
fasttext模型
3.2 FastText 模型
Section titled “3.2 FastText 模型”学习目标
-
利用FastText模型实现投满分项目的模型构建.
-
对FastText模型进行评估、优化
-
对FastText进行模型部署与上线测试
Tips:
前面我们已经完成了基线模型RandomForest一个实现,但是当前场景着对分类指标、泛化能力和处理复杂语义需求相对较高的,所以我们需要引入更为先进自然语言处理技术,包括FastText、BERT以及大语言模型LLMs,核心是这些模型在学术以及工业都有不错的性能表现,所以这里我们会进行整体技术实现以及评估,来最终获得符合当前场景需求的具体技术解决方案。
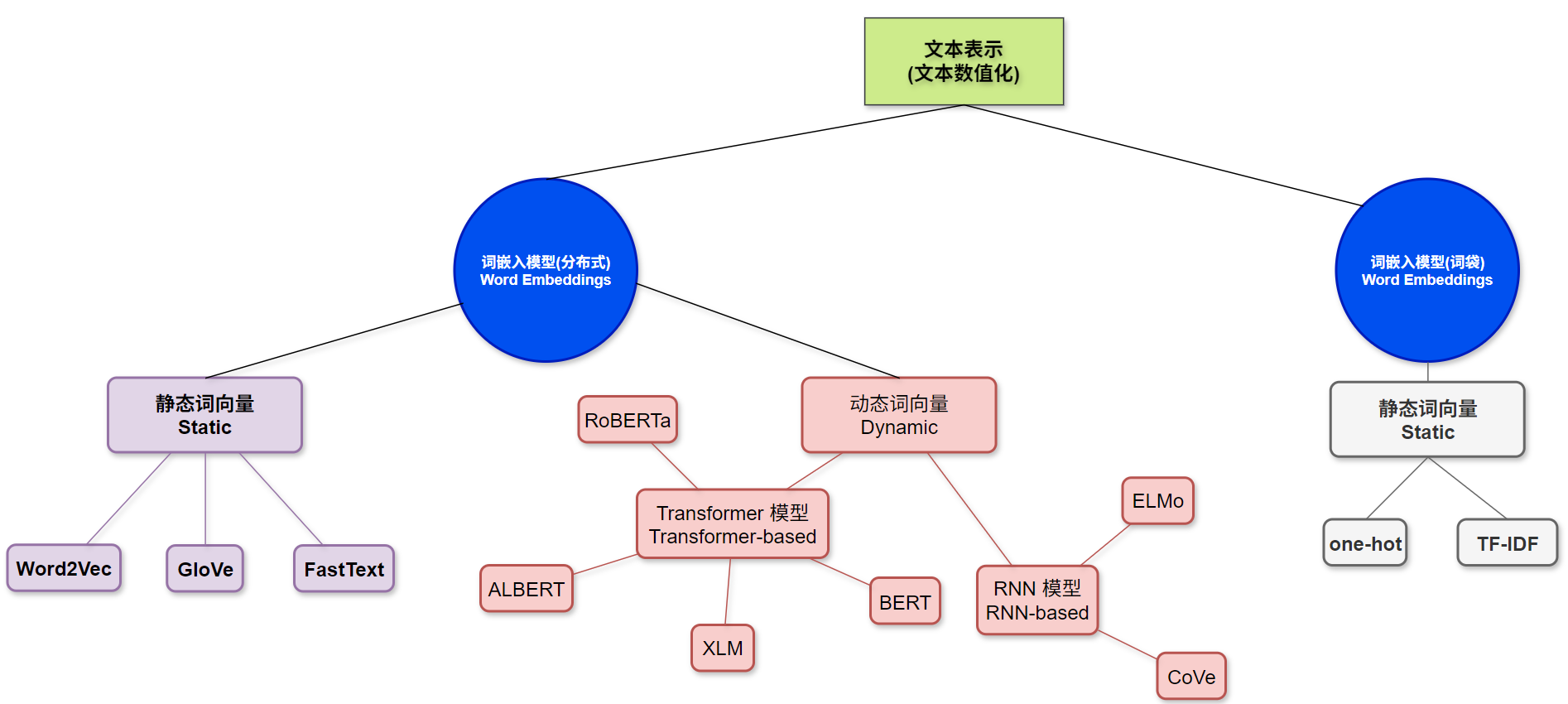
(一) 代码结构图
Section titled “(一) 代码结构图”代码位置:

基于FastText分类建模思路:
① 对数据train.txt等相关文件的文本列进行 分词处理,两种处理思路字符级别以及词级别。
② 利用FastText库进行建模、评估与保存。
-
02-fasttext_char_1_default.py -
02-fasttext_char_2_auto.py -
02-fasttext_word_1_default.py -
02-fasttext_word_2_auto.py
③ 模型预测
④ 模型部署,提供api接口
⑤ 前端预测实现
(二) 代码实现
Section titled “(二) 代码实现”2.1 config配置文件
Section titled “2.1 config配置文件”代码位置:TMFCode\02-rf\config.py
import osclass Config(object): def __init__(self): #原始数据路径 self.train_datapath="../01-data/train.txt" self.test_datapath = "../01-data/test.txt" self.dev_datapath = "../01-data/dev.txt"
#模型路径 self.ft_model_save_path="./save_models"
#样本类别文件 self.class_datapath="../01-data/class.txt"
#处理完的数据(用于训练) self.final_data="./final_data"
if __name__ == '__main__': conf=Config() print(conf.ft_model_save_path) print(conf.train_datapath)2.2 data_preprocess数据处理
Section titled “2.2 data_preprocess数据处理”代码位置:
03-fasttext\01-data_preprocess.pyfastText数据处理背景:
FastText 是一个开源、免费、轻量级的库,允许用户学习文本表示和文本分类器。它适用于标准的通用硬件。模型稍后可以缩小,甚至适合移动设备。
FastText最初训练语料是英文,英文天然支持每个单词之间是有空格的,所以中文相较英文语料的文本分类任务或者词嵌入都会多一步分词。最终的训练数据需要构建成如下格式,构建思路来自官方的数据样例(https://dl.fbaipublicfiles.com/fasttext/data/cooking.stackexchange.tar.gz):
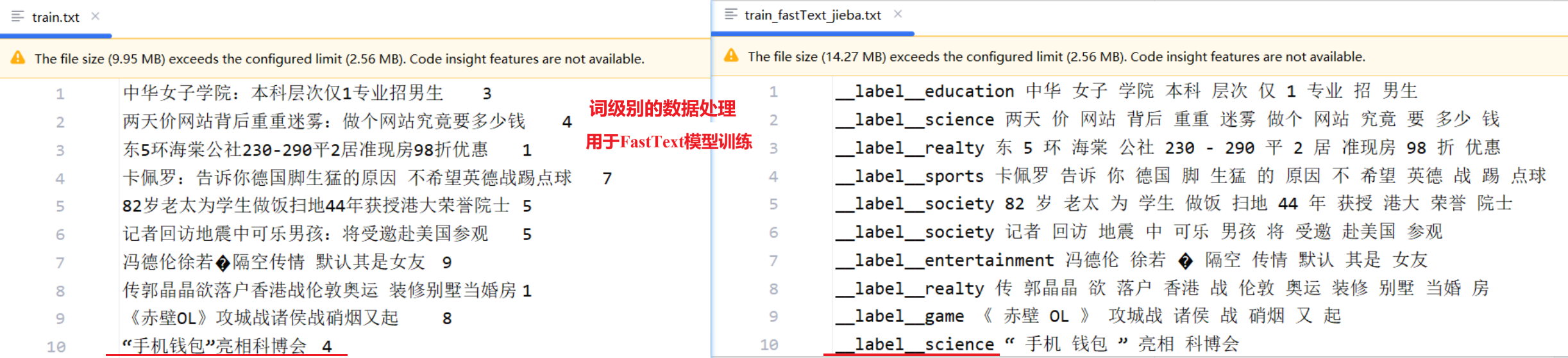
单字符级别分字处理
原始样本:三羊资产清盘事起ITAT 0 处理后样本:
__label__finance 三 羊 资 产 清 盘 事 起 I T A T词级别分词处理
原始样本:三羊资产清盘事起ITAT 0 处理后样本:
__label__finance 三羊 资产 清盘 事起 ITAT训练样本示例(验证、测试样本同训练样本一样):
导入工具包及初始化配置:
import jiebafrom config import *conf=Config()(1) 加载原始文件数据路径
Section titled “(1) 加载原始文件数据路径”在实际构建训练数据,可以看到我们的label需要将类别数字映射为分类类别,所以需要加载文件路径:
- train.txt | test.txt |dev.txt | class.txt
# 步骤 1:检查文件存在性class_file = conf.class_datapathdata_file = conf.train_datapath# data_file = conf.dev_datapath# data_file = conf.test_datapath
if not os.path.exists(class_file) or not os.path.exists(data_file): print("类别文件及原始数据路径:", class_file, data_file) print("文件不存在,请检查文件是否存在!")(2) 设置预处理后文件保存路径
