
项目1-智能客服对话偏好对齐
RLHF项目1:智能客服对话偏好对齐
Section titled “RLHF项目1:智能客服对话偏好对齐”一、RLHF介绍
Section titled “一、RLHF介绍”学习目标:
1.知道人工反馈强化学习的概念和应用场景
2.知道RLHF在大模型微调中的作用
3.知道RLHF大模型微调的核心流程
1.1 什么是RLHF
Section titled “1.1 什么是RLHF” 人工反馈强化学习(RLHF) 是强化学习(RL)的一个分支,通过引入人类反馈来优化智能体(Agent)的行为策略,解决传统RL因奖励函数设计困难或环境稀疏奖励导致的训练效率低下问题。其核心思想是:
- 人类反馈作为信号:替代或辅助人工设计的奖励函数,指导模型学习更符合人类偏好的策略。
- 交互式学习:智能体与人类在训练过程中持续交互,动态调整学习方向。
1.2 人工反馈的类型
Section titled “1.2 人工反馈的类型” 一般可以考虑从以下几个角度设计人工反馈:
- 显式反馈:人类对智能体的行为直接评分(如1-5分)或排序(A行为优于B)。
- 隐式反馈:通过行为日志(如点击、停留时间)间接反映偏好。
- 纠正反馈:人类直接干预错误动作(如自动驾驶中的人工接管)。
1.3 RLHF微调大模型
Section titled “1.3 RLHF微调大模型”1.3.1 RLHF微调的作用
Section titled “1.3.1 RLHF微调的作用”说起大模型微调,容易想到学过的监督微调(SFT),它在很多场景中确实有效,但是也存在固有的局限性。
- 对“标准答案”的过度依赖与数据瓶颈:SFT的效果极度依赖于训练数据的质量,构建大规模、高质量、多样化的指令数据集成本高昂。而且,现实世界中的问题千奇百怪,无法通过标注穷尽所有场景,一旦遇到SFT数据集中未覆盖的内容,模型就容易“答非所问”
- 优化目标与“好答案”的错位:SFT的优化目标是让模型的输出“像”标准答案,但这不等于生成的答案就是“好”的或“有用”的。例如,对于“如何缓解工作焦虑”这一问题,标准答案可能是“建议通过运动、冥想调节”。如果模型生成了一个更具体、更具操作性的回答(如“可以试试每天10分钟拉伸+睡前5分钟深呼吸”),这个回答在SFT的评判逻辑中反而可能因为用词不同而被判定为偏离范例,获得低分。
- 无法理解与适应人类的细微偏好:生活中许多问题并无唯一正确答案,但却存在“更符合人类偏好”的选择,这导致SFT后的模型输出可能正确但缺乏“情商”。
RLHF技术,可以使大模型的输出与用户意图或偏好对齐。
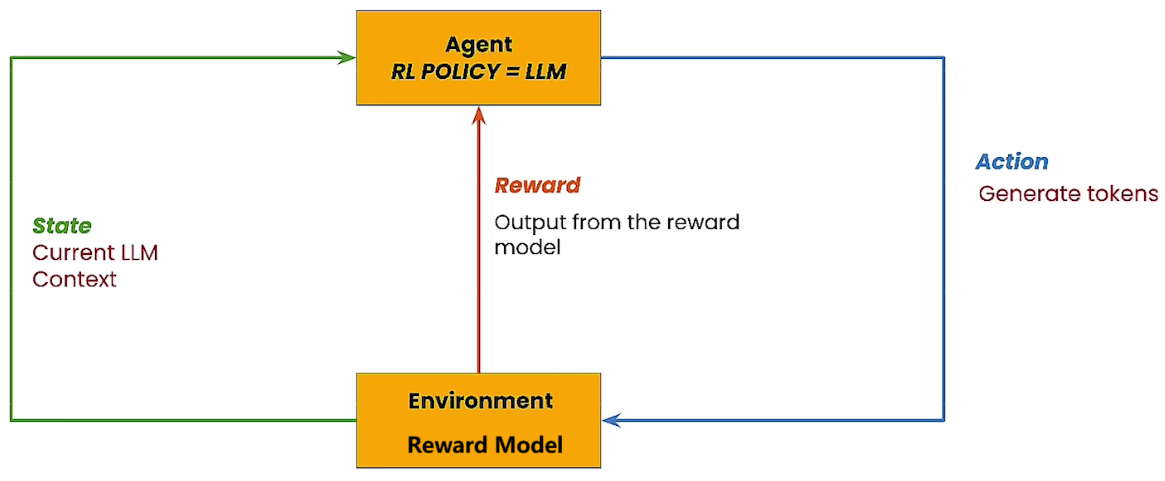
1.3.2 RLHF微调的架构
Section titled “1.3.2 RLHF微调的架构”RLHF架构中,智能体是需要被优化的大语言模型本身,环境是奖励模型。奖励模型会输出一个标量,表示符合人类偏好的奖励数值。
1.3.3 RLHF微调的三个阶段
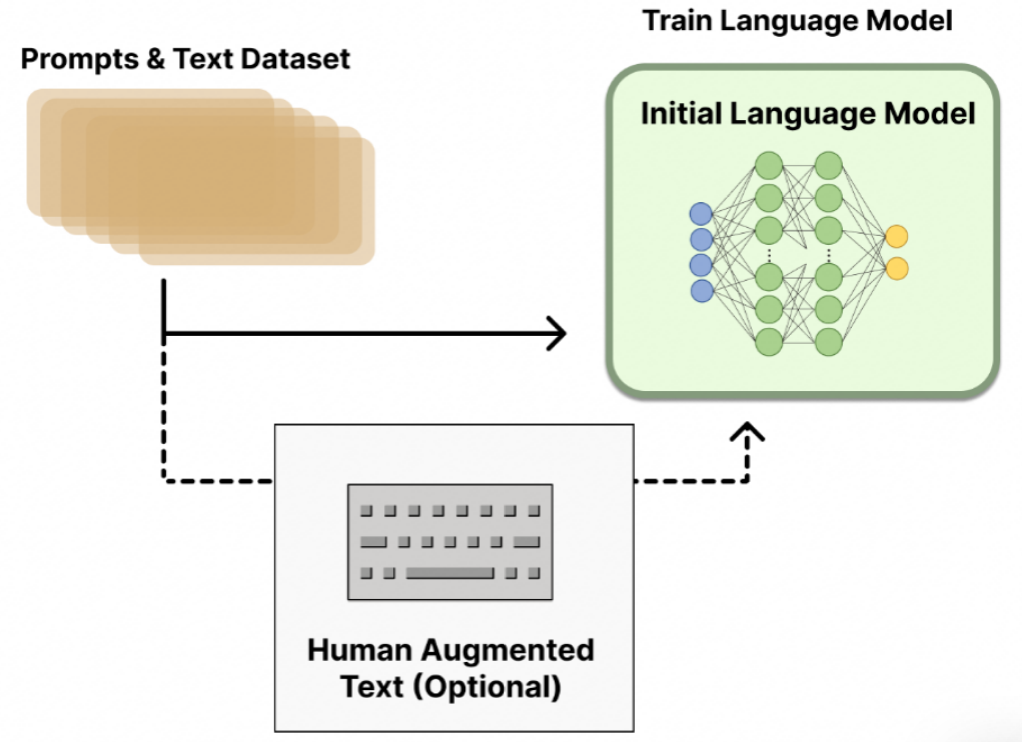
Section titled “1.3.3 RLHF微调的三个阶段”- 第一阶段:监督微调大语言模型。
此阶段与传统的SFT无异,使用监督学习微调后的模型,基于一个已经初步具备此方面知识的模型进行训练,收敛更快,效果通常更好。
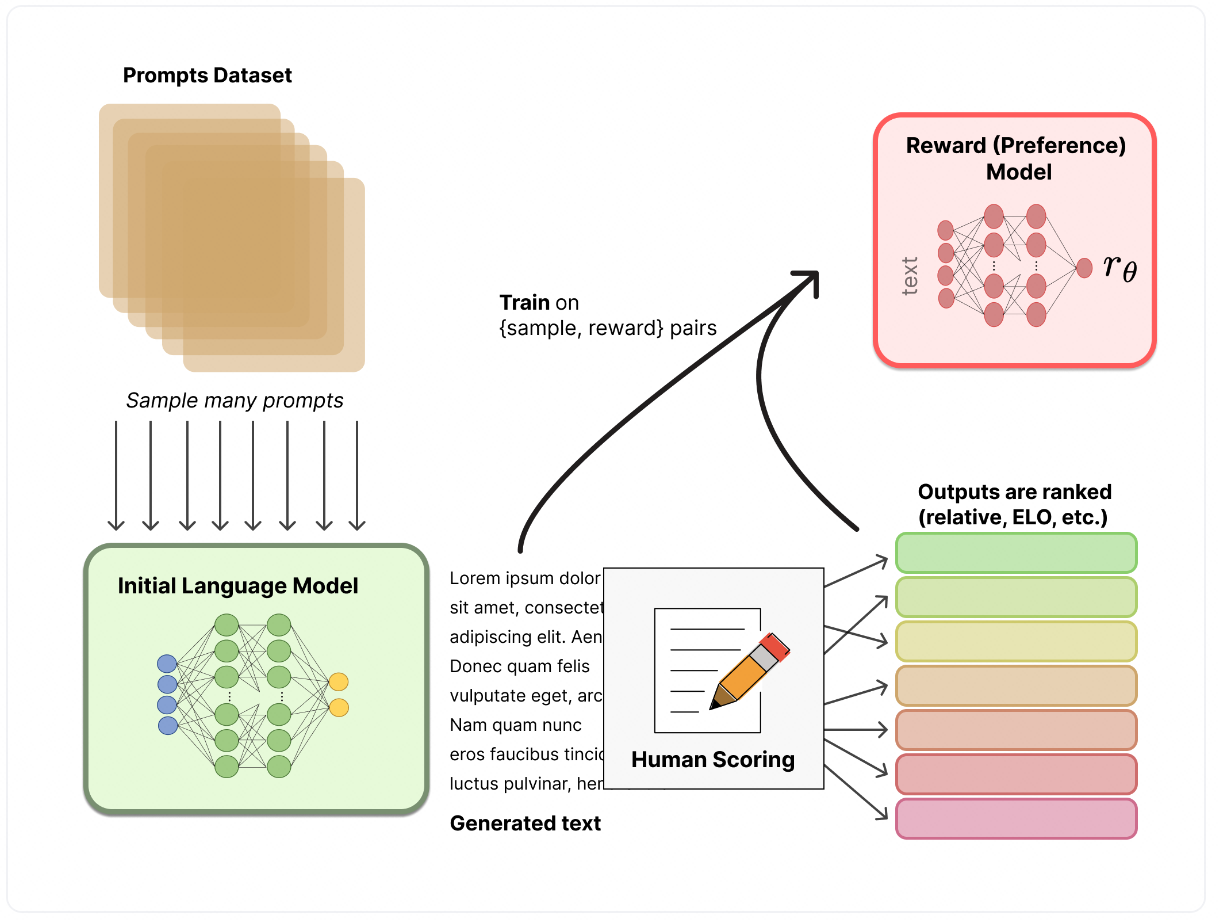
- 第二阶段:训练奖励模型(reward model)
这是RLHF的关键创新。不再要求人类为每个问题编写标准答案,而是让标注者对同一提示词下模型的多个不同输出进行排序(例如,回答A优于回答B)。利用这些偏好对比数据,训练一个独立的奖励模型(Reward Model)。这个模型的功能是学习人类的判断标准,并为任何“提示词-回答”对预测一个标量分数,分数越高代表回答越符合人类偏好。这相当于为模型配备了一个自动化的“品味裁判”。
奖励模型通常比被评估的语言大模型小一些(deepspeed的示例中,语言大模型66B,奖励模型只有350M)。输入是prompt+answer的形式,输出是模型对prompt+answer进行打分,是一个标量,表示符合人类偏好的奖励数值,这个奖励数值对于后面的强化学习训练非常重要。
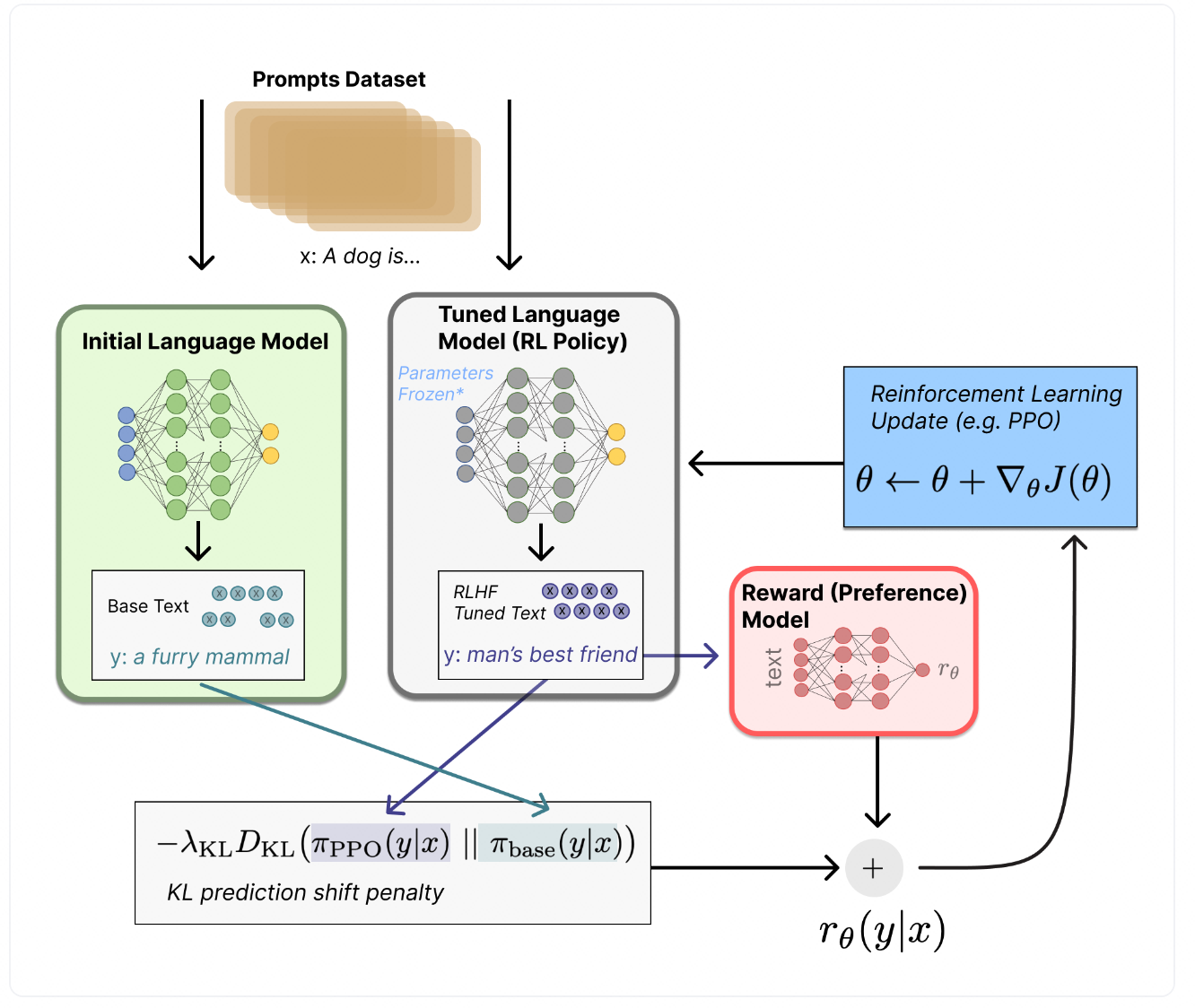
- 第三阶段:通过RL微调大模型(以PPO为例)
在第三阶段,实现RLHF的核心过程——通过强化学习微调大模型。这一阶段的目标是利用前两个阶段所训练的SFT微调模型与奖励模型,在大模型的生成过程中不断优化其输出,使其更加符合人类偏好的需求。通过这个过程,大模型的行为会变得越来越符合用户的意图和需求。
- 模型行为调整: 在这一阶段,使用奖励模型对大模型(即Actor模型)生成的每个输出进行评分。大模型的目标是最大化奖励模型的得分,因此,它会调整其生成策略,以尽量提高生成的内容符合用户偏好的概率。
- 反馈驱动优化: 这一阶段的核心是通过环境反馈(奖励模型提供的评分)来训练大模型,强化模型在生成过程中根据评分进行自我调整。换句话说,大模型在与用户的交互中学习,不断改进其回答方式,使输出符合用户期望。
- 通过模拟奖励机制进行更新: 在RL微调过程中,奖励模型为大模型的每个输出提供奖励或惩罚,大模型通过强化学习算法(如PPO)在奖励的指导下调整策略,以便输出更符合用户期望。
二、智能客服对话偏好对齐(PPO算法)
Section titled “二、智能客服对话偏好对齐(PPO算法)”学习目标:
1.了解项目背景与数据情况
2.掌握RLHF微调大模型的实现流程
3.完成基于PPO算法的大模型微调
2.1 背景
Section titled “2.1 背景”某电商平台希望提升其智能客服机器人的对话质量,特别是在处理退换货请求时的表现。当前的GPT-2模型能够生成语法正确的回复,但在以下方面存在不足:1. 回复过于机械,缺乏同理心2. 解决方案不够具体,需要客户多次追问3. 语气有时过于生硬,影响用户体验2.2 目标
Section titled “2.2 目标”通过RLHF训练,让模型学会生成更加人性化、具体且有效的客服回复,提高客户满意度。2.3 四个模型
Section titled “2.3 四个模型”强化学习微调阶段,会用到**四个模型,actor model, ref model,reward model和critic model。训练时,会更新actor model和critic model的模型参数。**其中:
-
actor model(策略模型/目标模型):就是我们强化学习要微调的大模型。
-
