森林模型
Section titled “3.1 随机森林模型”学习目标
- 掌握利用随机森林快速实现投满分项目的基线模型.
- 能够完成模型部署
- 理解整个算法建模、评估、上线整个流程
为什么要做基线模型?:
**基线模型(Baseline Model)**是AI建模任务的重要起点,主要核心目标是:
① 快速验证任务可行性:基线模型通常简单高效,能够快速验证数据和任务的可行性,为后续优化提供方向。
② 提供性能参考:基线模型的性能为后续复杂模型(如深度学习模型)提供对比基准,衡量改进效果。
③ 降低开发成本:基线模型实现简单,能在资源有限的情况下快速构建一个可用的解决方案。
④ 发现问题:通过基线模型的训练和评估,可以发现潜在的一些问题,例如数据质量问题。
(一) 代码结构图
Section titled “(一) 代码结构图”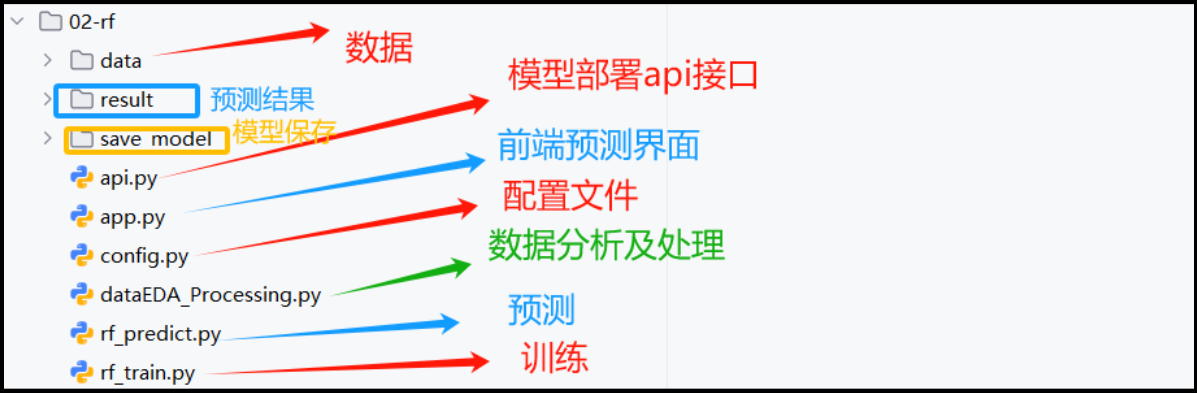
基于随机森林分类建模思路:
① 对数据train.txt等相关文件的文本列进行 分词处理, 得到words列。
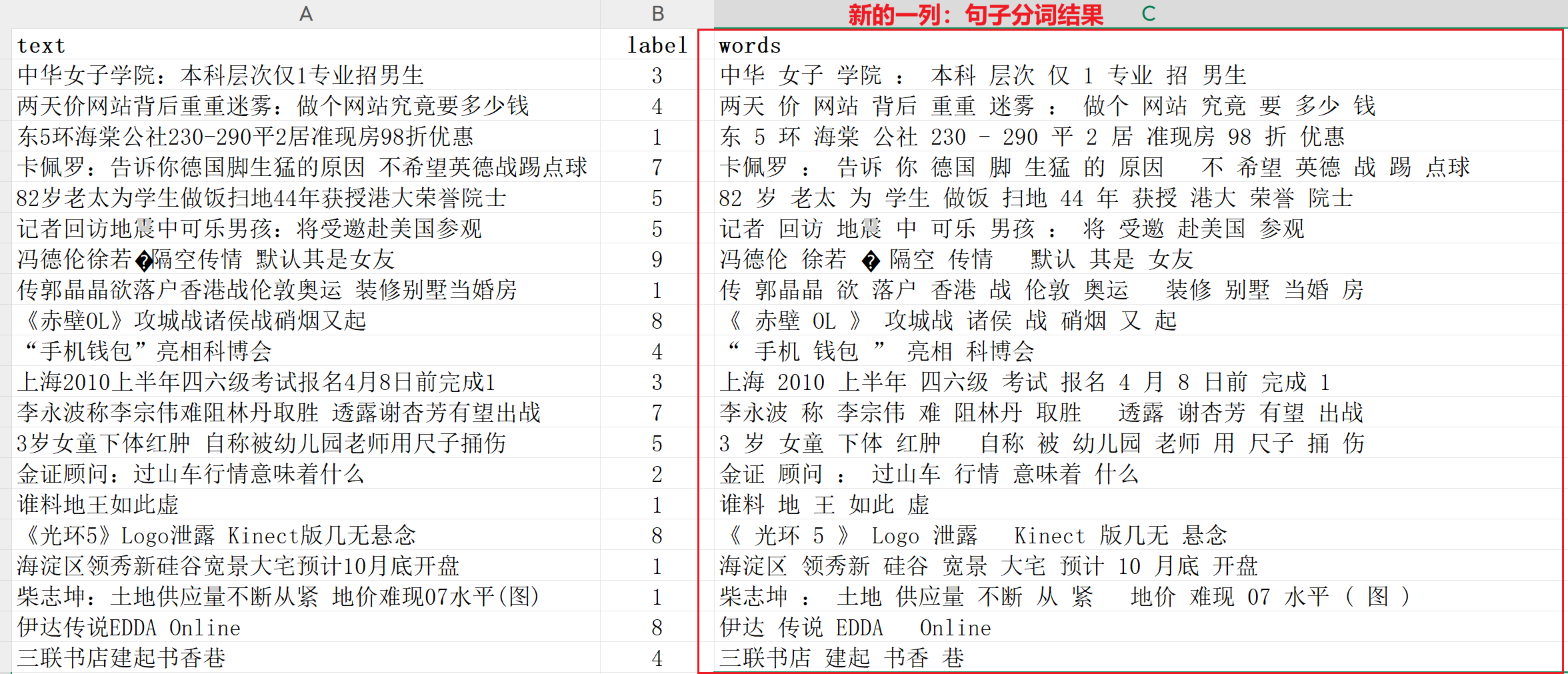 ② 采用TF-IDF将words列,转换为数值特征
② 采用TF-IDF将words列,转换为数值特征

③ 利用随机森林算法进行建模、评估与保存。
④ 模型预测
⑤ 模型部署,提供api接口
⑥ 前端预测实现
(二) 代码实现
Section titled “(二) 代码实现”2.1 config配置文件
Section titled “2.1 config配置文件”代码位置:TMFCode\02-rf\config.py
class Config(object): def __init__(self): #原始数据路径 self.train_datapath="处理前训练数据路径" self.test_datapath ="处理前测试数据路径" self.dev_datapath ="处理前验证数据路径"
#处理后的数据路径 self.processt_train_datapath = "处理后训练数据路径" self.proces_test_datapath = "处理后测试数据路径" self.proces_dev_datapath = "处理后验证数据路径"
#停用词路径 self.stop_words_path=r"stopwords.txt"
#保存模型路径 self.rf_model_save_path=r"模型存放路径" self.model_predict_result=r"预测结果存放路径" #self.WERKZEUG_RUN_MAIN=True2.2 数据处理
Section titled “2.2 数据处理”代码位置:
TMFCode\02-rf\dataEDA_Processing.py导入工具包及初始化配置
import pandas as pdimport jiebafrom config import Config# 初始化配置文件conf = Config()(1) 读取数据
Section titled “(1) 读取数据”#设置处理的及分析的文件路径,默认为 train.txtcurrent_path=conf.train_datapathcurrent_path=conf.test_datapathcurrent_path=conf.dev_datapath# 第一步:读取数据df = pd.read_csv(current_path, sep='\t', names=['text', 'label']) # 读取CSV文件,指定列名为text和label(2) 进行分词预处理
Section titled “(2) 进行分词预处理”# 第二步:进行分词预处理def cut_sentence(s): """对输入文本进行结巴分词,并限制前30个词""" return ' '.join(list(jieba.cut(s))[:30]) # 分词后取前30个词并用空格连接df['words'] = df['text'].apply(cut_sentence) # 对每行文本进行分词并存储到words列(3) 保存数据
