
批处理模块
发布于 2025-12-31
3.6 批处理模块
Section titled “3.6 批处理模块”一、模块介绍
Section titled “一、模块介绍”批处理模块用于批量处理大量的面试简历或者面试语音等场景, 基于已经发布的智能助手,通过Chat SDK调用并实现,如下图:
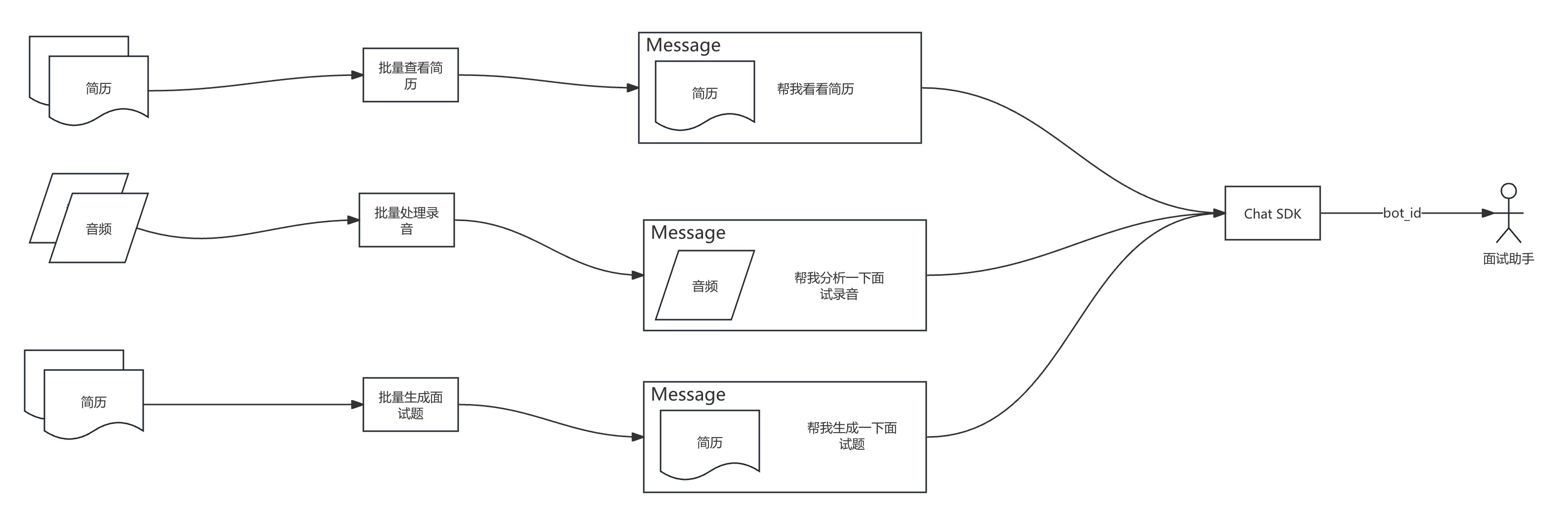
在这里我们需要做其实就是通过python代码循环遍历所有的文件,构造对应场景的Message,并实现内容生成。
二、批量查看简历
Section titled “二、批量查看简历”思路如下:
"""需求:使用CozeSDK实现简历评估批量处理功能思路步骤:1. 准备: 导入必要库,设置Coze API密钥、创建Coze客户端实例、指定机器人ID和用户ID2. 定义`upload_file`函数用于上传文件到Coze: 2.1 检查文件是否存在及文件大小是否符合限制 2.2 使用`cozepy`的`files.upload`方法上传文件,打印成功信息并返回文件响应对象,失败时返回None3. 定义`handle_resume`函数处理简历文件: 3.1 调用`upload_file`上传简历文件,若上传失败则返回 3.2 获取上传文件ID,构建发送给机器人的消息列表 3.3 流式调用Coze聊天API,处理流式响应事件,累积结果文本 3.4 将结果文本写入Markdown文件并返回4. 定义`handle_dir`函数批量处理文件夹中的简历文件: 4.1 验证输入目录是否存在且为目录 4.2 定义需要处理的文件扩展名列表 4.3 遍历目录中的所有文件,筛选出符合条件的文件格式 4.4 对每个符合条件的文件调用`handle_resume`函数处理 4.5 统计处理成功和失败的文件信息并返回"""代码实现:
"""需求:使用CozeSDK实现简历评估批量处理功能思路步骤:1. 准备: 导入必要库,设置Coze API密钥、创建Coze客户端实例、指定机器人ID和用户ID2. 定义`upload_file`函数用于上传文件到Coze: 2.1 检查文件是否存在及文件大小是否符合限制 2.2 使用`cozepy`的`files.upload`方法上传文件,打印成功信息并返回文件响应对象,失败时返回None3. 定义`handle_resume`函数处理简历文件: 3.1 调用`upload_file`上传简历文件,若上传失败则返回 3.2 获取上传文件ID,构建发送给机器人的消息列表 3.3 流式调用Coze聊天API,处理流式响应事件,累积结果文本 3.4 将结果文本写入Markdown文件并返回4. 定义`handle_dir`函数批量处理文件夹中的简历文件: 4.1 验证输入目录是否存在且为目录 4.2 定义需要处理的文件扩展名列表 4.3 遍历目录中的所有文件,筛选出符合条件的文件格式 4.4 对每个符合条件的文件调用`handle_resume`函数处理 4.5 统计处理成功和失败的文件信息并返回"""
# 导入必要的库和模块import jsonimport loggingimport osfrom pathlib import Pathfrom typing import Optional
from cozepy import COZE_CN_BASE_URL, ChatStatus, Coze, DeviceOAuthApp, Message, MessageContentType, TokenAuth, \ MessageObjectString, ChatEventType # noqa 忽略未使用的导入警告
# Coze API密钥,用于身份验证coze_api_token = 'token'
# 创建Coze客户端实例,使用TokenAuth进行身份验证,并指定中文API地址coze = Coze(auth=TokenAuth(token=coze_api_token), base_url=COZE_CN_BASE_URL)
# 在Coze中创建机器人实例,复制网页链接中的最后一个数字作为机器人ID[1](@ref)bot_id = "botid" # 直接指定机器人ID
# 用户ID用于标识用户身份,开发者可以使用自定义业务ID或随机字符串user_id = "userid"
def upload_file(file_path: str): """ 上传文件到Coze并返回文件信息[1,5](@ref) """ # 检查文件是否存在 if not os.path.exists(file_path): raise FileNotFoundError(f"文件不存在: {file_path}")