Ref model(参考模型):参考模型是用于生成理想输出的“标准”模型,帮助评估大模型的输出质量。强化学习容易把模型训练“坏”,因此需要另外一个不会参数更新的 ref_model来当作标的,别让actor mode偏离太远。在训练模式下,将prompt+answer分别输入到actor mode和ref model,用KL散度来衡量 ref model和actor mode输出的差别。同时将KL散度(衡量数据分布差距大小)纳入损失函数(KL散度本质是纳入到奖励值里边的,奖励值被纳入到了损失函数),进而来约束 ref_model和actor mode的输出分布不要差距太大。
-
Reward model(奖励模型):奖励模型根据用户反馈或评价计算奖励,指导大模型的优化方向。
-
Critic model(价值模型/评论模型):评论模型评估大模型的行为与输出,并提供策略优化的反馈。
2.4 训练流程
Section titled “2.4 训练流程”2.5 实现流程
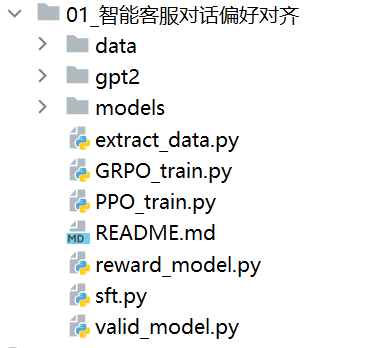
Section titled “2.5 实现流程”项目代码结构如下图所示:
- data文件夹是训练数据
- gpt2文件夹是base LLM文件
- models文件夹保存了微调训练得到的模型,包括SFT监督微调的模型,奖励模型,以及PPO微调训练的模型
- extract_data.py用来数据清洗与数据抽取
- sft.py用来训练监督微调的模型
- reward_model.py用来训练奖励模型
- PPO_train.py是PPO算法微调大模型
- GRPO_train.py是GRPO算法监督微调大模型
- valid_model.py用来评估PPO以及GRPO算法微调大模型的生成结果
2.5.1 数据处理
Section titled “2.5.1 数据处理”- 数据源
| 字段 | 描述 |
|---|---|
| conv_id | 每个用户支持对话的唯一 ID |
| turn_index | 对话中的消息顺序 |
| role | 发言者的角色(客户或客服) |
| text | 合成的对话文本 |
| timestamp | 消息时间戳(ISO 格式) |
| industry | 所属领域(如 SaaS、旅游、教育等) |
| product | 产品名称(如SSO,Flight,Refund) |
| issue_type | 问题的分类(如Course Access,Seat Change,Service Not Activated) |
| language | 语言或地区代码(如 en、en-IN、hi-IN) |
| channel | 聊天平台(如邮件、WhatsApp、网页聊天等) |
| customer_name | 用户名 |
| agent_name | 智能体名 |
| overall_sentiment | 用户的整体情感态度(如negative,neutral,positive) |
| overall_urgency | 问题的紧急程度或重要性(如high,medium) |
| outcome | 问题的处理结果(如Resolved,Pending Vendor) |
| primary_intent | 用户的主要需求或问题类型(如change_plan,refund_status) |
- 数据探查
data = pd.read_csv('./data/customer_support_data.csv')print(data.info())#RangeIndex: 976271 entries, 0 to 976270#Data columns (total 16 columns):# # Column Non-Null Count Dtype#--- ------ -------------- -----# 0 conv_id 976271 non-null object# 1 turn_index 976271 non-null int64# 2 role 976271 non-null object# 3 text 976271 non-null object# 4 timestamp 976271 non-null object# 5 industry 976271 non-null object# 6 product 976271 non-null object# 7 issue_type 976271 non-null object# 8 language 976271 non-null object# 9 channel 976271 non-null object# 10 customer_name 976271 non-null object# 11 agent_name 976271 non-null object# 12 overall_sentiment 976271 non-null object# 13 overall_urgency 976271 non-null object# 14 outcome 976271 non-null object# 15 primary_intent 976271 non-null object#dtypes: int64(1), object(15)#memory usage: 119.2+ MBprint(data[['conv_id', 'role', 'text']].head(20))整体来看,数据还是很规则的,但是text中的内容后半部分有乱码,并且前半部分混杂了印地语和英语,需要进行数据清洗。
- 数据清洗与数据抽取
数据较为丰富,但考虑到资源有限(6G显存),因此随机抽取其中500个对话的数据,资源充足的情况下,可以用更多的数据进行训练,效果更好。
代码文件:extract_data.py
import pandas as pdimport numpy as np
def is_mostly_english(text): """ 判断文本是否主要是英文。因为text中混杂了印地语和英语 剔除包含特定印地语关键词的句子 (Main, abhi, kar, raha, hoon, hai) """ if not text: return False
# 强力过滤:直接屏蔽掉常见的 Hinglish 关键词 hinglish_keywords = ["abhi", "kar", "rahi", "kar", "raha", "ho", "gaya", "karna", "nahi"] for word in hinglish_keywords: if word.lower() in text.lower(): return False return True
def clean_customer_text(text): """ 清理函数:保留直到最后一个标点符号的内容,去除尾部乱码 """ if not text or not isinstance(text, str): return ""
