
文本数据分析
4 文本数据分析
Section titled “4 文本数据分析”- 了解文本数据分析的作用
- 掌握常用的几种文本数据分析方法
4.1 文本数据分析介绍
Section titled “4.1 文本数据分析介绍”- 概念
文本数据分析,也称为文本挖掘或文本分析,是指**从非结构化的文本数据中提取有价值的信息、模式和见解的过程。**随着互联网和社交媒体的快速发展,文本数据变得越来越丰富,掌握文本数据分析技术对于许多领域都至关重要。
- 作用
文本数据分析能够有效帮助我们理解数据语料,快速检查出语料可能存在的问题,并指导之后模型训练过程中一些超参数的选择。
-
文本数据分析方法
-
标签数量分布:指在分类问题中,各个类别标签所对应的样本数量的分布情况。
- 了解数据集中各类别的平衡性:检查数据集中是否存在类别不平衡的问题,也就是某些类别的样本数量远远多于其他类别。
- 指导模型训练:类别不平衡可能会导致模型倾向于预测样本数量较多的类别,从而影响模型的泛化能力。
- 选择合适的评估指标:如果类别不平衡,可能需要选择更适合不平衡数据的评估指标,例如 F1-score、Precision-Recall 曲线等。
- 指导数据增强或重采样:如果类别不平衡严重,可以考虑使用数据增强或重采样技术来平衡各类别样本数量。
-
句子长度分布:指数据集中各个句子的长度(通常以词语数量来衡量)的分布情况。
- 了解文本数据的特征:可以了解数据集中句子的长短特征,例如句子是短语形式还是长篇段落。
- 指导模型输入长度设置:对于需要固定输入长度的深度学习模型,需要根据句子长度分布来设置合适的输入长度。
- 指导预处理:可以根据句子长度分布来决定是否进行截断或填充等预处理操作。
- 发现异常值:某些极短或极长的句子可能是异常值,需要进行处理。
-
词频统计:指统计文本数据集中每个词语出现的频率。
- 了解文本数据的关键词:可以找出文本中最常用的词语,从而了解文本的主题和内容。
- 过滤停用词:找出高频停用词,以便在预处理过程中删除。
- 选择特征:词频可以作为一种特征,用于文本分类、信息检索等任务。
- 可视化关键词:可以将词频以词云的形式进行可视化。
-
关键词词云:一种可视化技术,以图形化的方式展示文本中词语的频率,通常频率越高的词语显示得越大。
- 直观展示关键词:可以快速了解文本中最重要的词语。
- 帮助理解文本主题:词云中的词语可以帮助理解文本的主题和内容。
- 信息传递:将文本数据可视化,使其更容易被理解和传播。
4.2 数据集说明
Section titled “4.2 数据集说明”-
我们将基于真实的中文酒店评论语料来讲解常用的几种文本数据分析方法。
-
中文酒店评论语料:
-
属于二分类的中文情感分析语料。
-
其中train.tsv代表训练集, dev.tsv代表验证集, 二者数据样式相同。
-
train.tsv数据样式:
sentence label早餐不好,服务不到位,晚餐无西餐,早餐晚餐相同,房间条件不好,餐厅不分吸烟区.房间不分有无烟房. 0去的时候 ,酒店大厅和餐厅在装修,感觉大厅有点挤.由于餐厅装修本来该享受的早饭,也没有享受(他们是8点开始每个房间送,但是我时间来不及了)不过前台服务员态度好! 1有很长时间没有在西藏大厦住了,以前去北京在这里住的较多。这次住进来发现换了液晶电视,但网络不是很好,他们自己说是收费的原因造成的。其它还好。 1非常好的地理位置,住的是豪华海景房,打开窗户就可以看见栈桥和海景。记得很早以前也住过,现在重新装修了。总的来说比较满意,以后还会住 1交通很方便,房间小了一点,但是干净整洁,很有香港的特色,性价比较高,推荐一下哦 1酒店的装修比较陈旧,房间的隔音,主要是卫生间的隔音非常差,只能算是一般的 0酒店有点旧,房间比较小,但酒店的位子不错,就在海边,可以直接去游泳。8楼的海景打开窗户就是海。如果想住在热闹的地带,这里不是一个很好的选择,不过威海城市真的比较小,打车还是相当便宜的。晚上酒店门口出租车比较少。 1位置很好,走路到文庙、清凉寺5分钟都用不了,周边公交车很多很方便,就是出租车不太爱去(老城区路窄爱堵车),因为是老宾馆所以设施要陈旧些, 1酒店设备一般,套房里卧室的不能上网,要到客厅去。 04.3 获取标签数量分布
Section titled “4.3 获取标签数量分布”# 导入必备工具包import seaborn as snsimport pandas as pdimport matplotlib.pyplot as plt