Section titled “(2) 设置预处理后文件保存路径”# 步骤 2:设置预处理后文件保存路径#是否使用字符分词use_char_segmentation = Trueif use_char_segmentation==True: #文件写入路径 if "train" in data_file: output_file = conf.final_data+'/train_fastText_char.txt' elif "test" in data_file: output_file = conf.final_data+'/test_fastText_char.txt' else: output_file = conf.final_data+'/dev_fastText_char.txt'else: if "train" in data_file: output_file = conf.final_data+'/train_fastText_jieba.txt' elif "test" in data_file: output_file = conf.final_data+'/test_fastText_jieba.txt' else: output_file = conf.final_data+'/dev_fastText_jieba.txt'(3) ID 到类别名的映射
Section titled “(3) ID 到类别名的映射”-
读取类别class.txt,生成ID到类别名的映射字典
-
映射字典:
{0: 'finance', 1: 'realty', 2: 'stocks', 3: 'education', 4: 'science', 5: 'society', 6: 'politics', 7: 'sports', 8: 'game', 9: 'entertainment'}id2name = {}print("类别文件:", class_file)
with open(class_file, 'r', encoding='utf-8') as f: for idx, line in enumerate(f): id2name[idx] = line.strip() # 去除换行符,映射索引到类别名
print("类别映射:", id2name)(4) FastText训练数据构造
Section titled “(4) FastText训练数据构造”datas = []with open(data_file, 'r', encoding='utf-8') as f: for line in f: line = line.strip() # 去除换行符和空白 if not line: continue # 跳过空行
text, label = line.split('\t') # 以制表符分割 label_name = f"__label__{id2name[int(label)]}" # 转换标签,如 __label__education text = text.replace(':', '') # 部分文本含有冒号,这里移除冒号 # use_char_segmentation为 True,则是字符级分词;为False,则是jieba 词级分词 words = list(text) if use_char_segmentation else jieba.cut(text) # 字符分词或词级分词 text_processed = ' '.join(word for word in words if word.strip()) # 拼接分词结果
fasttext_line = f"{label_name} {text_processed}" datas.append(fasttext_line) # 添加到列表(5) 预处理后数据保存
Section titled “(5) 预处理后数据保存”with open(output_file, 'w', encoding='utf-8') as f: for line in datas: f.write(line + '\n') # 写入每行print("前 5 行:", datas[:5])print(f"数据已保存到 {output_file}")运行日志:
C:\python.exe C:\TMFCode\03-fasttext\01-data_preprocess.py类别文件: C:\TMFCode\01-data\class.txt类别映射: {0: 'finance', 1: 'realty', 2: 'stocks', 3: 'education', 4: 'science', 5: 'society', 6: 'politics', 7: 'sports', 8: 'game', 9: 'entertainment'}前 5 行: ['__label__education 中 华 女 子 学 院 本 科 层 次 仅 1 专 业 招 男 生', '__label__science 两 天 价 网 站 背 后 重 重 迷 雾 做 个 网 站 究 竟 要 多 少 钱', '__label__realty 东 5 环 海 棠 公 社 2 3 0 - 2 9 0 平 2 居 准 现 房 9 8 折 优 惠', '__label__sports 卡 佩 罗 告 诉 你 德 国 脚 生 猛 的 原 因 不 希 望 英 德 战 踢 点 球', '__label__society 8 2 岁 老 太 为 学 生 做 饭 扫 地 4 4 年 获 授 港 大 荣 誉 院 士']数据已保存到 C:\TMFCode\03-fasttext\final_data/train_fastText_char.txt
Process finished with exit code 02.3 FastText字符级别建模
Section titled “2.3 FastText字符级别建模”(1) 默认参数训练
Section titled “(1) 默认参数训练”代码位置:
TMFCode\03-fasttext\02-fasttext_char_1_default.py字符级别建模(默认参数进行训练)
FastText模型构建之后,选择的配置参数非常多,当前的fasttext_char_1_default.py我们只设置训练数据路径,所有的其他参数的值都采用默认。
# 导入工具包import fasttext # pip install fasttext-wheelfrom config import Configimport datetime
# 获取时间current_time = datetime.datetime.now().date().today().strftime("%Y%m%d")conf = Config()
# 1、模型训练model = fasttext.train_supervised(input='final_data/train_fastText_char.txt')# 2、模型保存path = conf.ft_model_save_pathmodel.save_model(path + f"\\fastText_char_default_{str(current_time)}.bin")
# 3、模型预测print(model.predict("《 赤 壁 O L 》 攻 城 战 诸 侯 战 硝 烟 又 起"))
# 4、模型词表查看print(f"*查看模型词表[:10]:{model.words[:10]}")## 单词向量表示# print(f"单词的向量:{model.get_word_vector(model.words[:9][1])}")# print(f"单词的向量:{model.get_word_vector('中')}")## 预测最接近的单词print(f"*预测最接近的单词:{model.get_nearest_neighbors('中')}")
# 5、查看模型子词,上述训练未开启子词,所以这里查到还是词本身print(f"*模型字词:{model.get_subwords('你')}")
# 6、模型测试评估res = model.test('./final_data/test_fastText_char.txt')# 参考官方说明:https://fasttext.cc/docs/en/supervised-tutorial.html# (10000, 0.8761, 0.8761) 样本量 精确率 召回率print(res)输出日志:
C:\python.exe C:\TMFCode\03-fasttext\02-fasttext_char_1_default.pyRead 3M wordsNumber of words: 4758Number of labels: 10Progress: 100.0% words/sec/thread: 1091510 lr: 0.000000 avg.loss: 0.488831 ETA: 0h 0m 0s(('__label__game',), array([0.99980789]))*查看模型词表[:10]:['</s>', '0', '1', '2', '大', '国', '图', '(', ')', '3']*预测最接近的单词:[(0.8841610550880432, '二'), (0.8817741870880127, '跻'), (0.880586564540863, '宁'), (0.861633837223053, '东'), (0.8588536381721497, '缺'), (0.8508040904998779, '降'), (0.8485209941864014, '9'), (0.8371592164039612, '肘'), (0.8367257714271545, '佛'), (0.8290629982948303, '津')]*模型字词:(['你'], array([588]))(10000, 0.8761, 0.8761)