# 预处理:去除首尾空格 text = text.strip()
# 定义合法的句子结束符 # 包含了英文的 . ? ! 和中文的 。 ? ! valid_endings = ['.', '?', '!', '。', '?', '!']
# 倒序查找最后一个标点符号的位置 last_idx = -1 for char in valid_endings: idx = text.rfind(char) if idx > last_idx: last_idx = idx
# 如果找到了标点符号 if last_idx != -1: # 截取到标点符号(包含标点本身) cleaned = text[:last_idx + 1] return cleaned.strip()
# 如果整段话都没有标点符号(极为罕见), # 这种数据通常质量很差,可以选择返回原文本,或者直接丢弃(返回空字符串) # 这里为了保守起见,返回原文本 return text
if __name__ == '__main__': # 获取数据源 data = pd.read_csv('./data/customer_support_data.csv') print(data.info()) data['text'] = data['text'].apply(clean_customer_text) # 对data数据中的text进行is_mostly_english判断 data['is_english'] = data['text'].apply(is_mostly_english) # 如果is_english是False,则对应的conv_id对应的数据都删除 # 找出包含非英文文本的 conv_id non_english_conv_ids = data[data['is_english'] == False]['conv_id'].unique() # 从数据中过滤掉这些 conv_id 对应的所有行 data = data[~data['conv_id'].isin(non_english_conv_ids)]
# 从数据中随机抽取500个conv_id对应的数据 conv_ids = np.random.choice(data['conv_id'].unique(), 500, replace=False) data = data[data['conv_id'].isin(conv_ids)][['conv_id', 'role', 'text']] print(data.shape) data.to_csv('./data/customer_support_data_samples.csv', index=False, )2.5.2 监督微调大模型
Section titled “2.5.2 监督微调大模型”下面进入RLHF微调的第一个阶段,监督微调大语言模型。之所以进行监督微调,是因为使用监督学习微调后的模型,后续基于一个已经初步具备此方面知识的模型进行训练,收敛更快,效果通常更好。
微调的大模型选用gpt2,此模型只有124M(0.1B)
from transformers import AutoModelForCausalLM, AutoTokenizermodel_path = './gpt2'tokenizer = AutoTokenizer.from_pretrained(model_path)model = AutoModelForCausalLM.from_pretrained(model_path)# 打印模型的参数数量 124439808-->124Mprint(sum(p.numel() for p in model.parameters()))实现步骤如下:
- 模型与分词器加载
- 数据准备
- 使用 DataCollator 进行动态 Padding
- 优化器
- 训练循环
- 保存模型
- 简单的推理测试
代码文件:sft.py
import torchfrom transformers import AutoModelForCausalLM, AutoTokenizer, DataCollatorForLanguageModelingfrom datasets import load_datasetfrom torch.utils.data import DataLoaderimport osfrom tqdm import tqdm # 引入进度条
# --- 超参数设置 ---LEARNING_RATE = 5e-5 # 微调通常使用更小的学习率BATCH_SIZE = 8EPOCHS = 3MAX_LENGTH = 256 # 增加长度以容纳人设和对话MODEL_NAME = "gpt2"SAVE_PATH = "./models/customer_service_sft"DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def prepare_and_tokenize_data(tokenizer): """ 加载并处理CSV格式的客服对话数据: 1. 支持CSV文件格式 2. 按对话ID分组处理 3. 构造客服对话格式的输入输出对 4. 仅对回答部分计算Loss (Label Masking) """ # 读取CSV文件 dataset = load_dataset("csv", data_dir="./data", data_files="customer_support_data_samples.csv") # 获取训练数据集 raw_dataset = dataset['train']
def process_function(examples): inputs = [] targets = []
# 按conv_id分组处理对话 conv_id_list = examples['conv_id'] role_list = examples['role'] text_list = examples['text']
# 使用字典存储每个对话的轮次 conversations = {} for i in range(len(conv_id_list)): conv_id = conv_id_list[i] role = role_list[i] text = text_list[i]
if conv_id not in conversations: conversations[conv_id] = [] conversations[conv_id].append({'role': role, 'text': text})
# 处理每个对话 - 提取第一条记录 for conv_id, turns in conversations.items(): if len(turns) >= 2: # 确保至少有一轮完整的对话 # 查找第一条customer消息和对应的agent回复 customer_text = None agent_text = None
for turn in turns: if turn['role'] == 'customer' and customer_text is None: customer_text = turn['text'] elif turn['role'] == 'agent' and customer_text is not None and agent_text is None: agent_text = turn['text'] break # 找到对应的agent回复就停止
# 如果找到了完整的对话对,则添加到训练数据中 if customer_text is not None and agent_text is not None: input_text = f"Customer: {customer_text}\nAgent:" target_text = f" {agent_text}" inputs.append(input_text) targets.append(target_text)
# Tokenization - 使用 padding 和 truncation 确保一致性 model_inputs = tokenizer( [p + t + tokenizer.eos_token for p, t in zip(inputs, targets)], max_length=MAX_LENGTH, truncation=True, padding="max_length", return_tensors="pt" )
# input_ids是输入文本中每个 token 在词汇表中的唯一编号 # labels,相当于监督学习中的目标变量y labels = model_inputs["input_ids"].clone() attention_mask = model_inputs["attention_mask"]
# 对每个样本单独处理 prompt 长度 for i in range(len(inputs)): # Mask 掉 Prompt 部分 (提问不参与计算 loss) prompt_ids = tokenizer.encode(inputs[i], add_special_tokens=False) prompt_len = len(prompt_ids) # 将 prompt 部分的 labels 设为 -100 if prompt_len < MAX_LENGTH: labels[i, :prompt_len] = -100 # Mask 掉 Padding 部分 padding_mask = attention_mask[i] == 0 labels[i, padding_mask] = -100
model_inputs["labels"] = labels return model_inputs
# 移除原始列,只保留模型需要的列 tokenized_train = raw_dataset.map( process_function, batched=True, remove_columns=['conv_id', 'role', 'text'] )
# 划分训练集和验证集 split_dataset = tokenized_train.train_test_split(test_size=0.1) train_ds = split_dataset['train'] val_ds = split_dataset['test']
return train_ds, val_ds
def train(): # 1. 模型与分词器加载 print(f"Loading {MODEL_NAME} on {DEVICE}...") tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) # GPT2 没有 pad token,指定为 eos token tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME).to(DEVICE)
# 2. 数据准备 print("Processing datasets...") train_ds, val_ds = prepare_and_tokenize_data(tokenizer)
# 3. 使用 DataCollator 进行动态 Padding # mlm=False 表示是 Causal Language Modeling (自回归) data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
train_loader = DataLoader( train_ds, batch_size=BATCH_SIZE, shuffle=True, collate_fn=data_collator ) val_loader = DataLoader( val_ds, batch_size=BATCH_SIZE, collate_fn=data_collator )
# 4. 优化器 optimizer = torch.optim.AdamW(model.parameters(), lr=LEARNING_RATE)
# 5. 训练循环 print("Starting training...") for epoch in range(EPOCHS): model.train() total_train_loss = 0
# 使用 tqdm 显示进度条 progress_bar = tqdm(train_loader, desc=f"Epoch {epoch + 1}/{EPOCHS}")
for batch in progress_bar: # 移动数据到设备 batch = {k: v.to(DEVICE) for k, v in batch.items()}
# 前向传播 # 包含 input_ids 和 labels outputs = model(**batch) # 模型自动计算的损失值 loss = outputs.loss
# 反向传播 optimizer.zero_grad() loss.backward() optimizer.step()
total_train_loss += loss.item() progress_bar.set_postfix({'loss': loss.item()})
avg_train_loss = total_train_loss / len(train_loader) print(f"Epoch {epoch + 1} - Avg Train Loss: {avg_train_loss:.4f}")
# 验证循环 model.eval() total_val_loss = 0 with torch.no_grad(): for batch in val_loader: batch = {k: v.to(DEVICE) for k, v in batch.items()} outputs = model(**batch) total_val_loss += outputs.loss.item()
avg_val_loss = total_val_loss / len(val_loader) print(f"Epoch {epoch + 1} - Validation Loss: {avg_val_loss:.4f}") print("-" * 50)
# 6. 保存模型 print(f"Saving model to {SAVE_PATH}") model.save_pretrained(SAVE_PATH) tokenizer.save_pretrained(SAVE_PATH)
# 7.简单的推理测试 print("Running inference test...") test_input = "Hello, my SSO is not working as expected." prompt = f"Customer: {test_input}\nAgent:"
inputs = tokenizer(prompt, return_tensors="pt").to(DEVICE) output_ids = model.generate( **inputs, # tokenizer处理后的输入张量 max_new_tokens=50, # 限制模型最多生成 50 个新 token pad_token_id=tokenizer.eos_token_id, # 指定填充 token 的 ID 为结束符 token ID do_sample=True, # 启用采样生成模式,引入随机性,使生成结果更加多样化 top_p=0.9 # 启用 nucleus sampling,只从累积概率达到 90% 的词汇中采样 ) print(f"Input: {prompt}") print(f"Generated: {tokenizer.decode(output_ids[0], skip_special_tokens=True)}")
if __name__ == "__main__": train()2.5.3 训练奖励模型
Section titled “2.5.3 训练奖励模型”接下来是RLHF微调的第二个阶段,训练奖励模型。
奖励模型通常比被评估的语言大模型小一些(deepspeed的示例中,语言大模型66B,奖励模型只有350M)。gpt2大小只有0.1B,所以本项目中的奖励模型也以gpt2进行训练。
与上一阶段监督微调不同,监督微调使用的是AutoModelForCausalLM 因果语言模型,奖励模型需要输出一个分数,AutoModelForSequenceClassification 是序列分类模型,所以选择AutoModelForSequenceClassification模型,然后将输出层换上一个简单的线性层(Score Head),将隐藏层状态映射为 1 个数值。
**数据格式要求:RM训练通常需要成对数据(Pairwise Data),即 (Prompt, Chosen_Response, Rejected_Response)。**其中Chosen: 人类倾向的高质量回答(通常是数据集里的原始Ground Truth)。Rejected: 质量较差的回答。然而,数据集中只有正确的对话,没有人工标注成这种格式的数据,所以本项目采用负采样(Negative Sampling)策略。
负采样(Negative Sampling):把“其他对话中的Agent回复”作为当前问题的“错误回答”来构建训练数据。
