
GPT模型介绍
5 GPT模型介绍
Section titled “5 GPT模型介绍”- 了解什么是GPT
- 掌握GPT的架构
- 掌握GPT的预训练任务
5.1 GPT简介
Section titled “5.1 GPT简介”GPT(Generative Pre-trained Transformer)是 OpenAI 提出的 基于 Transformer 的自回归(Autoregressive)生成模型。它采用 无监督预训练 + 有监督微调 的方式,适用于 自然语言理解(NLU) 和 自然语言生成(NLG) 任务。
- OpenAI在论文<< Improving Language Understanding by Generative Pre-Training >>中提出GPT模型
- OpenAI后续又在论文<< Language Models are Unsupervised Multitask Learners >>中提出GPT2模型
- GPT和GPT2模型结构差别不大, 但是GPT2采用了更大的数据集进行训练
OpenAI GPT模型是在Google BERT模型之前提出的, 与BERT最大的区别在于GPT采用了传统的语言模型方法进行预训练, 即使用单词的上文来预测单词, 而BERT是采用了双向上下文的信息共同来预测单词。正是因为训练方法上的区别, 使得GPT更擅长处理自然语言生成任务(NLG), 而BERT更擅长处理自然语言理解任务(NLU)。
GPT发展经历了多个版本的优化:
| 版本 | 发布时间 | 参数规模 | 优化点 |
|---|---|---|---|
| GPT-1 | 2018 | 1.17亿 | 采用 标准 Transformer 解码器 结构,使用 BookCorpus 进行预训练。 |
| GPT-2 | 2019 | 15亿-175亿 | 引入更大规模数据(WebText),优化 文本生成质量,但无微调机制。 |
| GPT-3 | 2020 | 1750亿 | Few-shot / Zero-shot / One-shot 能力增强,支持 多任务泛化。 |
| GPT-4 | 2023 | 规模未知 | 增强推理能力,引入多模态(文本 + 图像),更长上下文窗口。 |
5.2 GPT架构
Section titled “5.2 GPT架构”GPT主要基于 Transformer 解码器(Decoder-only),整体架构如下:
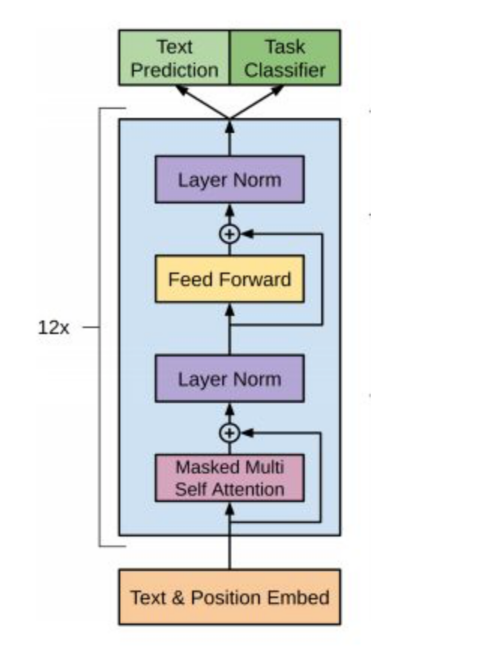
GPT由词嵌入(Embedding)、多层Transformer解码器、输出层 组成:
1️⃣ 输入嵌入(Token Embeddings):
- 使用 Byte-Pair Encoding(BPE) 进行子词分词,将文本转换为 token。
- 通过 词嵌入矩阵 将 token 映射为固定维度的向量。
2️⃣ 位置编码(Positional Encoding):
- GPT 使用 可训练的位置嵌入(Learnable Positional Embeddings),不像 BERT 采用固定三角函数编码。
3️⃣ 多层 Transformer 解码器(Multi-layer Decoder):
