
RAG系统项目介绍
基于企业私有数据搭建RAG系统
Section titled “基于企业私有数据搭建RAG系统”- 了解项目开发背景
- 掌握融合本地知识的RAG系统实现过程
1 背景介绍
Section titled “1 背景介绍”近年来,随着ChatGPT的广泛应用,基于大规模语言模型(LLM)的技术已成为人工智能领域的研究和应用热点。尤其是大模型在各类自然语言处理任务中的成功应用,推动了教育行业的智能化转型。然而,当前市面上大多数大语言模型存在一个普遍的问题:这些模型主要依赖于过往的训练数据,无法动态获取最新的知识以及各企业特有的私有知识。这种局限性常常导致生成答案时出现“幻觉”问题,即模型提供的答案与实际情况不符或不准确。
为了有效解决这一问题,企业普遍采用了以下两种主要手段:
- 基于企业私有知识的垂直领域微调:通过将企业领域的特定知识融合到大模型中,进行微调,使得模型能够更好地服务于垂直行业的专业需求。
- 基于企业私有知识的RAG(Retrieval-Augmented Generation)问答系统:通过构建基于检索的问答框架,结合企业私有知识库,实现更为精准且动态更新的知识问答服务,从而减少幻觉问题的发生。
在此背景下,某在线教育平台通过采用**LangChain**和**Qwen大模型**,构建了一套智能化的学科在线答疑系统。该系统基于RAG架构,能够通过实时检索相关知识库中的信息来增强大模型的生成能力,确保回答的准确性和时效性。与此同时,系统通过自动化处理学生的答疑需求,极大地减轻了人工客服的工作压力,从而实现了高效、低成本的知识服务。
本课程将基于此RAG架构,带领学员深入了解如何使用LangChain和Qwen2.5-7B-Instruct大模型构建一个基于本地知识库的问答系统,解决企业在实际应用中的挑战,并展示这一系统在教育领域中的广泛应用潜力。
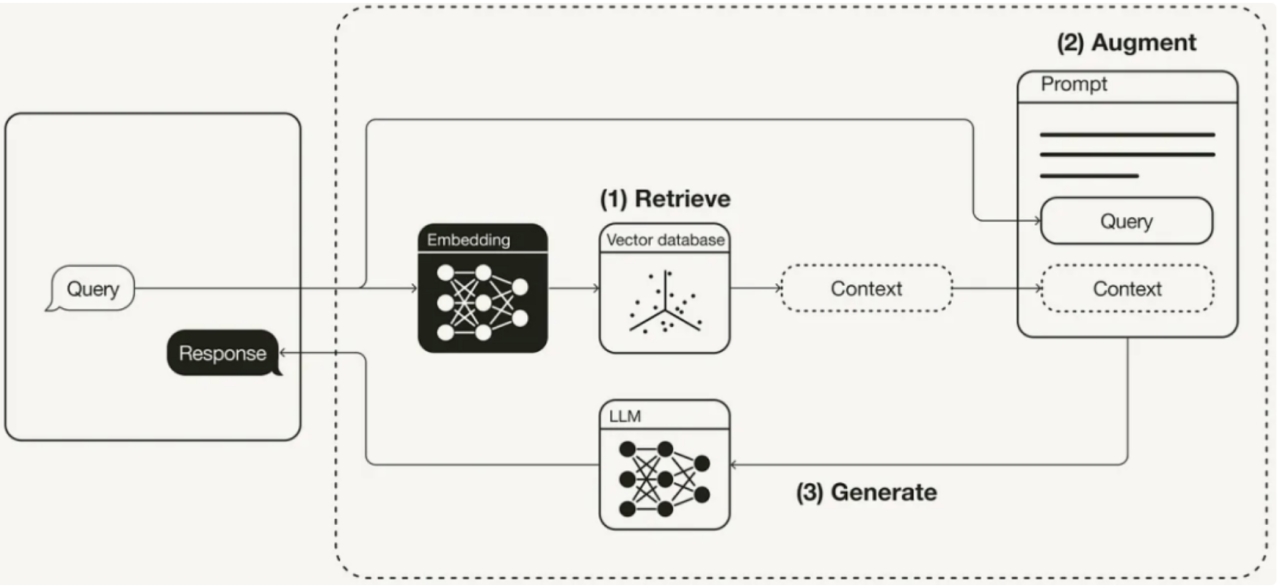
2 RAG原理
Section titled “2 RAG原理”RAG的基本原理:
3 项目流程