实现步骤如下:
- 加载 SFT 模型,但修改为分类头 (num_labels=1)
- 准备数据
- 训练循环
- 保存模型
- 测试打分
代码文件:reward_model.py
"""模型结构变化:SFT模型是生成文本(CausalLM),RM是输出一个分值(输出维度为1)。数据格式要求:RM训练通常需要成对数据(Pairwise Data),即 (Prompt, Chosen_Response, Rejected_Response)。Chosen: 人类倾向的高质量回答(通常是数据集里的原始Ground Truth)。Rejected: 质量较差的回答。负采样(Negative Sampling):由于本数据集(customer_support_data_samples.csv)只有正确的对话, 没有“错误的回答”,代码中将使用负采样策略——把“其他对话中的Agent回复”作为当前问题的“错误回答”来构建训练数据。"""import torchfrom transformers import AutoModelForSequenceClassification, AutoTokenizerfrom datasets import load_datasetfrom torch.utils.data import DataLoader, Datasetimport randomfrom tqdm import tqdm
# --- 超参数设置 ---# 使用监督学习微调后的模型,基于一个已经初步具备此方面知识的模型进行训练,收敛更快,效果通常更好SFT_MODEL_PATH = "./models/customer_service_sft"SAVE_PATH = "./models/customer_service_rm"
LEARNING_RATE = 2e-5 # 奖励模型(RM)通常使用极小的学习率BATCH_SIZE = 4 # RM需要同时处理两个句子(chosen/rejected),显存占用较大,适当调小BatchEPOCHS = 1 # 奖励模型很容易过拟合,通常1-2轮即可MAX_LENGTH = 256DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class PairwiseDataset(Dataset): """ 构造成对数据:(Prompt + Good Response) vs (Prompt + Bad Response) 由于原数据没有坏数据,我们随机抽取其他对话的回复作为 Bad Response """
def __init__(self, data, tokenizer, max_length): self.tokenizer = tokenizer self.max_length = max_length self.pairs = []
# 1. 预处理:提取所有有效的 (Customer, Agent) 对 valid_dialogues = [] all_agent_responses = [] # 用于负采样
# 按conv_id分组 conversations = {} for i in range(len(data['conv_id'])): conv_id = data['conv_id'][i] role = data['role'][i] text = data['text'][i]
if conv_id not in conversations: conversations[conv_id] = [] conversations[conv_id].append({'role': role, 'text': text})
if role == 'agent' and text: all_agent_responses.append(text)
# 2. 构建正样本和负样本 for conv_id, turns in conversations.items(): if len(turns) >= 2: customer_text = None agent_text_chosen = None
for turn in turns: if turn['role'] == 'customer' and customer_text is None: customer_text = turn['text'] elif turn['role'] == 'agent' and customer_text is not None and agent_text_chosen is None: agent_text_chosen = turn['text'] break
if customer_text and agent_text_chosen: # 负采样:随机选一个不是当前回复的Agent回复 agent_text_rejected = random.choice(all_agent_responses) # 确保选择的Agent回复和当前回复不同,如果仍然相同,则重新选择 while agent_text_rejected == agent_text_chosen and len(all_agent_responses) > 1: agent_text_rejected = random.choice(all_agent_responses)
self.pairs.append({ 'prompt': customer_text, 'chosen': agent_text_chosen, 'rejected': agent_text_rejected })
def __len__(self): return len(self.pairs)
def __getitem__(self, idx): item = self.pairs[idx] prompt = f"Customer: {item['prompt']}\nAgent:"
# 构造 Good (Chosen) 句子 text_chosen = f"{prompt} {item['chosen']}{self.tokenizer.eos_token}" # 构造 Bad (Rejected) 句子 text_rejected = f"{prompt} {item['rejected']}{self.tokenizer.eos_token}"
# Tokenize Chosen enc_chosen = self.tokenizer( text_chosen, max_length=self.max_length, truncation=True, padding="max_length", return_tensors="pt" )
# Tokenize Rejected enc_rejected = self.tokenizer( text_rejected, max_length=self.max_length, truncation=True, padding="max_length", return_tensors="pt" )
return { "input_ids_chosen": enc_chosen["input_ids"].squeeze(0), "attention_mask_chosen": enc_chosen["attention_mask"].squeeze(0), "input_ids_rejected": enc_rejected["input_ids"].squeeze(0), "attention_mask_rejected": enc_rejected["attention_mask"].squeeze(0), }
def train_reward_model(): # 1. 加载 SFT 模型,但修改为分类头 (num_labels=1) print(f"Loading SFT model from {SFT_MODEL_PATH} for RM training...") # 注意:使用 AutoModelForSequenceClassification,而不是 AutoModelForCausalLM # AutoModelForCausalLM 是因果语言模型,AutoModelForSequenceClassification 是序列分类模型 # 奖励模型需要输出一个分数,SequenceClassification输出层会换上一个简单的线性层(Score Head), # 将隐藏层状态映射为 1 个数值。 try: model = AutoModelForSequenceClassification.from_pretrained( SFT_MODEL_PATH, num_labels=1, problem_type="regression" ).to(DEVICE) except OSError: print("错误:未找到SFT模型。请先运行 SFT 训练代码。") return
tokenizer = AutoTokenizer.from_pretrained(SFT_MODEL_PATH) tokenizer.pad_token = tokenizer.eos_token # 配置 pad_token_id 能够避免某些警告 model.config.pad_token_id = tokenizer.pad_token_id
# 2. 准备数据 print("Processing datasets and generating negative samples...") dataset = load_dataset("csv", data_dir="./data", data_files="customer_support_data_samples.csv")['train']
# 划分数据集 split_dataset = dataset.train_test_split(test_size=0.1, seed=42)
train_ds = PairwiseDataset(split_dataset['train'], tokenizer, MAX_LENGTH) val_ds = PairwiseDataset(split_dataset['test'], tokenizer, MAX_LENGTH)
train_loader = DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True) val_loader = DataLoader(val_ds, batch_size=BATCH_SIZE)
optimizer = torch.optim.AdamW(model.parameters(), lr=LEARNING_RATE)
# 3. 训练循环 print("Starting RM training...")
for epoch in range(EPOCHS): # 训练模式 model.train() total_loss = 0 progress_bar = tqdm(train_loader, desc=f"Epoch {epoch + 1}/{EPOCHS}")
for batch in progress_bar: # 移动数据到 GPU batch = {k: v.to(DEVICE) for k, v in batch.items()}
optimizer.zero_grad()
# 前向传播 - Chosen (Good) outputs_chosen = model( input_ids=batch["input_ids_chosen"], attention_mask=batch["attention_mask_chosen"] ) rewards_chosen = outputs_chosen.logits # [batch_size, 1]
# 前向传播 - Rejected (Bad) outputs_rejected = model( input_ids=batch["input_ids_rejected"], attention_mask=batch["attention_mask_rejected"] ) rewards_rejected = outputs_rejected.logits # [batch_size, 1]
# --- 计算 Pairwise Ranking Loss --- # 目标:maximize (reward_chosen - reward_rejected) # Loss = -log(sigmoid(chosen - rejected)) loss = -torch.log(torch.sigmoid(rewards_chosen - rewards_rejected)).mean()
loss.backward() optimizer.step()
total_loss += loss.item() progress_bar.set_postfix({'loss': loss.item()})
print(f"Epoch {epoch + 1} - Avg Loss: {total_loss / len(train_loader):.4f}")
# 简单的验证步骤:准确率 (Chosen分数是否大于Rejected分数) model.eval() correct = 0 total = 0 with torch.no_grad(): for batch in val_loader: batch = {k: v.to(DEVICE) for k, v in batch.items()}
r_chosen = model(input_ids=batch["input_ids_chosen"], attention_mask=batch["attention_mask_chosen"]).logits r_rejected = model(input_ids=batch["input_ids_rejected"], attention_mask=batch["attention_mask_rejected"]).logits
# 如果 Good > Bad,则预测正确 correct += (r_chosen > r_rejected).sum().item() total += r_chosen.size(0)
acc = correct / total if total > 0 else 0 print(f"Validation Accuracy: {acc:.2%}") print("-" * 50)
# 4. 保存模型 print(f"Saving Reward Model to {SAVE_PATH}") model.save_pretrained(SAVE_PATH) tokenizer.save_pretrained(SAVE_PATH)
# 5. 测试打分 run_inference_test(model, tokenizer)
def run_inference_test(model, tokenizer): print("\nRunning Inference Test (Scoring)...") model.eval()
prompt = "Customer: I cannot access my account.\nAgent:"
# 两个假设的回答 good_response = " Please check if your caps lock is on and try resetting your password." bad_response = " I like pizza and the weather is nice today." # 完全不相关的回答
text_good = prompt + good_response text_bad = prompt + bad_response
with torch.no_grad(): # 打分 Good inputs_good = tokenizer(text_good, return_tensors="pt").to(DEVICE) score_good = model(**inputs_good).logits.item()
# 打分 Bad inputs_bad = tokenizer(text_bad, return_tensors="pt").to(DEVICE) score_bad = model(**inputs_bad).logits.item()
print(f"Prompt: {prompt.strip()}") print(f"Option A (Relevant): '{good_response.strip()}' -> Score: {score_good:.4f}") print(f"Option B (Random): '{bad_response.strip()}' -> Score: {score_bad:.4f}")
if score_good > score_bad: print("Result: Model correctly preferred Option A.") else: print("Result: Model failed to distinguish.")