# 检查文件大小(Coze限制为512MB)[5](@ref) file_size = os.path.getsize(file_path) # 获取文件大小(字节) if file_size > 512 * 1024 * 1024: # 512MB限制检查 raise ValueError("文件大小超过512MB限制")
# 使用cozepy的files.upload方法上传文件[1,4](@ref) file_response = coze.files.upload(file=Path(file_path)) # 上传文件并获取响应 print(f"文件上传成功!文件ID: {file_response.id}") # 打印上传成功信息和文件ID return file_response # 返回文件响应对象
def handle_resume(path: str): """ 处理简历文件,上传到Coze并获取分析结果 参数: path: 简历文件的路径 返回: 分析结果文本 """ # 调用upload_file函数上传简历文件 uploaded_file = upload_file(path) # 检查上传是否成功 if not uploaded_file: print(f"文件上传失败:{path}。") # 打印上传失败信息 return # 失败时直接返回
# 获取上传文件的ID,后续消息会用到 file_id = uploaded_file.id
# 构建发送给机器人的消息列表 additional_messages = [ # 构建用户问题消息 Message.build_user_question_objects( [ # 可以同时传入多种类型的文件[1](@ref) MessageObjectString.build_file(file_id=file_id), # 添加文件到消息 MessageObjectString.build_text('帮我看看简历') # 添加文本请求 # 如果是音频文件,使用:MessageObjectString.build_audio(file_id=file_id) # 还可以添加文本描述 ] ) ] # 初始化结果文本变量 result_text = ''
# 设置机器人参数(当前为空) parameters = {}
# 初始化标志变量,用于跟踪首次内容和推理内容 is_first_reasoning_content = True is_first_content = True
# 流式调用Coze聊天API stream = coze.chat.stream( bot_id=bot_id, # 指定机器人ID user_id=user_id, # 指定用户ID additional_messages=additional_messages, # 添加用户消息 parameters=parameters, # 设置参数 )
# 打印日志ID,用于后续调试或跟踪 print("日志ID:", stream.response.logid)
# 处理流式响应事件 for event in stream: # 检查是否为消息增量事件 if event.event == ChatEventType.CONVERSATION_MESSAGE_DELTA: # 检查是否包含推理内容 if event.message.reasoning_content: pass # 忽略推理内容 else: # 处理普通内容 if is_first_content and not is_first_reasoning_content: is_first_content = not is_first_content result_text += event.message.content # 累积结果文本
# 检查是否完成聊天 if event.event == ChatEventType.CONVERSATION_CHAT_COMPLETED: print() # 打印空行 print("token使用情况:", event.chat.usage.token_count) # 打印token使用统计 break # 跳出循环
# 检查是否聊天失败 if event.event == ChatEventType.CONVERSATION_CHAT_FAILED: print() # 打印空行 print("聊天失败", event.chat.last_error) # 打印失败原因 break # 跳出循环
# 获取输入文件的目录路径 parent = os.path.dirname(path) # 提取文件名(不含扩展名) file_name = path.split('/')[-1].split('.')[0]
# 构建结果保存目录 result_dir = parent + '/resume_evaluated'
# 创建结果目录(如果不存在) os.makedirs(result_dir, exist_ok=True)
# 构建结果文件的完整路径 result_file = result_dir + '/' + file_name + '.md'
# 将结果文本写入Markdown文件 with open(result_file, 'w', encoding='utf-8') as f: f.write(result_text)
# 返回结果文本 return result_text
def handle_dir(dir_path: str): """ 批量处理文件夹中的所有简历文件