Section titled “(3) 保存数据”# 第三步:保存处理后的数据if "train" in current_path: df.to_csv(conf.processt_train_datapath, index=False)# 将处理后的数据保存到CSV文件 print(f"train数据已经处理完成,已经成功保存至:{conf.processt_train_datapath}")elif "test" in current_path: df.to_csv(conf.proces_test_datapath, index=False)# 将处理后的数据保存到CSV文件 print(f"test数据已经处理完成,已经成功保存至:{conf.proces_test_datapath}")elif "dev" in current_path: df.to_csv(conf.proces_dev_datapath, index=False)# 将处理后的数据保存到CSV文件 print(f"dev数据已经处理完成,已经成功保存至:{conf.proces_dev_datapath}")2.3 模型训练
Section titled “2.3 模型训练”代码位置:
TMFCode\02-rf\rf_train.py导入工具包及初始化配置
import pandas as pdimport picklefrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score, precision_score, recall_score, f1_scorefrom config import Configfrom tqdm import tqdm # 引入 tqdm 用于进度条pd.set_option('display.expand_frame_repr', False) # 避免宽表格换行pd.set_option('display.max_columns', None) # 确保所有列可见conf = Config()(1) 读取数据
Section titled “(1) 读取数据”# 第一步:读取数据# 读取训练数据集df = pd.read_csv(conf.processt_train_datapath)words = df["words"]labels = df["label"]print(df.head(5))(2) 将文本转换为数值特征
Section titled “(2) 将文本转换为数值特征”注意:目前有非常多的方式可以实现文本到数值的转换,例如one-hot等等,本次采用tf-idf进行文本的数值化处理。它的核心是将文本转化为一组数字(向量),让计算机能处理文字。
1 TF-IDF介绍
Section titled “1 TF-IDF介绍”TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种将文本转化为数值向量的向量化方法。它由两部分组成,TF 和 IDF。
- TF 为term frequency,即词频。衡量一个词在一篇文章里出现的频率(出现的次数/文章总词数)。
- 逆文档频率(inverse document frequency):IDF 用来衡量一个词在所有文章中的“独特性”。如果一个词只在少数文章中出现(很罕见),它就更能代表这些文章的特殊内容,IDF 分数高,说明它很重要;如果一个词几乎每篇文章都有(很常见),它对区分文章内容没太大帮助,IDF 分数低,说明它不重要。
① TF
# 样例数据:D1: 中华 女子 学院 本科 层次 仅 1 专业 招 男生D2: 两天 价 网站 背后 重重 迷雾 : 做个 网站 究竟 要 多少 钱D3: 东 5 环 海棠 公社 230 - 290 平 2 居 准现房 98 折 优惠D4: 卡佩罗 : 告诉 你 德国 脚 生猛 的 原因 不 希望 英德 战 踢 点球D5: 82 岁 老太 为 学生 做饭 扫地 44 年 获 授 港大 荣誉 院士第①步,计算词频TF。
- 为具体的词,(如“本科”)。
- : 当前文档(如 D1)
- TF作用:衡量当前词在当前文档的频率。考虑到文章有长短之分,为了便于不同文章的比较,进行 “词频” 标准化(归一化),也就有了上述分母。
- 示例:TF(“本科”,D1) = 1/10
② IDF
第②步,计算逆文档频率。看一个词在所有文章中是否罕见。罕见的词(如“本科”)分数高,常见的词(如“的”)分数低。
-
: 总文档数。
-
: 出现词 的文档数
-
示例:(“本科”) =
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。这里分母+1,是为了避免分母为0(即所有文档都不包含该词)。
log表示对得到的值取对数。
③ TF-IDF
第③步,计算TF-IDF。 含义:结合 TF 和 IDF,计算词 在文档 的重要性分数。
④总结