if __name__ == "__main__": train_reward_model()2.5.4 PPO微调大模型
Section titled “2.5.4 PPO微调大模型”第三阶段,实现RLHF的核心过程——通过强化学习微调大模型。这一阶段的目标是利用前两个阶段所训练的SFT微调模型与奖励模型,在大模型的生成过程中不断优化其输出,使其更加符合人类偏好的需求。通过这个过程,大模型的行为会变得越来越符合用户的意图和需求。
2.5.4.1 实现流程
Section titled “2.5.4.1 实现流程”
-
actor model在推理模式下根据prompt生成answer
-
利用reward model和ciric model对输出的prompt+answer进行打分
-
将prompt+answer分别输入到actor mode和ref model,用KL散度来衡量 ref model和actor mode输出的差别。
-
奖励值综合考虑KL散度和reward模型的输出
-
根据奖励值以及critic model的打分,计算广义优势估计(GAE)
-
计算策略梯度损失(Policy Gradient Loss)
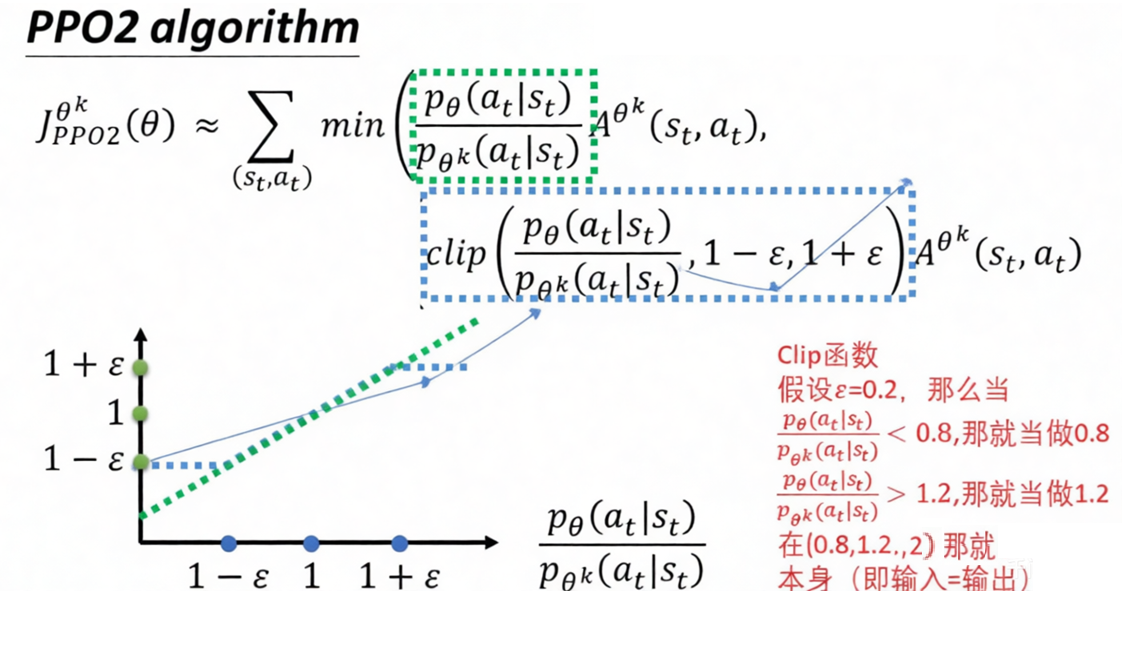
-
计算价值损失与熵损失, 加权求和得到最终损失
-
误差反向传播,更新actor model和critic model的模型参数
2.5.4.2 具体实现步骤
Section titled “2.5.4.2 具体实现步骤”一. 模型和数据准备阶段
-
加载预训练的SFT模型作为基础策略模型(Actor)和价值模型(Critic)
-
加载参考模型(Reference Model)用于KL散度计算
-
加载奖励模型(Reward Model)用于评估生成回复质量
-
准备客服对话数据集,提取客户提问作为Prompt
二. PPO主训练循环
步骤一:数据收集(Rollout)
- 使用PPOModel.generate生成客服回复
- 构造完整序列(Prompt + Response)
- 创建注意力掩码
步骤二:奖励计算
- 使用奖励模型对完整回复打分
- 计算参考模型和当前策略模型的对数概率
- 计算KL散度作为惩罚项
- 构造奖励序列:rewards = -BETA * kl_div
- 将奖励模型分数添加到序列结束位置
步骤三:优势函数计算
- 使用当前策略模型的Critic部分计算状态价值(old_values)
- 调用compute_gae计算广义优势估计(GAE)
- 进行优势归一化处理
步骤四:策略更新
- 多次迭代更新(UPDATE_EPOCHS)
- 重新前向传播计算新的logits和values
- 计算策略比率(ratio = exp(new_log - old_log))
- 计算PPO裁剪损失(Policy Loss)
- 计算价值函数损失(Value Loss)
- 计算熵损失(Entropy Loss)防止过拟合
- 综合三种损失进行反向传播和参数更新
三. 模型保存
- 训练完成后保存优化后的策略模型
- 仅保存LLM部分,不保存Value Head
代码文件:PPO_train.py
"""数据源:customer_support_data_samples.csv客服数据,仅提取 Customer 的提问作为 Prompt。模型加载: Actor (策略模型):SFT微调后的模型 customer_service_sft。 Critic (价值模型):在 SFT 模型基础上加一个 Value Head。 Ref Model (参考模型):加载 customer_service_sft 并冻结,用于计算 KL 散度。 Reward Model (奖励模型):使用 AutoModelForSequenceClassification 加载奖励模型customer_service_rm。奖励计算:调用 RM 模型进行预测。"""import torchfrom torch import nnimport numpy as npfrom transformers import AutoModelForCausalLM, AutoTokenizer, AutoModelForSequenceClassificationfrom datasets import load_datasetfrom torch.utils.data import DataLoader, Datasetimport osfrom tqdm import tqdm
# --- 超参数设置 ---# 路径配置SFT_MODEL_PATH = "./models/customer_service_sft"RM_MODEL_PATH = "./models/customer_service_rm"SAVE_PATH = "./models/customer_service_ppo"
# 训练参数 (已针对防崩塌优化)LEARNING_RATE = 1e-6 # PPO通常需要极小的学习率BATCH_SIZE = 4 # 这里的 Batch Size 是指 Prompt 的数量,显存敏感,因为要加载4个模型,所以设置的较小PPO_EPOCHS = 1 # 遍历数据集次数UPDATE_EPOCHS = 2 # 每次采集数据(Rollout)后,使用这些数据更新多少次参数MIN_RESPONSE_LENGTH = 15MAX_RESPONSE_LENGTH = 50 # 生成回复的最大长度CLIP_RANGE = 0.2 # PPO Clip范围BETA = 0.2 # KL 惩罚系数ENTROPY_COEF = 0.01 # 熵系数,防止复读机DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class ValueHead(nn.Module): """ 价值头:将Transformer的隐藏层状态映射为标量Value """
def __init__(self, config): super().__init__() self.hidden_size = config.hidden_size self.value = nn.Linear(self.hidden_size, 1) nn.init.normal_(self.value.weight, std=0.01) nn.init.zeros_(self.value.bias)
def forward(self, hidden_states): return self.value(hidden_states).squeeze(-1)
class PPOModel(nn.Module): """ Actor-Critic 联合模型 Actor: 生成文本 (CausalLM) Critic: 评估状态价值 (ValueHead) """
def __init__(self, model_path): super().__init__() # 加载 SFT 后的模型作为底座 self.llm = AutoModelForCausalLM.from_pretrained(model_path) self.v_head = ValueHead(self.llm.config)
def forward(self, input_ids, attention_mask): # 获取 transformer 输出 outputs = self.llm( input_ids=input_ids, attention_mask=attention_mask, output_hidden_states=True # 需要 Hidden States 计算 Value ) # Actor Logits: [Batch, Seq, Vocab] logits = outputs.logits # Critic Values: [Batch, Seq] # 取最后一层隐藏状态计算 Value last_hidden_state = outputs.hidden_states[-1] values = self.v_head(last_hidden_state) return logits, values
def generate(self, *args, **kwargs): return self.llm.generate(*args, **kwargs)
class PromptDataset(Dataset): """ 只加载 Customer 的提问作为 Prompt """
def __init__(self, tokenizer): self.tokenizer = tokenizer self.prompts = [] # 加载数据 dataset = load_dataset("csv", data_dir="./data", data_files="customer_support_data_samples.csv")['train']
# 提取 Prompt seen_prompts = set() for i in range(len(dataset)): if dataset['role'][i] == 'customer': text = dataset['text'][i] if text and text not in seen_prompts: # 构造符合 SFT 训练时的 Prompt 格式 fmt_prompt = f"Customer: {text}\nAgent:" self.prompts.append(fmt_prompt) seen_prompts.add(text)
print(f"Loaded {len(self.prompts)} unique prompts for PPO.")