Process finished with exit code 0结论: 采用字符为单位的模型效果精准率和召回率都达到了87.61%, 相比于前面的随机森林实验的82.47%提升了大概5个多百分点。
(2) auto自动调参优化
Section titled “(2) auto自动调参优化”代码位置:
TMFCode\03-fasttext\02-fasttext_char_2_auto.py字符级别建模(采用auto自动调参进行训练)
FastText模型构建之后,选择的配置参数非常多,当前的fasttext_char_1_auto.py我们设置训练数据路径,并启用auto方式进行自动调参,注意自动调参需要增加验证集的设置。
以下是相关参数说明:
# 导入工具包import fasttextfrom config import Configimport datetimeimport randomimport numpy as npimport os
# 获取当前日期current_time = datetime.datetime.now().date().today().strftime("%Y%m%d")
# 1. 导入配置文件conf = Config()
# 2. 模型训练model = fasttext.train_supervised( input='./final_data/train_fastText_char.txt', autotuneValidationFile='./final_data/dev_fastText_char.txt', autotuneDuration=60, # 搜索的时间 默认300s thread=1, # 单线程,确保可复现性 verbose=3 # 输出调参过程)
# 3. 模型保存path = conf.ft_model_save_pathmodel_save_path = path + f"\\fastText_char_auto_{str(current_time)}.bin"model.save_model(model_save_path)print(f"模型已保存至: {model_save_path}")
# 4. 模型预测sentence = "俄 达 吉 斯 坦 共 和 国 一 名 区 长 被 枪 杀"pred_label, pred_prob = model.predict(sentence)print(f"预测结果: 标签={pred_label[0]}, 概率={pred_prob[0]:.4f}")
# 5. 查看模型子词word = "好"subwords, subword_ids = model.get_subwords(word)print(f"*词'{word}'的子词:{subwords}")print(f"*子词ID:{subword_ids}")
# 获取词向量维度print(f'*词向量维度:{model.get_dimension()}')
# 6. 模型测试评估res = model.test('./final_data/test_fastText_char.txt')# 参考官方说明:https://fasttext.cc/docs/en/supervised-tutorial.htmlprint(f"测试结果: 样本数={res[0]}, 精确率={res[1]:.4f}, 召回率={res[2]:.4f}")输出日志:(日志中是score是值精确率)
Trial = 1epoch = 5lr = 0.1dim = 100minCount = 1wordNgrams = 1minn = 0maxn = 0bucket = 0dsub = 2loss = softmaxProgress: 5.1% Trials: 1 Best score: unknown ETA: 0h 0m56scurrentScore = 0.876712...........Best selected args = 0epoch = 1lr = 1.80525dim = 641minCount = 1wordNgrams = 4minn = 0maxn = 0bucket = 2620593dsub = 2loss = softmaxTraining again with best argumentsRead 