TF-IDF 是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数的增加成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF 的主要思想是:如果某个单词在一篇文章中出现的频率 TF 高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
2 代码实现
Section titled “2 代码实现”# 第二步:将文本转换为数值特征# 读取停用词文件stop_words = open(conf.stop_words_path,encoding="utf-8").read().split()tfidf = TfidfVectorizer(stop_words=stop_words)features = tfidf.fit_transform(words)
# 查看特征,features是稀疏矩阵,稀疏矩阵的格式是 (row, column) valueprint(features)# 查看特征维度 1000行 4687print(features.shape)print(list(tfidf.get_feature_names_out()))print(len(tfidf.get_feature_names_out()))print(tfidf.vocabulary_)print(len(tfidf.vocabulary_))(3) 模型训练和模型评估
Section titled “(3) 模型训练和模型评估”# 第三步:划分训练集和测试集,模型训练和模型预测评估# 划分数据集x_train, x_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=22)
# 训练随机森林模型model = RandomForestClassifier() # 默认参数print("训练模型...")# 使用 tqdm 包装 model.fit 来显示进度条for _ in tqdm(range(1), desc="RandomForest模型训练进度...."): model.fit(x_train, y_train)
# 模型预测并评估print("模型预测评估...")y_pred = model.predict(x_test)print("预测结果:", y_pred)print("准确率:", accuracy_score(y_test, y_pred))print("精确率 (micro):", precision_score(y_test, y_pred, average='micro'))print("召回率 (micro):", recall_score(y_test, y_pred, average='micro'))print("F1分数 (micro):", f1_score(y_test, y_pred, average='micro'))(4) 模型保存
Section titled “(4) 模型保存”# 第四步:保存模型和向量化器print("保存模型和向量化器...")with open(conf.rf_model_save_path + '/rf_model.pkl', 'wb') as f: pickle.dump(model, f)with open(conf.rf_model_save_path + '/tfidf_vectorizer.pkl', 'wb') as f: pickle.dump(tfidf, f)
print("模型和向量化器,保存成功!")输出结果日志:
预测结果: [4 7 8 ... 3 8 5]准确率: 0.8247777777777778精确率 (micro): 0.8247777777777778召回率 (micro): 0.8247777777777778F1分数 (micro): 0.8247777777777778保存模型和向量化器...模型和向量化器,保存成功!2.4 模型预测
Section titled “2.4 模型预测”代码位置:
TMFCode\02-rf\rf_predict.py导入工具包及初始化配置
import pandas as pdimport picklefrom config import Configimport warningswarnings.filterwarnings('ignore')