def __len__(self): return len(self.prompts)
def __getitem__(self, idx): # 此时只返回文本,Tokenize 在 Collate 或 Loop 中做 return self.prompts[idx]
def get_log_probs(logits, labels): """ 计算生成序列的 Log Probability """ log_probs = torch.nn.functional.log_softmax(logits, dim=-1) # 从模型输出的完整词汇表概率分布中,提取实际标签(labels)对应的对数概率值。 # 例: # log_probs (vocab_size=4): # [[[0.1, 0.2, 0.3, 0.4]], [[0.4, 0.3, 0.2, 0.1]]]
# labels: # [[2], [0]]
# gather 结果: # [[[0.3]], [[0.4]]] log_probs_labels = log_probs.gather(dim=-1, index=labels.unsqueeze(-1)) return log_probs_labels.squeeze(-1)
def compute_gae(rewards, values, masks, gamma=0.99, lam=0.95): """ 计算广义优势估计 (GAE) - PPO 的核心数学部分 """ # 将价值函数值乘以掩码,忽略无效位置的值 values = values * masks # 初始化优势函数数组,与奖励张量形状相同 advs = torch.zeros_like(rewards).to(DEVICE) # 初始化最后一步的GAE值为0 last_gae = 0 # 获取序列长度 seq_len = rewards.shape[1] # 逆序遍历时间步,从最后一步开始计算GAE for t in reversed(range(seq_len)): # 如果是最后一步,则下一个状态的价值为0 if t == seq_len - 1: next_value = 0 # 否则使用下一步的价值估计 else: next_value = values[:, t + 1] # 计算TD误差: δ_t = r_t + γ*V(s_{t+1}) - V(s_t) delta = rewards[:, t] + gamma * next_value - values[:, t] # 计算GAE: A_t = δ_t + γ*λ*A_{t+1} last_gae = delta + gamma * lam * last_gae # 将计算得到的优势值存储,并应用掩码 advs[:, t] = last_gae * masks[:, t] # 计算回报值: R_t = A_t + V(s_t) returns = advs + values # 返回优势函数值和回报值 return advs, returns
def train_ppo(): print("Loading models...") tokenizer = AutoTokenizer.from_pretrained(SFT_MODEL_PATH) tokenizer.pad_token = tokenizer.eos_token # 生成任务使用左填充,[Pad, Pad, Prompt] # 模型看到的最后一个词是 Prompt 的结尾,于是能正常续写。 tokenizer.padding_side = "left"
# 1. 正在训练的模型 (Actor + Critic),策略模型 + 价值头 model = PPOModel(SFT_MODEL_PATH).to(DEVICE)
# 2. 参考模型 (Reference Model) - 用于计算 KL 散度,防止模型跑偏 # 为了节省显存,可以加载 float16 或量化版本 ref_model = AutoModelForCausalLM.from_pretrained(SFT_MODEL_PATH).to(DEVICE) ref_model.eval() for param in ref_model.parameters(): param.requires_grad = False
# 3. 奖励模型 (Reward Model) - 你的判分器 # 注意:这里直接加载 AutoModelForSequenceClassification reward_model = AutoModelForSequenceClassification.from_pretrained( RM_MODEL_PATH, num_labels=1 ).to(DEVICE) reward_model.eval() for param in reward_model.parameters(): param.requires_grad = False # 数据准备 dataset = PromptDataset(tokenizer) dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
optimizer = torch.optim.AdamW(model.parameters(), lr=LEARNING_RATE)
print(f"Starting PPO Training (Batch={BATCH_SIZE})...")
for epoch in range(PPO_EPOCHS): progress_bar = tqdm(dataloader, desc=f"Epoch {epoch + 1}")
for batch_prompts in progress_bar: # --- 步骤 1: Rollout (生成数据) --- # 这里的 batch_prompts 是文本列表 ["Customer: xxx\nAgent:", ...] inputs = tokenizer(batch_prompts, return_tensors="pt", padding=True, truncation=True, max_length=128).to( DEVICE) prompt_len = inputs['input_ids'].shape[1]
# --- 步骤 2: Rollout (生成回复) --- with torch.no_grad(): # 使用 Actor 生成回复 model.eval() outputs = model.generate( **inputs, max_new_tokens=MAX_RESPONSE_LENGTH, do_sample=True, top_p=0.9, pad_token_id=tokenizer.eos_token_id, min_length=prompt_len + MIN_RESPONSE_LENGTH ) model.train() # 切换回训练模式准备更新
# 构造完整的序列 (Prompt + Response) # outputs 包含了 input_ids + generated_ids full_seqs = outputs # 创建注意力掩码,标记非填充位置为1,填充位置为0 # full_seqs != tokenizer.pad_token_id: 生成布尔张量,非填充token位置为True,填充位置为False # .long(): 将布尔值转换为整数(1表示True,0表示False),形成标准的注意力掩码格式 attention_mask = (full_seqs != tokenizer.pad_token_id).long()
# --- 步骤 3: 计算奖励 (Reward + KL) --- with torch.no_grad(): # 3.1 RM 打分 # RM 接收完整的句子 rm_outputs = reward_model(input_ids=full_seqs, attention_mask=attention_mask) # RM分数 rm_scores = rm_outputs.logits.squeeze(-1) # [BATCH]
# 3.2 Ref LogProbs (用于计算 Reward 中的 KL 惩罚) ref_outputs = ref_model(input_ids=full_seqs, attention_mask=attention_mask) ref_logits = ref_outputs.logits
# 3.3 # 需要再跑一次当前模型,获取 Logits 和 Values,这个old_values就是critic模型的打分,用于计算GAE old_logits, old_values = model(full_seqs, attention_mask)
# 对齐 Logits 和 Labels [B, Seq-1] # logits[:, :-1, :] # 含义:取logits张量的前sequence_length - 1个位置 # 维度:[batch_size, sequence_length - 1, vocab_size] # 目的:获取模型对每个位置的预测分布(除了最后一个位置) # full_seqs[:, 1:] # 含义:取 full_seqs 张量的后 sequence_length - 1 个位置 # 维度:[batch_size, sequence_length-1] # 目的:获取目标标签序列(除了第一个位置),这是因为因果语言模型,位置t的输入预测t+1的token,所以要错位多起,例如: # 输入序列: [token_0, token_1, token_2, ..., token_{T - 1}] # 目标标签: [token_1, token_2, token_3, ..., token_T] old_log_probs = get_log_probs(old_logits[:, :-1, :], full_seqs[:, 1:]) ref_log_probs = get_log_probs(ref_logits[:, :-1, :], full_seqs[:, 1:])
# 3.4 计算 KL 散度 kl_div = old_log_probs - ref_log_probs
# 3.5 构造 Reward 序列 # PPO 通常是: Reward = -Beta * KL + RM_Score(只加在最后) rewards = -BETA * kl_div
# 将 RM 分数加到每个句子的结束位置 # 注意:full_seqs 包含 padding,我们需要找到每个样本真实的最后一个 token for i in range(len(batch_prompts)): # 寻找生成的 EOS 位置 gen_seq = full_seqs[i, prompt_len:] eos_indices = (gen_seq == tokenizer.eos_token_id).nonzero(as_tuple=True)[0] if len(eos_indices) > 0: end_idx = eos_indices[0].item() + prompt_len - 1 else: end_idx = rewards.shape[1] - 1
# 防止越界 end_idx = min(end_idx, rewards.shape[1] - 1)
# 裁剪 RM 分数防止数值不稳定 # clamp()将每个元素值限制在-5到5范围内 score = torch.clamp(rm_scores[i], -5, 5) # 将裁剪后的奖励模型分数累加到指定位置的奖励序列中 # rewards[i, end_idx]: 第i个样本在end_idx位置的奖励值 # score: 经过裁剪的奖励模型输出分数 rewards[i, end_idx] += score
# 创建一个训练掩码 Train Mask,用于标识哪些位置的tokens需要参与训练计算。 # attention_mask 的长度与 full_seqs 相同,但在计算 log_probs 时,使用的是 logits[:, :-1, :] 和 full_seqs[:, 1:] 进行对齐 # 因此需要将 attention_mask 也进行相同的切片操作 [:, 1:] 来保持维度一致 train_mask = attention_mask[:, 1:].clone() # 将提示部分 mask 掉 train_mask[:, :prompt_len - 1] = 0
# 3.6 计算 GAE (优势函数) # # values 需要切片对齐 [B, Seq-1], 并且使用 detach 确保不传梯度 old_values = old_values[:, :-1].detach() advantages, returns = compute_gae(rewards, old_values, train_mask)
# Advantage Normalization advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
# --- 步骤 4: PPO 更新循环 ---
# Detach 变量防止梯度重复计算 old_log_probs = old_log_probs.detach() advantages = advantages.detach() returns = returns.detach()
for _ in range(UPDATE_EPOCHS): # 重新前向传播 (这是 PPO On-Policy 的要求) new_logits, new_values = model(full_seqs, attention_mask) new_log_probs = get_log_probs(new_logits[:, :-1, :], full_seqs[:, 1:]) new_values = new_values[:, :-1]
# 计算 Ratio # ratio = exp(new_log - old_log) # 只计算 train_mask 为 1 的部分 log_ratio = (new_log_probs - old_log_probs) * train_mask ratio = torch.exp(log_ratio)
# Policy Gradient Loss (PPO Clip) pg_loss1 = -advantages * ratio pg_loss2 = -advantages * torch.clamp(ratio, 1.0 - CLIP_RANGE, 1.0 + CLIP_RANGE) pg_loss = torch.max(pg_loss1, pg_loss2) pg_loss_val = (pg_loss * train_mask).sum() / (train_mask.sum() + 1e-8)
# Value Loss v_loss = (new_values - returns) ** 2 v_loss_val = (v_loss * train_mask).sum() / (train_mask.sum() + 1e-8)
# Entropy Loss (防止复读机) probs = torch.softmax(new_logits[:, :-1, :], dim=-1) entropy = -(probs * torch.log(probs + 1e-9)).sum(dim=-1) entropy_loss = -ENTROPY_COEF * (entropy * train_mask).sum() / (train_mask.sum() + 1e-8)
# 总 Loss loss = pg_loss_val + 0.5 * v_loss_val + entropy_loss
optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5) # 严格的梯度裁剪 optimizer.step()
progress_bar.set_postfix({ 'reward': f"{rm_scores.mean().item():.2f}", 'loss': f"{loss.item():.4f}", 'kl': f"{kl_div.mean().item():.4f}" })
# 清理显存 del inputs, outputs, full_seqs, new_logits, old_logits torch.cuda.empty_cache()
print(f"Saving PPO model to {SAVE_PATH}") # 只保存 LLM 部分,Value Head 不需要保存用于推理 model.llm.save_pretrained(SAVE_PATH) tokenizer.save_pretrained(SAVE_PATH)
if __name__ == "__main__": train_ppo()2.5.5 验证PPO微调后的大模型
Section titled “2.5.5 验证PPO微调后的大模型”准备测试用例,查看PPO微调后大模型的生成结果
代码文件:valid_model.py
import torchfrom transformers import AutoModelForCausalLM, AutoTokenizerimport os
# --- 配置路径 ---PPO_MODEL_PATH = "./models/customer_service_ppo" # 请确保此路径与你保存PPO模型的路径一致DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# --- 测试用例 ---TEST_CASES = [ "Hello, my SSO is not working as expected.", "I can’t log in. It says account locked.", "Your product is terrible! I want a refund now."]