需求:遍历文件夹中所有指定格式的简历文件并处理 思路步骤: 1. 验证输入目录是否存在 2. 定义需要处理的文件扩展名列表 3. 遍历目录中的所有文件 4. 筛选出符合条件的文件格式 5. 对每个符合条件的文件调用handle_resume函数处理 6. 统计处理结果并返回
参数: dir_path: 包含简历文件的目录路径 返回: 字典,包含处理成功和失败的文件信息 """ #
if __name__ == '__main__': # 测试批量处理文件夹 dir_path = '文件目录' result = handle_dir(dir_path) print(f"\n批量处理结果: {result}")三、批量处理录音
Section titled “三、批量处理录音”思路如下:
"""需求:使用CozeSDK实现面试音频文件处批量处理功能思路步骤:1. 准备工作: 1.1 导入所需的库和模块 1.2 设置Coze API密钥、创建Coze客户端实例、指定机器人ID和用户ID2. 定义`upload_file`函数: 2.1 检查文件是否存在,若不存在则抛出异常 2.2 检查文件大小是否超过512MB,若超过则抛出异常 2.3 使用`cozepy`的`files.upload`方法上传文件,打印成功信息并返回文件响应对象,上传失败返回None3. 定义`handle_audio`函数: 3.1 调用`upload_file`上传音频文件,若上传失败则返回 3.2 获取上传文件ID,构建发送给机器人的消息列表,包含音频文件和文本请求 3.3 流式调用Coze聊天API,处理流式响应事件,累积结果文本 3.4 创建结果保存目录,将结果文本写入Markdown文件并返回4. 定义`handle_dir`函数: 4.1 验证输入目录是否存在且为目录 4.2 定义需要处理的音频文件扩展名列表 4.3 遍历目录中的所有文件,筛选出符合条件的音频文件格式 4.4 对每个符合条件的文件调用`handle_audio`函数处理 4.5 统计处理成功和失败的文件信息并返回"""代码实现:
"""需求:使用CozeSDK实现面试音频文件处批量处理功能思路步骤:1. 准备工作: 1.1 导入所需的库和模块 1.2 设置Coze API密钥、创建Coze客户端实例、指定机器人ID和用户ID2. 定义`upload_file`函数: 2.1 检查文件是否存在,若不存在则抛出异常 2.2 检查文件大小是否超过512MB,若超过则抛出异常 2.3 使用`cozepy`的`files.upload`方法上传文件,打印成功信息并返回文件响应对象,上传失败返回None3. 定义`handle_audio`函数: 3.1 调用`upload_file`上传音频文件,若上传失败则返回 3.2 获取上传文件ID,构建发送给机器人的消息列表,包含音频文件和文本请求 3.3 流式调用Coze聊天API,处理流式响应事件,累积结果文本 3.4 创建结果保存目录,将结果文本写入Markdown文件并返回4. 定义`handle_dir`函数: 4.1 验证输入目录是否存在且为目录 4.2 定义需要处理的音频文件扩展名列表 4.3 遍历目录中的所有文件,筛选出符合条件的音频文件格式 4.4 对每个符合条件的文件调用`handle_audio`函数处理 4.5 统计处理成功和失败的文件信息并返回"""
# 导入必要的库和模块import jsonimport loggingimport osfrom pathlib import Pathfrom typing import Optional
from cozepy import COZE_CN_BASE_URL, ChatStatus, Coze, DeviceOAuthApp, Message, MessageContentType, TokenAuth, \ MessageObjectString, ChatEventType # noqa 忽略未使用的导入警告
# Coze API密钥,用于身份验证coze_api_token = 'token'
# 创建Coze客户端实例,使用TokenAuth进行身份验证,并指定中文API地址coze = Coze(auth=TokenAuth(token=coze_api_token), base_url=COZE_CN_BASE_URL)
# 在Coze中创建机器人实例,复制网页链接中的最后一个数字作为机器人ID[1](@ref)bot_id = "botid" # 直接指定机器人ID
# 用户ID用于标识用户身份,开发者可以使用自定义业务ID或随机字符串user_id = "userid"
def upload_file(file_path: str): """ 上传文件到Coze并返回文件信息[1,5](@ref) """ # 检查文件是否存在 if not os.path.exists(file_path): raise FileNotFoundError(f"文件不存在: {file_path}")