# 设置pandas显示选项pd.set_option('display.max_columns', None)# 加载配置conf = Config()(1) 加载模型及向量化器
Section titled “(1) 加载模型及向量化器”# 第一步:加载保存的模型和向量化器print("加载模型和向量化器...")with open(conf.rf_model_save_path + '/rf_model.pkl', 'rb') as f: model = pickle.load(f)with open(conf.rf_model_save_path + '/tfidf_vectorizer.pkl', 'rb') as f: tfidf = pickle.load(f)(2) 读取dev数据
Section titled “(2) 读取dev数据”print("读取dev数据...")dev_df = pd.read_csv(conf.proces_dev_datapath)print("dev数据前5行:")print(dev_df.head(5))(3) 特征工程(tfidf)
Section titled “(3) 特征工程(tfidf)”print("转换dev数据为数值...")dev_features = tfidf.transform(dev_df['words'])(4) 进行模型预测与保存
Section titled “(4) 进行模型预测与保存”# 第四步:进行预测及保存print("进行预测...")dev_predictions = model.predict(dev_features)
# 保存预测结果print("保存预测结果...")output_df = pd.DataFrame({'words': dev_df['words'], 'predicted_label': dev_predictions})output_path = conf.model_predict_result + '/dev_predictions.csv'output_df.to_csv(output_path, index=False)print(f"预测结果已保存到 {output_path}")print("预测结果前5行:")print(output_df.head(5))2.5 模型预测
Section titled “2.5 模型预测”代码位置:
TMFCode\02-rf\rf_predict_fun.py导入包以及配置文件:
import jiebaimport pandas as pdimport picklefrom pyexpat import featuresfrom config import Configimport warningswarnings.filterwarnings('ignore')# 设置pandas显示选项pd.set_option('display.max_columns', None)进行单条原样本预测:
def predict(data): # 加载配置 conf = Config() # 第一步:加载保存的模型和向量化器 with open(conf.rf_model_save_path + '/rf_model.pkl', 'rb') as f: model = pickle.load(f) with open(conf.rf_model_save_path + '/tfidf_vectorizer.pkl', 'rb') as f: tfidf = pickle.load(f)
# 第二步:对输入数据进行切分 words=" ".join(jieba.lcut(data["text"])[:30])
# 第三步:对输入数据进行向量化 feature = tfidf.transform([words])
# 第四步:对输入数据进行预测 y_pred=model.predict(feature) # 第五步:转换预测结果,并进行返回预测结果 id2class={i:line.strip() for i,line in enumerate(open(conf.class_datapath,encoding='utf-8'))} data["pred_class"]=id2class[y_pred[0]] return data
# data={"text":"体验2D巅峰 倚天屠龙记十大创新概览"}# print(predict(data))输入日志:
{'text': '体验2D巅峰 倚天屠龙记十大创新概览', 'pred_class': 'game'}2.6 接口封装
Section titled “2.6 接口封装”工业界中的AI是指”能落地的AI”, 即指在生产环境中可以部署并提供在线, 或离线作业的模型.