# 思路分析 : 获取标签数量分布# 0 什么标签数量分布:求标签0有多少个 标签1有多少个 标签2有多少个# 1 设置显示风格plt.style.use('fivethirtyeight')# 2 pd.read_csv(path, sep='\t') 读训练集 验证集数据# 3 sns.countplot() 统计label标签的0、1分组数量# 4 画图展示 plt.title() plt.show()# 注意1:sns.countplot()相当于select * from tab1 group bydef dm_label_sns_countplot():
# 1 设置显示风格plt.style.use('fivethirtyeight') plt.style.use('fivethirtyeight')
# 2 pd.read_csv 读训练集 验证集数据 train_data = pd.read_csv(filepath_or_buffer='data/train.tsv', sep='\t') dev_data = pd.read_csv(filepath_or_buffer='data/dev.tsv', sep='\t')
# 3 sns.countplot() 统计label标签的0、1分组数量 sns.countplot(x='label', data=train_data)
# 4 画图展示 plt.title() plt.show() plt.title('train_label') plt.show()
# 验证集上标签的数量分布 # 3-2 sns.countplot() 统计label标签的0、1分组数量 sns.countplot(x='label', data=dev_data)
# 4-2 画图展示 plt.title() plt.show() plt.title('dev_label') plt.show()训练集标签数量分布:
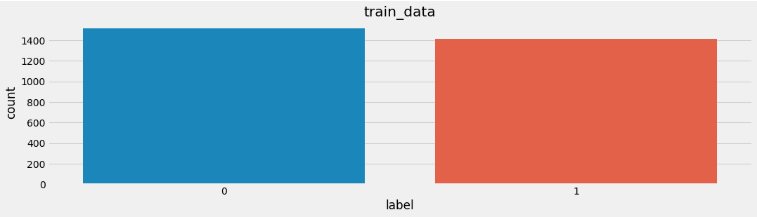
验证集标签数量分布:
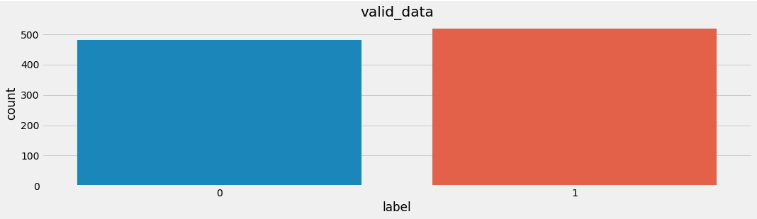
分析:在深度学习模型评估中, 我们一般使用ACC作为评估指标, 若想将ACC的基线定义在50%左右, 则需要我们的正负样本比例维持在1:1左右, 否则就要进行必要的数据增强或数据删减。上图中训练和验证集正负样本都稍有不均衡, 可以进行一些数据增强。
4.4 获取句子长度分布
Section titled “4.4 获取句子长度分布”# 思路分析 : 获取句子长度分布 -绘制句子长度分布-柱状图 句子长度分布-密度曲线图# 0 什么是句子长度分布:求长度为50的有多少个 长度51的有多少个 长度为52的有多少个# 1 设置显示风格plt.style.use('fivethirtyeight')# 2 pd.read_csv(path, sep='\t') 读训练集 验证集数据# 3 新增数据长度列:train_data['sentence_length'] = list(map(lambda x:len(x) , ...))# 4-1 绘制数据长度分布图-柱状图 sns.countplot(x='sentence_length', data=train_data)# 画图展示 plt.xticks([]) plt.show()# 4-2 绘制数据长度分布图-曲线图 sns.displot(x='sentence_length', data=train_data)# 画图展示 plt.yticks([]) plt.show()
def dm_len_sns_countplot_distplot(): # 1 设置显示风格plt.style.use('fivethirtyeight') plt.style.use('fivethirtyeight')
# 2 pd.read_csv 读训练集 验证集数据 train_data = pd.read_csv(filepath_or_buffer='data/train.tsv', sep='\t') dev_data = pd.read_csv(filepath_or_buffer='data/dev.tsv', sep='\t')
# 3 求数据长度列 然后求数据长度的分布 # map(func, *iterables): 对可迭代对象中的每个元素应用到指定的函数上, 返回一个迭代器对象 # list(map(lambda x: len(x), train_data['sentence'])): 获取每个句子的长度 # [len(value) for value in train_data['sentence'].values]: 也可以用此行代码实现获取每个句子的长度 train_data['sentence_length'] = list(map(lambda x: len(x), train_data['sentence']))
# 4 绘制数据长度分布图-柱状图 sns.countplot(x='sentence_length', data=train_data) # sns.countplot(x=train_data['sentence_length']) plt.xticks([]) # x轴上不要提示信息 # plt.title('sentence_length countplot') plt.show()
# 5 绘制数据长度分布图-曲线图 sns.displot(x='sentence_length', data=train_data, kde=True) # sns.displot(x=train_data['sentence_length']) plt.yticks([]) # y轴上不要提示信息 plt.show()
# 验证集 # 3 求数据长度列 然后求数据长度的分布 dev_data['sentence_length'] = list(map(lambda x: len(x), dev_data['sentence']))
# 4 绘制数据长度分布图-柱状图 sns.countplot(x='sentence_length', data=dev_data) # sns.countplot(x=dev_data['sentence_length']) plt.xticks([]) # x轴上不要提示信息 # plt.title('sentence_length countplot') plt.show()
# 5 绘制数据长度分布图-曲线图 sns.displot(x='sentence_length', data=dev_data, kde=True) # sns.displot(x=dev_data['sentence_length']) plt.yticks([]) # y轴上不要提示信息 plt.show()训练集句子长度分布:
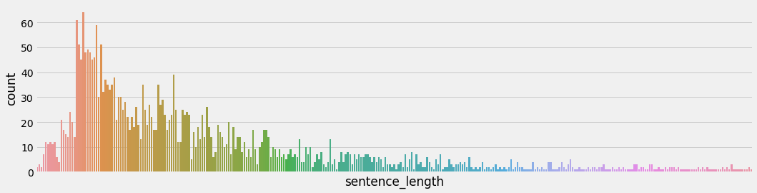
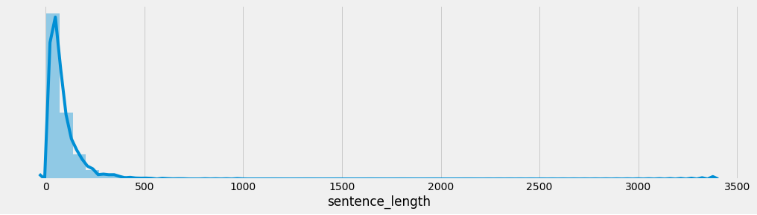
验证集句子长度分布:
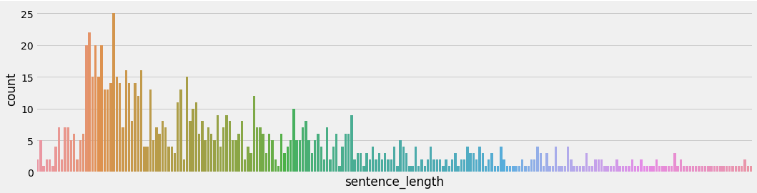
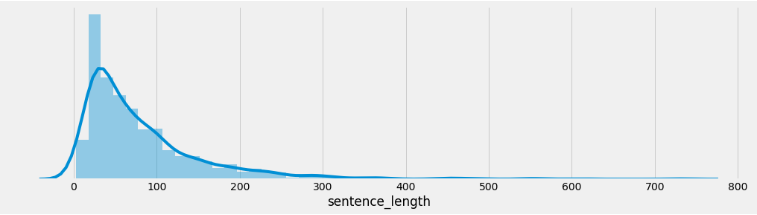
分析:通过绘制句子长度分布图, 可以得知我们的语料中大部分句子长度的分布范围, 因为模型的输入要求为固定尺寸的张量,合理的长度范围对之后进行句子截断补齐(规范长度)起到关键的指导作用。上图中大部分句子长度的范围大致为20-250之间。
4.5 获取正负样本长度散点分布
Section titled “4.5 获取正负样本长度散点分布”# 获取正负样本长度散点分布,也就是按照x正负样本进行分组 再按照y长度进行散点图# train_data['sentence_length'] = list(map(lambda x: len(x), train_data['sentence']))# sns.stripplot(y='sentence_length', x='label', data=train_data)def dm_sns_stripplot(): # 1 设置显示风格plt.style.use('fivethirtyeight') plt.style.use('fivethirtyeight')
# 2 pd.read_csv 读训练集 验证集数据 train_data = pd.read_csv(filepath_or_buffer='data/train.tsv', sep='\t') dev_data = pd.read_csv(filepath_or_buffer='data/dev.tsv', sep='\t')
# 3 求数据长度列 然后求数据长度的分布 train_data['sentence_length'] = list(map(lambda x: len(x), train_data['sentence'])) dev_data['sentence_length'] = list(map(lambda x: len(x), dev_data['sentence']))
# 4 统计正负样本长度散点图 (对train_data数据,按照label进行分组,统计正样本散点图) sns.stripplot(y='sentence_length', x='label', data=train_data) plt.show()
sns.stripplot(y='sentence_length', x='label', data=dev_data) plt.show()训练集上正负样本的长度散点分布:

验证集上正负样本的长度散点分布:

分析:通过查看正负样本长度散点图, 可以有效定位异常点的出现位置, 帮助我们更准确进行人工语料审查。上图中在训练集正样本中出现了异常点, 它的句子长度近3500左右, 需要我们人工审查。
4.6 获取不同词汇总数统计
Section titled “4.6 获取不同词汇总数统计”# 导入jieba用于分词# 导入chain方法用于扁平化列表import jiebafrom itertools import chain
def dm_word_count(): #设置显示风格plt.style.use('fivethirtyeight') plt.style.use('fivethirtyeight')
# 读训练集 验证集数据 train_data = pd.read_csv(filepath_or_buffer='data/train.tsv', sep='\t') dev_data = pd.read_csv(filepath_or_buffer='data/dev.tsv', sep='\t')
# 进行训练集的句子进行分词, 并统计出不同词汇的总数 # chain(*iterables): 将多个可迭代对象合并为一个可迭代对象 # *:拆解嵌套的列表/元组等 *[[1,2],[3,4]]->[1,2],[3,4] # *[jieba.lcut(value) for value in train_data["sentence"].values] -> 也可以用此代码替换 train_vocab = set(chain(*map(lambda x: jieba.lcut(x), train_data["sentence"]))) print("训练集共包含不同词汇总数为:", len(train_vocab))
# 进行验证集的句子进行分词, 并统计出不同词汇的总数 dev_vocab = set(chain(*map(lambda x: jieba.lcut(x), dev_data["sentence"]))) print("训练集共包含不同词汇总数为:", len(dev_vocab))输出结果:
训练集共包含不同词汇总数为: 12162训练集共包含不同词汇总数为: 68574.7 获取训练集高频形容词词云
Section titled “4.7 获取训练集高频形容词词云”# 使用jieba中的词性标注功能import jieba.posseg as psegfrom wordcloud import WordCloud# pip install wordcloud -i https://mirrors.aliyun.com/pypi/simple/
# 每句话产生形容词列表def get_a_list(text): r = [] # 使用jieba的词性标注方法切分文本 找到形容词存入到列表中返回 for g in pseg.lcut(text): if g.flag == "a": r.append(g.word) return r
# 根据词云列表产生词云def get_word_cloud(keywords_list): # 实例化词云生成器对象 # font_path: 字体文件路径 # max_words: 词云图上最多显示的词数 # background_color: 词云图背景颜色, 默认black黑色 wordcloud = WordCloud(font_path="data/SimHei.ttf", max_words=100, background_color='white') # 准备数据 keywords_string = " ".join (keywords_list) # 产生词云 wordcloud.generate(keywords_string)
# 画图 plt.figure() # 显示词云 # nterpolation="bilinear":指定图像的插值方式,使图像在显示时更加平滑。 