Section titled “3 项目流程”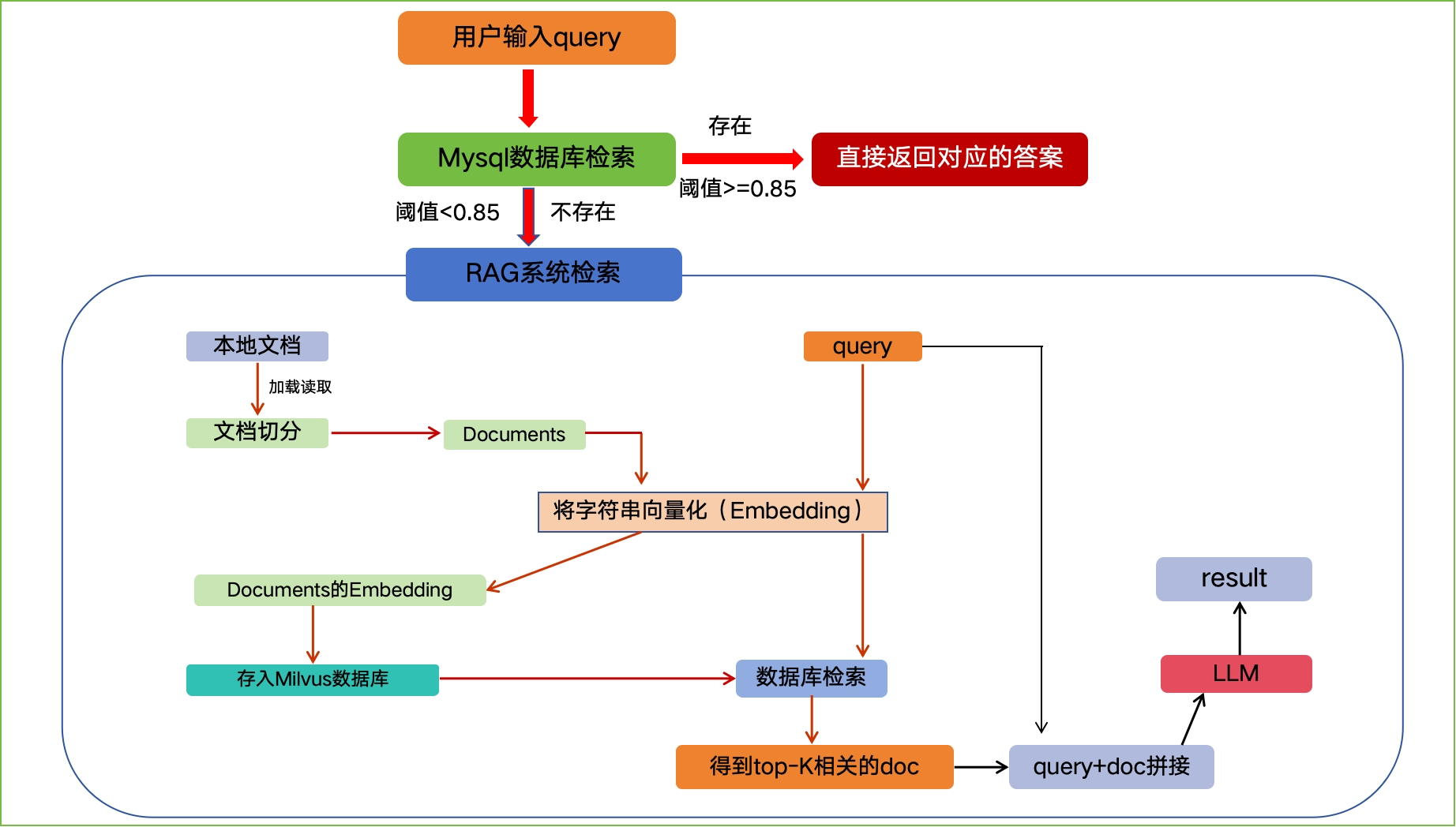
(AI)学科在线答疑系统RAG主要步骤:
- 第一步:将现有后台搜集的FQA数据集存储到Mysql数据库中
- 第二步:基于query实现Mysql数据库检索:将query和现有问题匹配(做相似度计算),如果阈值>=0.85,就认为问题比较明确,直接返回对应的答案;否则,进入RAG检索系统
- 第三步:搭建本地知识库:对本地文档加载读取;进行文档分割;文档向量化;存储向量数据库(Milvus)
- 第四步:基于query实现Milvus数据库检索:将query进行向量表示,并从Milvus数据库中检索出相似的top-k个文本段。
- 第五步:将query和检索出的top-k文本段拼接,送入大模型,实现预测。
4 项目结构
Section titled “4 项目结构”integrated_qa_system/├── config.ini # 配置文件,包含所有模块的配置├── base/│ ├── config.py # 配置管理,加载 config.ini│ ├── logger.py # 日志设置├── rag_qa/│ ├── core/│ │ ├── prompts.py # RAG 提示模板│ │ ├── query_classifier.py # 查询分类器│ │ ├── strategy_selector.py # 检索策略选择器│ │ ├── vector_store.py # 向量存储与检索│ │ ├── rag_system.py # RAG 系统核心逻辑│ ├── main.py # RAG 系统独立入口,支持存储和查询├── mysql_qa/│ ├── db/│ │ ├── mysql_client.py # MySQL 数据库操作│ ├── cache/│ │ ├── redis_client.py # Redis 缓存操作│ ├── retrieval/│ │ ├── bm25_search.py # BM25 搜索│ ├── utils/│ │ ├── preprocess.py # 文本预处理│ ├── main.py # MySQL 系统独立入口,支持查询├── main.py # 集成系统入口,结合 RAG 和 MySQL├── requirements.txt # 依赖文件└── logs/ └── app.log # 日志文件依赖文件 (requirements.txt)
Section titled “依赖文件 (requirements.txt)”# Web框架fastapiuvicorn[standard]websockets
# 数据库连接pymysqlredis
# 向量检索rank_bm25numpyjiebapandastransformerstorchlangchainlangchain_communitysentence_transformerspymilvus
# AI模型openai
# 配置和工具configparserlocustwebsocket-client
# 其他依赖pydanticstarlette5 环境配置
Section titled “5 环境配置”5.1 安装依赖
Section titled “5.1 安装依赖”- 首先,确保你的机器安装了Python3.10及其以上版本
# 终端查看python的版本python --version- 紧接着安装项目的依赖
# 安装全部依赖pip install -r requirements.txt5.2 工具的介绍
Section titled “5.2 工具的介绍”Ollama: 一个开源的大型语言模型服务工具,它帮助用户快速在本地运行大模型。
LangChain: 为各种LLMs实现通用的接口,把LLMs相关的组件“链接”在一起,简化LLMs应用的开发难度,方便开发者快速地开发复杂的LLMs应用。
Milvus: 一个开源向量数据库,帮助我们实现向量数据的存储和检索。
上述三种工具,我们将分别以独立的章节进行介绍
本章节主要介绍了基于企业私有知识搭建智能问答系统的基本流程;并对接下来的项目实现进行环境配置工作。