- 例如:随机森林模型的在线服务地址(http://127.0.0.1:8001)
(1) 服务端
Section titled “(1) 服务端”代码位置:
TMFCode\02-rf\api.py导包及配置文件:
from flask import Flask, request, jsonifyimport jiebaimport pandas as pdimport picklefrom config import Configimport warningsfrom rf_predict_fun import predictwarnings.filterwarnings('ignore')pd.set_option('display.max_columns', None)构建flask应用: 注:requests 是一个简单易用的 HTTP 客户端工具,允许我们通过 Python 代码向服务器发送 HTTP 请求并处理响应。
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict_api(): # 获取 JSON 输入 data = request.get_json() if not data or 'text' not in data: return jsonify({'error': 'Missing text field in JSON'}), 400
# 调用预测函数 result = predict(data)
# 返回 JSON 结果 return jsonify(result)
if __name__ == '__main__': app.run(host='0.0.0.0', port=8001, debug=True)
(2) 客户端
Section titled “(2) 客户端”代码位置:
TMFCode\02-rf\api_test.py以下是通过代码进行接口的请求:
import requestsimport time
# 定义预测接口地址url = 'http://127.0.0.1:8001/predict'
# 构造请求数据data = {'text': "中国人民公安大学2012年硕士研究生目录及书目"}
# 记录开始时间start_time = time.time()
# 发送 POST 请求try: response = requests.post(url, json=data) # 计算耗时(毫秒) elapsed_time = (time.time() - start_time) * 1000 print(f"请求耗时: {elapsed_time:.2f} ms")
# 检查响应状态 if response.status_code == 200: result = response.json() print(f"预测结果: {result['pred_class']}") else: print(f"请求失败: {response.status_code}, {response.json()['error']}")except Exception as e: print(f"请求出错: {str(e)}")2.7 前端预测(streamlit)
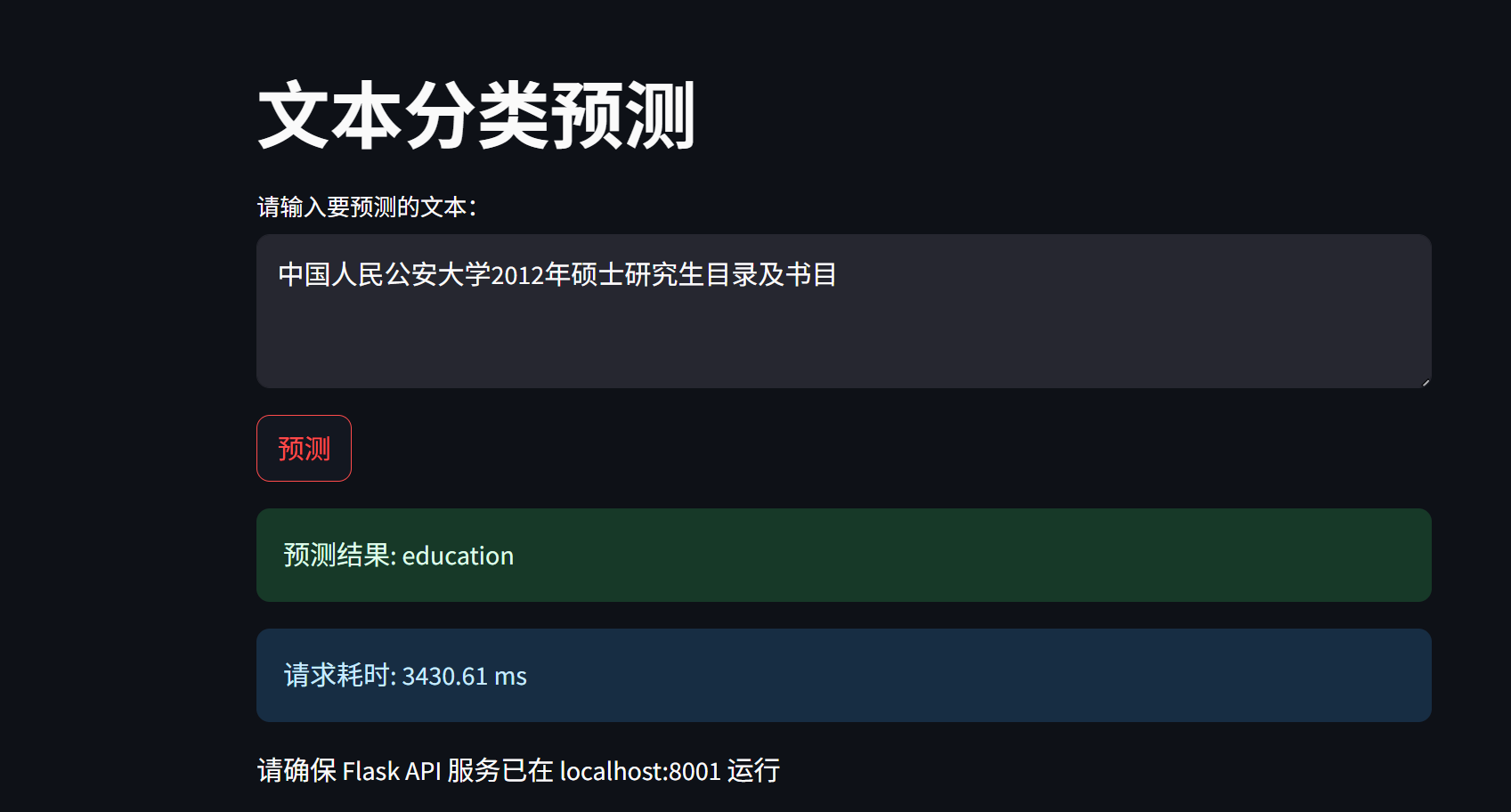
Section titled “2.7 前端预测(streamlit)”代码位置:
TMFCode\02-rf\app.py以下是前端测试接口的代码:
import streamlit as stimport requestsimport time
# 设置页面标题st.title("文本分类预测")
# 创建输入框text_input = st.text_area("请输入要预测的文本:", "中国人民公安大学2012年硕士研究生目录及书目")
# 创建预测按钮if st.button("预测"): # 构造请求数据 data = {'text': text_input} url = 'http://localhost:8001/predict'
# 记录开始时间 start_time = time.time()
try: # 发送 POST 请求 response = requests.post(url, json=data) # 计算耗时(毫秒) elapsed_time = (time.time() - start_time) * 1000
# 检查响应状态 if response.status_code == 200: result = response.json() st.success(f"预测结果: {result['pred_class']}") st.info(f"请求耗时: {elapsed_time:.2f} ms") else: st.error(f"请求失败: {response.json()['error']}") except Exception as e: st.error(f"请求出错: {str(e)}")
# 运行提示st.write("请确保 Flask API 服务已在 localhost:8001 运行")启动app前端:

使用实例:
(三) 本节小结
Section titled “(三) 本节小结”- 本小节完成了基于随机森林的基线模型,该模型以其可解释性强、性能稳定的特点为本次的项目奠定了一个基础。
- 本小节从数据处理到模型构建、训练、评估、部署、前端测试等完成了整个落地流程。