3M wordsNumber of words: 4758Number of labels: 10Progress: 100.0% words/sec/thread: 366609 lr: 0.000000 avg.loss: 0.446916 ETA: 0h 0m 0s模型已保存至: ./save_models\fastText_char_auto_20250630.bin预测结果: 标签=__label__politics, 概率=0.9996*词'好'的子词:['好']*子词ID:[274]*词向量维度:641测试结果: 样本数=10000, 精确率=0.9165, 召回率=0.9165结论: 采用字符为单位的模型效果精准率和召回率都达到了91.65%, 相比于前面的随机森林实验82.47%,指标提升了大概9个多百分点。
2.4 FastText词级别建模(default)
Section titled “2.4 FastText词级别建模(default)”(1) 默认参数训练
Section titled “(1) 默认参数训练”代码位置:
TMFCode\03-fasttext\02-fasttext_word_1_default.py字符级别建模(默认参数进行训练)
FastText模型构建之后,选择的配置参数非常多,当前的fasttext_word_1_default.py我们只设置训练数据路径,所有的其他参数的值都采用默认。
# 导入工具包import fasttextfrom config import Configimport datetime
#获取时间current_time=datetime.datetime.now().date().today().strftime("%Y%m%d")#1、导入配置文件conf=Config()
# 2、模型训练model = fasttext.train_supervised( #无监督情况下 wordNgrams等同于word2vec input = './final_data/train_fastText_jieba.txt',)
#3、模型保存path=conf.ft_model_save_pathmodel.save_model(path+f"\\fastText_jieba_default_{str(current_time)}.bin")
#4、模型预测print(model.predict("名师 详解 考研 复试 英语听力 备考 策略"))
# 4、模型词表查看# print(model.words)# print(len(model.words))
# 6、查看模型子词,上述训练未开启子词,所以这里查到还是词本身print(model.get_subwords('你好'))
# 7、模型测试print("模型测试验证评估开始...")res =model.test('./final_data/test_fastText_jieba.txt')print(res)输出日志:
C:\python.exe C:\TMFCode\03-fasttext\02-fasttext_word_1_default.pyRead 2M wordsNumber of words: 118853Number of labels: 10Progress: 100.0% words/sec/thread: 778955 lr: 0.000000 avg.loss: 0.327306 ETA: 0h 0m 0s(('__label__education',), array([1.00001001]))(['你好'], array([18799]))模型测试验证评估开始...(10000, 0.9079, 0.9079)
Process finished with exit code 0结论: 采用单词为单位的默认参数建模的模型效果精准率和召回率都达到了90.97%, 相比于前面的字符级默认参数实验提升3个多百分点、及随机森林提升了大概8个多百分点。但是,相较字符级别的自动调参,下降了0.68个百分点,放弃该方案。
(2) auto自动调参优化
Section titled “(2) auto自动调参优化”代码位置:
TMFCode\03-fasttext\02-fasttext_word_2_auto.py字符级别建模(采用auto自动调参进行训练)
FastText模型构建之后,选择的配置参数非常多,当前的fasttext_word_2_auto.py我们设置训练数据路径,并启用auto方式进行自动调参,注意自动调参需要增加验证集的设置。