# 检查文件大小(Coze限制为512MB)[5](@ref) file_size = os.path.getsize(file_path) # 获取文件大小(字节) if file_size > 512 * 1024 * 1024: # 512MB限制检查 raise ValueError("文件大小超过512MB限制")
# 使用cozepy的files.upload方法上传文件[1,4](@ref) file_response = coze.files.upload(file=Path(file_path)) # 上传文件并获取响应 print(f"文件上传成功!文件ID: {file_response.id}") # 打印上传成功信息和文件ID return file_response # 返回文件响应对象
def handle_audio(path: str): """ 处理简历文件,上传到Coze并获取分析结果 参数: path: 简历文件的路径 返回: 分析结果文本 """ # 调用upload_file函数上传简历文件 uploaded_file = upload_file(path) # 检查上传是否成功 if not uploaded_file: print(f"文件上传失败:{path}。") # 打印上传失败信息 return # 失败时直接返回
# 获取上传文件的ID,后续消息会用到 file_id = uploaded_file.id
# 构建发送给机器人的消息列表 additional_messages = [ # 构建用户问题消息 Message.build_user_question_objects( [ # 可以同时传入多种类型的文件[1](@ref) MessageObjectString.build_audio(file_id=file_id), # 添加文件到消息 MessageObjectString.build_text('帮我分析一下面试录音') # 添加文本请求 # 如果是音频文件,使用:MessageObjectString.build_audio(file_id=file_id) # 还可以添加文本描述 ] ) ] # 初始化结果文本变量 result_text = ''
# 设置机器人参数(当前为空) parameters = {}
try: # 初始化标志变量,用于跟踪首次内容和推理内容 is_first_reasoning_content = True is_first_content = True
# 流式调用Coze聊天API stream = coze.chat.stream( bot_id=bot_id, # 指定机器人ID user_id=user_id, # 指定用户ID additional_messages=additional_messages, # 添加用户消息 parameters=parameters, # 设置参数 )
# 打印日志ID,用于后续调试或跟踪 print("日志ID:", stream.response.logid)
# 处理流式响应事件 for event in stream: # 检查是否为消息增量事件 if event.event == ChatEventType.CONVERSATION_MESSAGE_DELTA: # 检查是否包含推理内容 if event.message.reasoning_content: pass # 忽略推理内容 else: # 处理普通内容 if is_first_content and not is_first_reasoning_content: is_first_content = not is_first_content result_text += event.message.content # 累积结果文本
# 检查是否完成聊天 if event.event == ChatEventType.CONVERSATION_CHAT_COMPLETED: print() # 打印空行 print("token使用情况:", event.chat.usage.token_count) # 打印token使用统计 break # 跳出循环
# 检查是否聊天失败 if event.event == ChatEventType.CONVERSATION_CHAT_FAILED: print() # 打印空行 print("聊天失败", event.chat.last_error) # 打印失败原因 break # 跳出循环
except Exception as e: print(f"聊天过程发生错误: {str(e)}") # 捕获并打印聊天过程中的异常
