
数据集分析
发布于 2025-12-31
2.2 数据集分析
Section titled “2.2 数据集分析”学习目标
- 掌握对投满分项目数据集进行快速分析的代码实现.
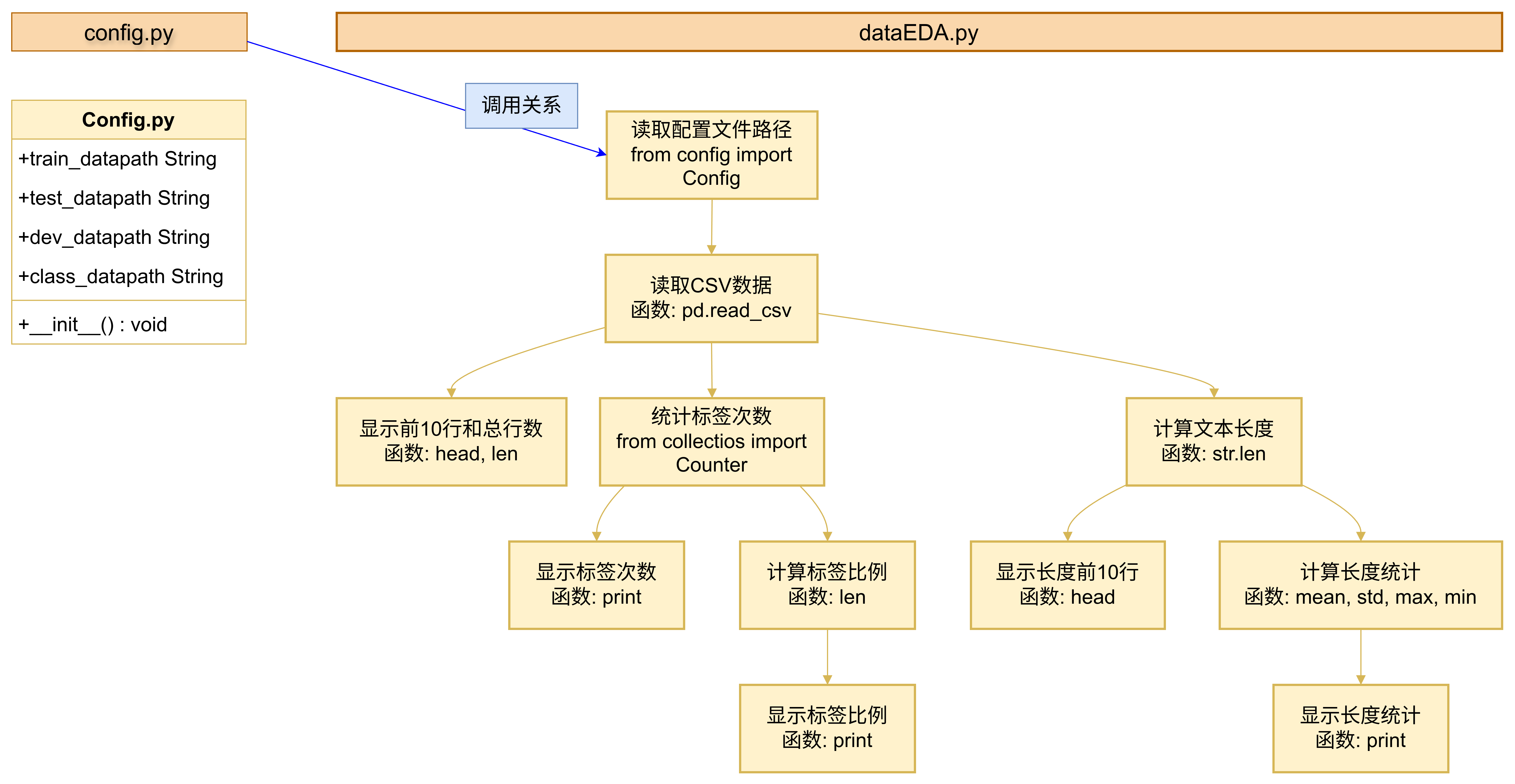
(一) 代码逻辑图
Section titled “(一) 代码逻辑图”数据及代码位置:TMFCode/01-data
本部分主要完成两个py脚本:config.py与dataEDA.py
(1)config.py:
在我们进入数据分析或者模型构建,通常我们会先实现一个配置文件config.py,方便我们对一些文件数据路径管理。这种方式在实际的生产环境中,非常常见,而不是直接将路径硬编码到我们的代码中。所以当我们拿到项目时候,先查看配置文件,并切换为自己对应的路径。
目的:方便我们的管理以及维护。
(2)dataEDA.py
探索性数据分析(Exploratory Data Analysis)代码,例如train.txt、test.tx或者相关数据文件的分析代码。前面我们整体已经知道train.txt主要为两列,一列是文本,一列是标签。我们可以分析以下指标:
-
训练等相关数据数据量
-
train.txt的类别样本是否均衡,类别占比情况
-
样本的文本大概是怎样的
-
…
(二) 代码实现
Section titled “(二) 代码实现”2.1 配置文件config.py
Section titled “2.1 配置文件config.py”config.py代码位置: TMFCode/01-data/config.py
import osclass Config(): def __init__(self): self.train_datapath="./train.txt" self.test_datapath="./test.txt" self.dev_datapath="./dev.txt" self.class_datapath="./class.txt"
if __name__ == '__main__': conf=Config() print(conf.train_datapath) print(conf.test_datapath)2.2 数据分析dataEDA.py
Section titled “2.2 数据分析dataEDA.py”代码位置:TMFCode/01-data/dataEDA.py
# 导入需要的工具import pandas as pd # 用于处理表格数据from collections import Counter # 用于统计标签from config import Config # 导入配置类
# 创建配置对象,获取数据文件路径config = Config()file_path = config.train_datapath # 默认使用训练数据文件 train.txt
# 第一步:读取数据并查看基本信息data = pd.read_csv(file_path, sep='\t', names=['text', 'label']) # 读取文件,列名为“文本”和“标签”print("前5行数据:")print(data.head(5)) # 显示前5行,了解数据长什么样print(f"总数据量:{len(data)} 行") # 显示总行数
# 第二步:统计标签分布label_counts = Counter(data['label']) # 数一数每个标签出现了几次print("\n标签分布:")for label, count in label_counts.items(): print(f"标签 {label}:{count} 次") # 输出每个标签的次数
# 第三步:计算标签比例total_rows = len(data) # 总行数print("\n标签比例:")for label, count in label_counts.items(): percent = (count / total_rows) * 100 # 计算百分比 print(f"标签 {label}:{percent:.2f}%") # 输出百分比,保留2位小数
# 第四步:分析文本长度data['text_length'] = data['text'].str.len() # 计算每条文本的字符数print("\n文本长度前10行:")print(data[['text', 'text_length']].head(10)) # 只显示文本和长度列print("\n文本长度统计:")print(f"平均长度:{data['text_length'].mean():.2f} 字符") # 平均值print(f"长度标准差:{data['text_length'].std():.2f} 字符") # 标准差print(f"最大长度:{data['text_length'].max()} 字符") # 最大值print(f"最小长度:{data['text_length'].min()} 字符") # 最小值(三) 本节小结
Section titled “(三) 本节小结”- 本小节给大家介绍是项目的数据分析逻辑与思路。
发布于 2025-12-31