# 导入工具包import fasttextfrom config import Configimport datetime
# 获取当前日期current_time = datetime.datetime.now().date().today().strftime("%Y%m%d")
# 1. 导入配置文件conf = Config()
# 2. 模型训练model = fasttext.train_supervised( input='./final_data/train_fastText_word.txt', autotuneValidationFile='./final_data/dev_fastText_word.txt', autotuneDuration=60, # autotuneModelSize='2M', # 目标模型大小 2MB(触发量化) thread=1, # 单线程,确保可复现性 verbose=3 # 输出调参过程)
# 3. 模型保存path = conf.ft_model_save_pathmodel_save_path = path + f"\\fastText_word_auto_{str(current_time)}.bin"model.save_model(model_save_path)print(f"模型已保存至: {model_save_path}")
# 4. 模型预测sentence = "俄 达吉斯坦 共和国 一名 区长 被 枪杀"pred_label, pred_prob = model.predict(sentence)print(f"预测结果: 标签={pred_label[0]}, 概率={pred_prob[0]:.4f}")
# 5. 查看模型子词word = "你好"subwords, subword_ids = model.get_subwords(word)print(f"*词'{word}'的子词: {subwords}")print(f"*子词ID: {subword_ids}")
# 获取词向量维度print(f"*词向量维度:{model.get_dimension()}")
# 6. 模型测试res = model.test('./final_data/test_fastText_word.txt')print(f"测试结果: 样本数={res[0]}, 精确率={res[1]:.4f}, 召回率={res[2]:.4f}")输出日志:
C:\python.exe C:\TMFCode\03-fasttext\02-fasttext_word_2_auto.pyTrial = 1epoch = 5lr = 0.1dim = 100minCount = 1wordNgrams = 1minn = 0maxn = 0bucket = 0dsub = 2loss = softmaxProgress: 5.9% Trials: 1 Best score: unknown ETA: 0h 0m56scurrentScore = 0.8979...........Training again with best argumentsBest selected args = 0epoch = 5lr = 0.1dim = 100minCount = 1wordNgrams = 1minn = 0maxn = 0bucket = 0dsub = 2loss = softmaxRead 2M wordsNumber of words: 118853Number of labels: 10Progress: 100.0% words/sec/thread: 3068874 lr: 0.000000 avg.loss: 0.247995 ETA: 0h 0m 0s模型已保存至: ./save_models\fastText_word_auto_20250630.bin预测结果: 标签=__label__politics, 概率=0.9995*词'你好'的子词: ['你好']*子词ID: [18799]*词向量维度:100测试结果: 样本数=10000, 精确率=0.9041, 召回率=0.9041结论: 采用词为单位的自动调参的模型效果精准率和召回率都达到了90.41%, 相较前面最好的字符级自动调参的模型91.65%,指标下降了1.25个百分点,放弃该方案。
2.5 模型预测
Section titled “2.5 模型预测”这里我们先实现离线预测,完成predict函数
# 模型预测import fasttextimport jiebaimport warningswarnings.filterwarnings('ignore')#1、加载模型model = fasttext.load_model('save_models/fastText_char_default_20250630.bin')#2、定义预测函数def predict(data): #获取text进行进行字符级别分词 words=" ".join(list(data["text"])) #模型预测 res=model.predict(words) #截取 预测返回值 pred_label=res[0][0][9:] #封装结果并返回 data["pred_class"]=pred_label return data
data = {"text": "中华女子学院:本科层次仅1专业招男生"}print(predict(data))2.6 模型部署(Flask)