- 由多个 自注意力(Self-Attention)、前馈神经网络(FFN)、残差连接(Residual Connections) 组成。
- Masked Self-Attention 机制,确保每个 token 只能看到 之前的 token,防止未来信息泄露。
4️⃣ 输出层(Output Layer):
- 经过线性变换 + Softmax计算概率分布,生成下一个token。
看三个语言模型的对比架构图, 中间的就是GPT:
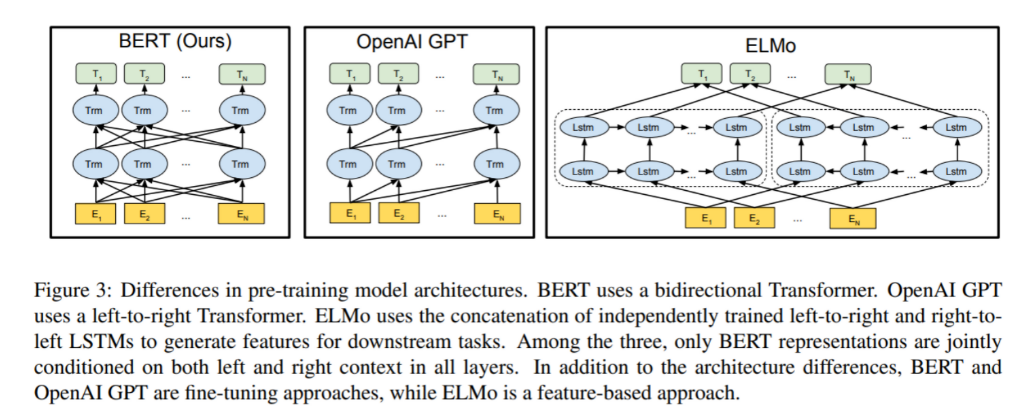
从上图可以很清楚的看到GPT采用的是单向Transformer模型, 例如给定一个句子[u1, u2, …, un], GPT在预测单词ui的时候只会利用[u1, u2, …, u(i-1)]的信息, 而BERT会同时利用上下文的信息[u1, u2, …, u(i-1), u(i+1), …, un]。
作为两大模型的直接对比, BERT采用了Transformer的Encoder模块, 而GPT采用了Transformer的Decoder模块。并且GPT的Decoder Block和经典Transformer Decoder Block还有所不同, 如下图所示:
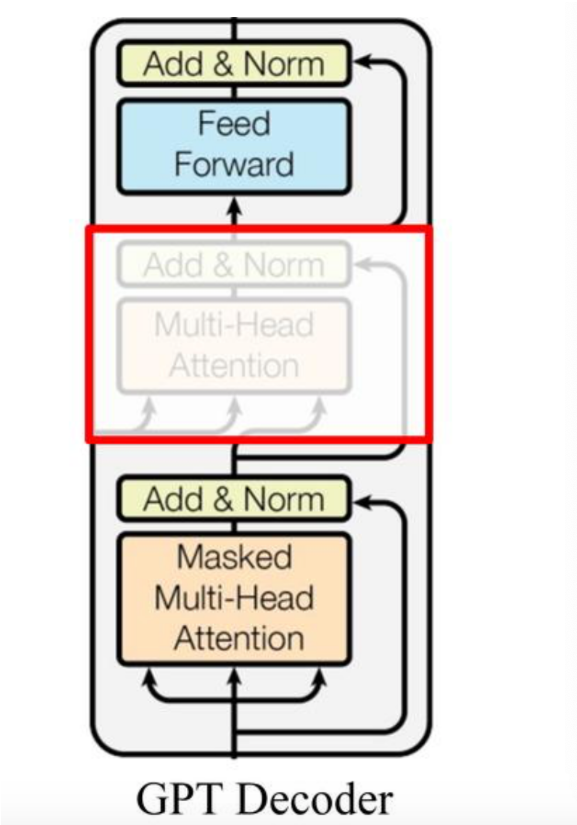
如上图所示, 经典的Transformer Decoder Block包含3个子层, 分别是Masked Multi-Head Attention层, encoder-decoder attention层, 以及Feed Forward层。但是在GPT中取消了第二个encoder-decoder attention子层, 只保留Masked Multi-Head Attention层, 和Feed Forward层。
作为单向Transformer Decoder模型, GPT利用句子序列信息预测下一个单词的时候, 要使用Masked Multi-Head Attention对单词的下文进行遮掩(look ahead mask), 来防止未来信息的提前泄露。例如给定一个句子包含4个单词[A, B, C, D], GPT需要用[A]预测B, 用[A, B]预测C, 用[A, B, C]预测D。很显然的就是当要预测B时, 需要将[B, C, D]遮掩起来。
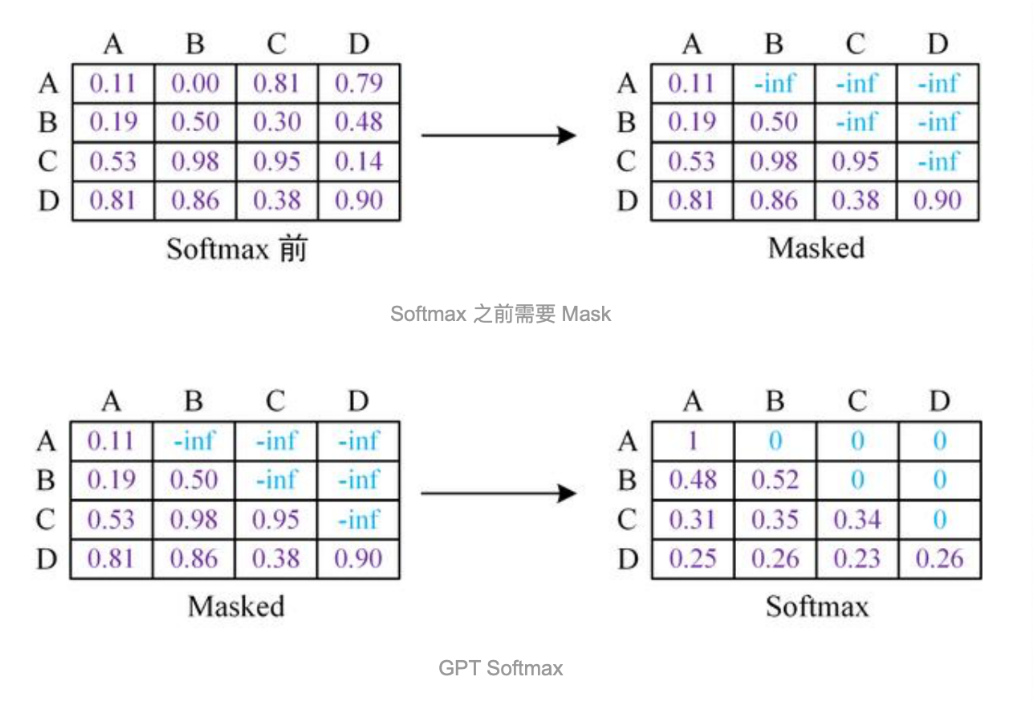
具体的遮掩操作是在slef-attention进行softmax之前进行的, 一般的实现是将MASK的位置用一个无穷小的数值-inf来替换, 替换后执行softmax计算得到新的结果矩阵,这样-inf的位置就变成了0。如上图所示, 最后的矩阵可以很方便的做到当利用A预测B的时候, 只能看到A的信息; 当利用[A, B]预测C的时候, 只能看到A, B的信息。
注意:对比于经典的Transformer架构, 解码器模块采用了6个Decoder Block; GPT的架构中采用了12个Decoder Block。
5.3 GPT训练过程
Section titled “5.3 GPT训练过程”GPT的训练也是典型的两阶段过程:
- 第一阶段: 无监督的预训练语言模型
- 第二阶段: 有监督的下游任务fine-tunning