def generate_response(model, tokenizer, text, model_name="Model"): """ 通用的推理生成函数 """ prompt = f"Customer: {text}\nAgent:" inputs = tokenizer(prompt, return_tensors="pt").to(DEVICE)
with torch.no_grad(): outputs = model.generate( **inputs, max_new_tokens=100, # 最大生成长度 min_new_tokens=10, # 最小生成长度 do_sample=True, # 开启采样 temperature=0.7, # 控制创造性 (PPO通常需要稍微低一点的温度以保持稳定) top_p=0.9, pad_token_id=tokenizer.eos_token_id, eos_token_id=tokenizer.eos_token_id, repetition_penalty=1.2, # 惩罚重复,防止复读机 )
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
# --- 后处理截断 --- # 提取 Agent 回复部分 try: # 截取 "Agent:" 之后的内容 response = generated_text.split("Agent:")[-1].strip() # 再次截断,防止模型自己生成下一轮的 "Customer:" 或换行 if "Customer:" in response: response = response.split("Customer:")[0].strip() if "\n" in response: response = response.split("\n")[0].strip() except IndexError: response = generated_text
print(f"\n[Customer]: {text}") print(f"[Agent ({model_name})]: {response}") print("-" * 30)
def valid_ppo(): """ 加载并测试 PPO 模型 """ print(f"\n>>> Loading PPO model from {PPO_MODEL_PATH}...") if not os.path.exists(PPO_MODEL_PATH): print(f"错误:路径 {PPO_MODEL_PATH} 不存在。请检查保存路径。") return
try: tokenizer = AutoTokenizer.from_pretrained(PPO_MODEL_PATH) model = AutoModelForCausalLM.from_pretrained(PPO_MODEL_PATH).to(DEVICE) model.eval()
print("=" * 50) print("PPO Model Inference Test") print("=" * 50)
for text in TEST_CASES: generate_response(model, tokenizer, text, model_name="PPO")
# 释放显存 del model, tokenizer torch.cuda.empty_cache()
except Exception as e: print(f"加载 PPO 模型出错: {e}")
if __name__ == "__main__": valid_ppo()三、智能客服对话偏好对齐(GRPO算法)
Section titled “三、智能客服对话偏好对齐(GRPO算法)”学习目标:
1.完成基于GRPO算法的大模型微调
3.1 GRPO的优势
Section titled “3.1 GRPO的优势”前边,我们通过PPO算法微调了大模型,PPO算法通过优化策略更新的范围,确保每一步更新不会过于激进,从而实现稳定的训练。然而,PPO在某些情况下可能存在训练过程中的策略收敛问题,特别是在处理大模型时,可能导致学习效率较低。
GRPO是对PPO的一种扩展,它在PPO的基础上引入了更强的正则化机制,目的是避免策略更新过于剧烈,增强学习的稳定性,尤其在大模型和复杂任务中表现得更为突出。GRPO通过正则化来对策略进行限制,使得策略的变化更加平滑,从而在多轮更新过程中保持更高的稳定性和收敛性。
GRPO的特点与优势
- 正则化增强稳定性 GRPO通过引入正则化项,控制策略变化的幅度,从而避免策略过于剧烈的更新,确保训练过程更加稳定,尤其是在处理复杂或大型模型时。
- 提高样本效率 与PPO相比,GRPO通常能更高效地利用样本。在某些环境中,GRPO能够通过正则化调整学习过程,使得每个训练步骤的效果更加明显,从而加快收敛速度。
- 避免过拟合问题 由于正则化的作用,GRPO有助于避免模型在训练过程中过拟合训练数据,保持更好的泛化能力,尤其在面对多样化的用户行为和数据时,能够保持较高的性能。
- 适应性更强 GRPO在面对不同类型的任务时,能够更好地适应变化的环境需求。在客服对话类任务中,用户的需求和意图变化较大,GRPO通过更稳定的训练方式,有助于提高模型的灵活性和适应性。
因此,接下来,我们使用GRPO算法来微调大模型,前边的步骤都一样,区别是第三阶段,改为GRPO算法微调大模型。‘
3.2 GRPO微调方案
Section titled “3.2 GRPO微调方案”数据源:customer_support_data_samples.csv模型加载: Policy Model (策略模型):SFT微调后的模型 (不再需要 Critic/ValueHead)。 Ref Model (参考模型):SFT微调后的模型,冻结参数。 Reward Model (奖励模型):AutoModelForSequenceClassification,用于打分。算法变更: PPO -> GRPO 核心差异:移除 Value Head,对同一 Prompt 生成多条回复 (Group), 使用组内归一化奖励 (Group Relative Reward) 作为 Advantage。3.3 代码实现GRPO微调大模型
Section titled “3.3 代码实现GRPO微调大模型”实现步骤如下:
一. 模型和数据准备阶段
- 加载预训练的 SFT 模型作为基础策略模型(GRPOModel)
- 加载参考模型(Ref Model)用于 KL 散度计算
- 加载奖励模型(Reward Model)用于评估生成回复质量
- 准备客服对话数据集,提取客户提问作为 Prompt
二. GRPO 主训练循环
步骤一:输入扩展(Input Expansion)
- 将每个 Prompt 重复 GROUP_SIZE 次,例如 [P1, P2] -> [P1, P1, P1, P1, P2, P2, P2, P2]
步骤二:数据收集(Rollout)
- 使用 GRPOModel.generate 生成客服回复
- 开启采样(do_sample=True)确保同一 Prompt 生成多样回复
- 构造完整序列(Prompt + Response)
- 创建注意力掩码
步骤三:奖励计算与组归一化
- 使用奖励模型对所有生成回复打分
- 计算参考模型的对数概率用于 KL 计算
- 核心步骤:组内归一化(Group Normalization)
- 将分数 reshape 为 [BATCH, GROUP]
- 计算每组内的均值和标准差
- 归一化:(Score - Mean) / Std 得到优势函数
步骤四:策略更新
- 计算当前策略的对数概率
- 计算策略比率(ratio = exp(new_log - old_log))
- 计算近似 KL 散度(token_kl = (new_log_probs - ref_log_probs))
- 构造 GRPO 损失函数:
- Loss = E[min(ratio * A, clip(ratio) * A) - Beta * KL]
- 将序列级别优势扩展到 token 级别
- 进行反向传播和参数更新
三. 模型保存
- 训练完成后保存优化后的策略模型到 SAVE_PATH
代码文件:GRPO_train.py
"""数据源:customer_support_data_samples.csv模型加载: Policy Model (策略模型):SFT微调后的模型 (不再需要 Critic/ValueHead)。 Ref Model (参考模型):SFT微调后的模型,冻结参数。 Reward Model (奖励模型):AutoModelForSequenceClassification,用于打分。算法变更: PPO -> GRPO 核心差异:移除 Value Head,对同一 Prompt 生成多条回复 (Group), 使用组内归一化奖励 (Group Relative Reward) 作为 Advantage。"""import torchfrom torch import nnimport numpy as npfrom transformers import AutoModelForCausalLM, AutoTokenizer, AutoModelForSequenceClassificationfrom datasets import load_datasetfrom torch.utils.data import DataLoader, Datasetimport randomimport osimport gcfrom tqdm import tqdm
# --- 超参数设置 ---# 路径配置SFT_MODEL_PATH = "./models/customer_service_sft"RM_MODEL_PATH = "./models/customer_service_rm"SAVE_PATH = "./models/customer_service_grpo" # 修改保存路径
# 训练参数LEARNING_RATE = 5e-7 # GRPO 通常需要较小学习率BATCH_SIZE = 2 # 这里的 Batch Size 是指 Prompt 的数量GROUP_SIZE = 4 # 关键参数:每个 Prompt 生成多少个回答 (Total Batch = BATCH_SIZE * GROUP_SIZE)# 显存警告:实际处理的并发数是 BATCH_SIZE * GROUP_SIZE = 8GRPO_EPOCHS = 1UPDATE_EPOCHS = 1 # 每次采集数据后,使用这些数据更新多少次参数MIN_RESPONSE_LENGTH = 15MAX_RESPONSE_LENGTH = 50CLIP_RANGE = 0.2BETA = 0.01 # KL 散度在 Loss 中的权重DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class GRPOModel(nn.Module): """ GRPO 只需要策略模型 (Actor),不需要 Value Head """
def __init__(self, model_path): super().__init__() self.llm = AutoModelForCausalLM.from_pretrained(model_path) # 启用梯度检查点以节省显存 (可选) # self.llm.gradient_checkpointing_enable()
def forward(self, input_ids, attention_mask): outputs = self.llm( input_ids=input_ids, attention_mask=attention_mask, output_hidden_states=False # 不需要 hidden states ) return outputs.logits
def generate(self, *args, **kwargs): return self.llm.generate(*args, **kwargs)
class PromptDataset(Dataset): """ 只加载 Customer 的提问作为 Prompt """
def __init__(self, tokenizer): self.tokenizer = tokenizer self.prompts = []
# 加载数据 dataset = load_dataset("csv", data_dir="./data", data_files="customer_support_data_samples.csv")['train']
seen_prompts = set() for i in range(len(dataset)): if dataset['role'][i] == 'customer': text = dataset['text'][i] if text and text not in seen_prompts: fmt_prompt = f"Customer: {text}\nAgent:" self.prompts.append(fmt_prompt) seen_prompts.add(text)
print(f"Loaded {len(self.prompts)} unique prompts for GRPO.")