plt.imshow(wordcloud, interpolation="bilinear") plt.axis('off') plt.show()
# 思路分析 训练集正样本词云 训练集负样本词云# 1 获得训练集上正样本 p_train_data# eg: 先使用逻辑==操作检索符合正样本 train_data[train_data['label'] == 1]# 2 获取正样本的每个句子的形容词 p_a_train_vocab = chain(*map(a,b))# 3 调用绘制词云函数def dm_train_word_cloud(): # 1 获得训练集上正样本p_train_data # eg: 先使用逻辑==操作检索符合正样本 train_data[train_data['label'] == 1] train_data = pd.read_csv(filepath_or_buffer='data/train.tsv', sep='\t') p_train_data = train_data[train_data['label'] == 1 ]['sentence']
# 2 获取正样本的每个句子的形容词 p_a_train_vocab = chain(*map(a,b)) p_a_train_vocab = chain(*map(get_a_list, p_train_data)) # print(p_a_train_vocab) # print(list(p_a_train_vocab))
# 3 调用绘制词云函数 get_word_cloud(p_a_train_vocab)
print('*' * 60 ) # 训练集负样本词云 n_train_data = train_data[train_data['label'] == 0 ]['sentence']
# 2 获取正样本的每个句子的形容词 p_a_train_vocab = chain(*map(a,b)) n_a_train_vocab = chain(*map(get_a_list, n_train_data)) # print(n_a_dev_vocab) # print(list(n_a_dev_vocab))
# 3 调用绘制词云函数 get_word_cloud(n_a_train_vocab)训练集正样本形容词词云:

训练集负样本形容词词云:

4.8 获取验证集高频形容词词云
Section titled “4.8 获取验证集高频形容词词云”def dm_valid_word_cloud(): # 1 获得验证集上正样本p_valid_data # eg: 先使用逻辑==操作检索符合正样本 valid_data[valid_data['label'] == 1] valid_data = pd.read_csv(filepath_or_buffer='data/dev.tsv', sep='\t') p_valid_data = valid_data[valid_data['label'] == 1]['sentence']
# 2 获取正样本的每个句子的形容词 p_a_valid_data = chain(*map(a,b)) p_a_valid_data = chain(*map(lambda x: get_a_list(x), p_valid_data)) # print(p_a_valid_data) # print(list(p_a_valid_data))
# 3 调用绘制词云函数 get_word_cloud(p_a_valid_data)
print('*' * 60) # 验证集负样本词云 n_valid_data = valid_data[valid_data['label'] == 0]['sentence']
# 2 获取正样本的每个句子的形容词 n_a_valid_vocab = chain(*map(a,b)) n_a_valid_vocab = chain(*map(lambda x: get_a_list(x), n_valid_data)) # print(n_a_valid_vocab) # print(list(n_a_valid_vocab))
# 3 调用绘制词云函数 get_word_cloud(n_a_valid_vocab)验证集正样本形容词词云:

验证集负样本形容词词云:

分析:根据高频形容词词云显示, 我们可以对当前语料质量进行简单评估, 同时对违反语料标签含义的词汇进行人工审查和修正, 来保证绝大多数语料符合训练标准。上图中的正样本大多数是褒义词, 而负样本大多数是贬义词, 基本符合要求, 但是负样本词云中也存在”便利”这样的褒义词, 因此可以人工进行审查。
4.9 小结
Section titled “4.9 小结”- 文本数据分析的作用:
- 文本数据分析能够有效帮助我们理解数据语料, 快速检查出语料可能存在的问题, 并指导之后模型训练过程中一些超参数的选择.
- 常用的几种文本数据分析方法:
- 标签数量分布
- 句子长度分布
- 词频统计与关键词词云
- 基于真实的中文酒店评论语料进行几种文本数据分析方法.
- 获得训练集和验证集的标签数量分布
- 获取训练集和验证集的句子长度分布
- 获取训练集和验证集的正负样本长度散点分布
- 获得训练集与验证集不同词汇总数统计
- 获得训练集上正负的样本的高频形容词词云