5.3.1 无监督的预训练语言模型
Section titled “5.3.1 无监督的预训练语言模型”给定句子U = [u1, u2, …, un], GPT训练语言模型时的目标是最大化下面的似然函数:
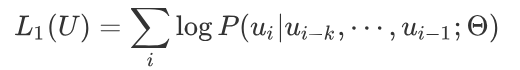
其中,\(u_i\)是第\(i\)个单词,\(Θ\)是模型参数。
有上述公式可知, GPT是一个单向语言模型, 假设输入张量用\(h_0\)表示, 则计算公式如下:
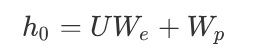
其中\(W_p\)是单词的位置编码, \(W_e\)是单词本身的word embedding,\(W_p\)的形状是[max_seq_len, embedding_dim],\(W_e\)的形状是[vocab_size, embedding_dim]。
得到输入张量\(h_0\)后, 要将\(h_0\)传入GPT的Decoder Block中, 依次得到\(h_t\):
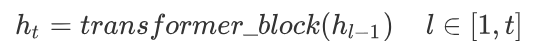
最后通过得到的\(h_t\)来预测下一个单词:
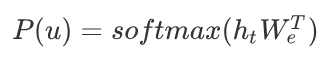
5.3.2 有监督的下游任务fine-tunning
Section titled “5.3.2 有监督的下游任务fine-tunning”GPT经过预训练后, 会针对具体的下游任务对模型进行微调. 微调采用的是有监督学习, 训练样本包括单词序列[x1, x2, …, xn]和label y。GPT微调的目标任务是根据单词序列[x1, x2, …, xn]预测标签y。
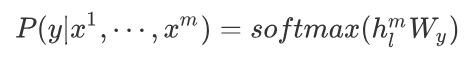
其中\(W_y\)表示预测输出的矩阵参数, 微调任务的目标是最大化下面的函数:
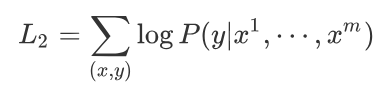
综合两个阶段的目标任务函数, 可知GPT的最终优化函数为:
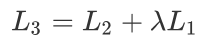
其中,\(L_2\) 是任务特定的损失函数,\(L_1\) 是语言模型的损失函数,\(λ\) 是权重系数。
5.4 小结
Section titled “5.4 小结”- 什么是GPT
- GPT是OpenAI 提出的基于Transformer的自回归(Autoregressive)生成模型
- 本质上来说, GPT是一个单向语言模型
- GPT的架构
- GPT采用了Transformer架构中的解码器模块
- GPT在使用解码器模块时做了一定的改造, 将传统的3层Decoder Block变成了2层Block, 删除了encoder-decoder attention子层, 只保留Masked Multi-Head Attention子层和Feed Forward子层
- GPT的解码器总共是由12个改造后的Decoder Block组成的
- GPT的预训练任务
- 第一阶段: 无监督的预训练语言模型,只利用单词前面的信息来预测当前单词
- 第二阶段: 有监督的下游任务fine-tunning