def __len__(self): return len(self.prompts)
def __getitem__(self, idx): return self.prompts[idx]
def get_log_probs(logits, labels): """ 计算生成序列的 Log Probability """ # logits: [B, Seq, Vocab] # labels: [B, Seq] log_probs = torch.nn.functional.log_softmax(logits, dim=-1) log_probs_labels = log_probs.gather(dim=-1, index=labels.unsqueeze(-1)) return log_probs_labels.squeeze(-1)
# --- 主训练流程 ---
def train_grpo(): print("Loading models...") tokenizer = AutoTokenizer.from_pretrained(SFT_MODEL_PATH) tokenizer.pad_token = tokenizer.eos_token
# 生成任务使用左填充,[Pad, Pad, Prompt] # 模型看到的最后一个词是 Prompt 的结尾,于是能正常续写。 tokenizer.padding_side = "left" # 1. 策略模型 (Policy Model) - 只需要加载一个 LLM model = GRPOModel(SFT_MODEL_PATH).to(DEVICE)
# 2. 参考模型 (Reference Model) ref_model = AutoModelForCausalLM.from_pretrained(SFT_MODEL_PATH).to(DEVICE) ref_model.eval() for param in ref_model.parameters(): param.requires_grad = False
# 3. 奖励模型 (Reward Model) reward_model = AutoModelForSequenceClassification.from_pretrained( RM_MODEL_PATH, num_labels=1 ).to(DEVICE) reward_model.eval() for param in reward_model.parameters(): param.requires_grad = False
# 数据准备 dataset = PromptDataset(tokenizer) dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
optimizer = torch.optim.AdamW(model.parameters(), lr=LEARNING_RATE)
print(f"Starting GRPO Training (Batch={BATCH_SIZE}, Group={GROUP_SIZE})...")
for epoch in range(GRPO_EPOCHS): progress_bar = tqdm(dataloader, desc=f"Epoch {epoch + 1}")
for batch_prompts in progress_bar: # batch_prompts len = BATCH_SIZE (例如 2)
# --- 步骤 1: Input Expansion (Group 生成) --- # 将每个 Prompt 重复 GROUP_SIZE 次 # 例如: [P1, P2] -> [P1, P1, P1, P1, P2, P2, P2, P2]
expanded_prompts = [] for p in batch_prompts: expanded_prompts.extend([p] * GROUP_SIZE)
inputs = tokenizer(expanded_prompts, return_tensors="pt", padding=True, truncation=True, max_length=128).to( DEVICE) prompt_len = inputs['input_ids'].shape[1]
# --- 步骤 2: Rollout (生成回复) --- with torch.no_grad(): model.eval() # 这里会同时生成 BATCH * GROUP 个序列 outputs = model.generate( **inputs, max_new_tokens=MAX_RESPONSE_LENGTH, do_sample=True, # GRPO 必须开启采样,否则同一个 Prompt 生成的 Group 是一样的 temperature=0.9, # 增加多样性 top_p=0.9, pad_token_id=tokenizer.eos_token_id, min_length=prompt_len + MIN_RESPONSE_LENGTH ) model.train()
full_seqs = outputs attention_mask = (full_seqs != tokenizer.pad_token_id).long()
# --- 步骤 3: 奖励计算 & Group Normalization --- with torch.no_grad(): # 3.1 计算原始分数 rm_outputs = reward_model(input_ids=full_seqs, attention_mask=attention_mask) rm_scores = rm_outputs.logits.squeeze(-1) # [BATCH * GROUP] # 3.2 计算参考模型 LogProbs (用于 Loss 中的 KL 计算) ref_outputs = ref_model(input_ids=full_seqs, attention_mask=attention_mask) ref_logits = ref_outputs.logits ref_log_probs = get_log_probs(ref_logits[:, :-1, :], full_seqs[:, 1:])
# 3.3 Group Normalization (核心逻辑) # 将分数 reshape 为 [BATCH, GROUP] # 例如: [s1_1, s1_2, s1_3, s1_4, s2_1, ...] scores_grouped = rm_scores.view(-1, GROUP_SIZE)
# 计算组内均值和标准差 mean_scores = scores_grouped.mean(dim=1, keepdim=True) std_scores = scores_grouped.std(dim=1, keepdim=True) + 1e-8 # 防止除零
# 归一化: (Score - Mean) / Std advantages_grouped = (scores_grouped - mean_scores) / std_scores
# 展平回 [BATCH * GROUP] advantages = advantages_grouped.view(-1)
# 生成 Mask (只计算生成部分) train_mask = attention_mask[:, 1:].clone() train_mask[:, :prompt_len - 1] = 0
# --- 步骤 4: GRPO 更新循环 ---
# 预先计算旧策略的 LogProbs (Old Policy) with torch.no_grad(): old_logits = model(full_seqs, attention_mask) # 对齐 Logits 和 Labels [B, Seq-1] # logits[:, :-1, :] # 含义:取logits张量的前sequence_length - 1个位置 # 维度:[batch_size, sequence_length - 1, vocab_size] # 目的:获取模型对每个位置的预测分布(除了最后一个位置) # full_seqs[:, 1:] # 含义:取 full_seqs 张量的后 sequence_length - 1 个位置 # 维度:[batch_size, sequence_length-1] # 目的:获取目标标签序列(除了第一个位置),这是因为因果语言模型,位置t的输入预测t+1的token,所以要错位多起,例如: # 输入序列: [token_0, token_1, token_2, ..., token_{T - 1}] # 目标标签: [token_1, token_2, token_3, ..., token_T] old_log_probs = get_log_probs(old_logits[:, :-1, :], full_seqs[:, 1:])
for _ in range(UPDATE_EPOCHS): # 前向传播 Current Policy new_logits = model(full_seqs, attention_mask) new_log_probs = get_log_probs(new_logits[:, :-1, :], full_seqs[:, 1:])
# 计算 Ratio log_ratio = (new_log_probs - old_log_probs) * train_mask ratio = torch.exp(log_ratio)
# 计算 Approximate KL (用于 Loss) # KL = exp(log_p - log_ref) - (log_p - log_ref) - 1 (Schulman estimator) # 或者简单的 log_p - log_ref # 这里使用最简单的 per-token KL: log_p - log_ref token_kl = (new_log_probs - ref_log_probs) * train_mask
# GRPO Loss 公式 # Loss = E [ min(ratio * A, clip(ratio) * A) - Beta * KL ] # 注意:Advantage 需要扩展到每个 Token,虽然每个 Token 的 A 是一样的
# 将 sequence-level advantage 扩展到 token-level # advantages: [Batch*Group] -> [Batch*Group, 1] batch_adv = advantages.unsqueeze(1) # Policy Gradient Loss (GRPO Clip) pg_loss1 = -batch_adv * ratio pg_loss2 = -batch_adv * torch.clamp(ratio, 1.0 - CLIP_RANGE, 1.0 + CLIP_RANGE) pg_loss = torch.max(pg_loss1, pg_loss2)
# 加入 KL 惩罚 (DeepSeek 方式是把 KL 放在 Loss 里,而不是 Reward 里) # D_KL 是正数,我们希望最小化它,所以 Loss += Beta * KL kl_loss = BETA * token_kl
# 总 Loss loss = (pg_loss + kl_loss) * train_mask loss = loss.sum() / train_mask.sum()
optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step()
progress_bar.set_postfix({ 'reward_mean': rm_scores.mean().item(), 'loss': loss.item(), 'group_std': std_scores.mean().item() # 监控组内差异,太小说明模型崩塌(Mode Collapse) })
# 清理显存 del inputs, outputs, full_seqs, new_logits, ref_logits torch.cuda.empty_cache()
print(f"Saving GRPO model to {SAVE_PATH}") model.llm.save_pretrained(SAVE_PATH) tokenizer.save_pretrained(SAVE_PATH)
if __name__ == "__main__": train_grpo()3.4 验证GRPO微调后的大模型
Section titled “3.4 验证GRPO微调后的大模型”准备测试用例,查看PPO微调后大模型的生成结果
代码文件:valid_model.py
import torchfrom transformers import AutoModelForCausalLM, AutoTokenizerimport os
# --- 配置路径 ---GRPO_MODEL_PATH = "./models/customer_service_grpo"PPO_MODEL_PATH = "./models/customer_service_ppo" # 请确保此路径与你保存PPO模型的路径一致DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# --- 测试用例 ---TEST_CASES = [ "Hello, my SSO is not working as expected.", "I can’t log in. It says account locked.", "Your product is terrible! I want a refund now."]
def generate_response(model, tokenizer, text, model_name="Model"): """ 通用的推理生成函数 """ prompt = f"Customer: {text}\nAgent:" inputs = tokenizer(prompt, return_tensors="pt").to(DEVICE)
with torch.no_grad(): outputs = model.generate( **inputs, max_new_tokens=100, # 最大生成长度 min_new_tokens=10, # 最小生成长度 do_sample=True, # 开启采样 temperature=0.7, # 控制创造性 (PPO通常需要稍微低一点的温度以保持稳定) top_p=0.9, pad_token_id=tokenizer.eos_token_id, eos_token_id=tokenizer.eos_token_id, repetition_penalty=1.2, # 惩罚重复,防止复读机 )
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
# --- 后处理截断 --- # 提取 Agent 回复部分 try: # 截取 "Agent:" 之后的内容 response = generated_text.split("Agent:")[-1].strip() # 再次截断,防止模型自己生成下一轮的 "Customer:" 或换行 if "Customer:" in response: response = response.split("Customer:")[0].strip() if "\n" in response: response = response.split("\n")[0].strip() except IndexError: response = generated_text
print(f"\n[Customer]: {text}") print(f"[Agent ({model_name})]: {response}") print("-" * 30)
def valid_grpo(): """ 加载并测试 GRPO 模型 """ print(f"\n>>> Loading GRPO model from {GRPO_MODEL_PATH}...") if not os.path.exists(GRPO_MODEL_PATH): print(f"错误:路径 {GRPO_MODEL_PATH} 不存在。") return
try: tokenizer = AutoTokenizer.from_pretrained(GRPO_MODEL_PATH) model = AutoModelForCausalLM.from_pretrained(GRPO_MODEL_PATH).to(DEVICE) model.eval()
print("=" * 50) print("GRPO Model Inference Test") print("=" * 50)
for text in TEST_CASES: generate_response(model, tokenizer, text, model_name="GRPO")
# 释放显存 del model, tokenizer torch.cuda.empty_cache()
except Exception as e: print(f"加载 GRPO 模型出错: {e}")
def valid_ppo(): """ 加载并测试 PPO 模型 """ print(f"\n>>> Loading PPO model from {PPO_MODEL_PATH}...") if not os.path.exists(PPO_MODEL_PATH): print(f"错误:路径 {PPO_MODEL_PATH} 不存在。请检查保存路径。") return
try: tokenizer = AutoTokenizer.from_pretrained(PPO_MODEL_PATH) model = AutoModelForCausalLM.from_pretrained(PPO_MODEL_PATH).to(DEVICE) model.eval()
print("=" * 50) print("PPO Model Inference Test") print("=" * 50)
for text in TEST_CASES: generate_response(model, tokenizer, text, model_name="PPO")
# 释放显存 del model, tokenizer torch.cuda.empty_cache()
except Exception as e: print(f"加载 PPO 模型出错: {e}")
if __name__ == "__main__": valid_ppo() valid_grpo()