Section titled “2.6 模型部署(Flask)”(1) 服务端
Section titled “(1) 服务端”本次对FastText这个基于词级别的自动调参模型,进行部署,核心是强化大家理解整个建模到对外提供服务的整个流程。
- 第一步: 编写主服务逻辑代码.
- 第二步: 启动Flask服务. (http://127.0.0.1:8003)
代码位置:
TMFCode\03-fasttext\api.py# 模型预测import fasttextimport jiebafrom predict_fun import predictfrom flask import Flask, request,jsonify
app = Flask(__name__)
@app.route('/predict', methods=['POST'])def main_server(): # 获取请求数据 data = request.get_json() #预测 print("-------------预测结果------------") result=predict(data) print(result)
return jsonify(result)
if __name__ == '__main__': app.run(host='0.0.0.0',port=8003)输出日志:
C:\python.exe C:\TMFCode\03-fasttext\api.pyWarning : `load_model` does not return WordVectorModel or SupervisedModel any more, but a `FastText` object which is very similar. * Serving Flask app 'api' * Debug mode: offWARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Running on all addresses (0.0.0.0) * Running on http://127.0.0.1:8003 * Running on http://26.26.26.1:8003Press CTRL+C to quitBuilding prefix dict from the default dictionary ...Dumping model to file cache C:\Users\AppData\Local\Temp\jieba.cacheLoading model cost 0.329 seconds.(2) 客户端
Section titled “(2) 客户端”代码位置:
TMFCode\03-fasttext\api_test.pyimport requestsimport time
# 定义预测接口地址url = 'http://127.0.0.1:8003/predict'
# 构造请求数据data = {'text': "中国人民公安大学2012年硕士研究生目录及书目"}
# 记录开始时间start_time = time.time()# 发送 POST 请求try: response = requests.post(url, json=data) # 计算耗时(毫秒) elapsed_time = (time.time() - start_time) * 1000 print(f"请求耗时: {elapsed_time:.2f} ms")
# 检查响应状态 if response.status_code == 200: result = response.json() print(f"预测结果: {result['pred_class']}") else: print(f"请求失败: {response.status_code}, {response.json()['error']}")except Exception as e: print(f"请求出错: {str(e)}")输出日志:
C:\python.exe C:\TMFCode\03-fasttext\api_test.py输入文本: 公共英语(PETS)写作中常见的逻辑词汇汇总分类结果: education单条样本预测的耗时: 4.9 ms(三) 本节小结
Section titled “(三) 本节小结”- 本小节主要完成了FastText模型训练以及优化,其中包括数据处理、模型训练、模型评估以及模型部署及调用等。
- 目前模型指标对比