# 获取输入文件的目录路径 parent = os.path.dirname(path) # 提取文件名(不含扩展名) file_name = path.split('/')[-1].split('.')[0]
# 构建结果保存目录 result_dir = parent + '/audio_evaluated'
# 创建结果目录(如果不存在) os.makedirs(result_dir, exist_ok=True)
# 构建结果文件的完整路径 result_file = result_dir + '/' + file_name + '.md'
# 将结果文本写入Markdown文件 with open(result_file, 'w', encoding='utf-8') as f: f.write(result_text)
# 返回结果文本 return result_text
def handle_dir(dir_path: str): # 检查目录是否存在 if not os.path.exists(dir_path): print(f"目录不存在: {dir_path}") return None
# 检查是否为目录 if not os.path.isdir(dir_path): print(f"路径不是一个目录: {dir_path}") return None
# 定义需要处理的文件扩展名(小写) supported_extensions = ['.mp3', '.wav', '.ogg']
# 初始化统计变量 total_files = 0 processed_files = 0 failed_files = []
print(f"开始处理目录: {dir_path}") print(f"支持的文件格式: {', '.join(supported_extensions)}")
# 遍历目录中的所有文件 for root, dirs, files in os.walk(dir_path): for file in files: # 获取文件扩展名(转为小写以便匹配) _, ext = os.path.splitext(file.lower())
# 检查是否为支持的文件格式 if ext in supported_extensions: total_files += 1 # 构建完整的文件路径 file_path = os.path.join(root, file)
print(f"\n[{total_files}] 开始处理文件: {file_path}") try: # 调用handle_resume函数处理文件 result = handle_audio(file_path) if result: processed_files += 1 print(f"文件处理成功: {file}") else: failed_files.append(file_path) print(f"文件处理失败: {file}") except Exception as e: failed_files.append(file_path) print(f"处理文件时发生异常: {file}, 错误信息: {str(e)}")
# 打印处理总结 print("\n" + "=" * 50) print(f"处理完成!") print(f"总文件数: {total_files}") print(f"成功处理: {processed_files}") print(f"处理失败: {len(failed_files)}") if failed_files: print("\n失败的文件列表:") for file in failed_files: print(f"- {file}") print("=" * 50)
# 返回处理结果统计 return { 'total_files': total_files, 'processed_files': processed_files, 'failed_files': failed_files }
if __name__ == '__main__':
# 测试批量处理文件夹 dir_path = '文件目录' result = handle_dir(dir_path) print(f"\n批量处理结果: {result}")四、批量生成面试题
Section titled “四、批量生成面试题”思路如下:
"""需求:借助CozeSDK实现批量基于简历文件生成面试题思路步骤:1. 准备部分: 1.1 导入相关库和模块 1.2 设置Coze API密钥,创建Coze客户端实例,并指定机器人ID与用户ID2. 定义`upload_file`函数: 2.1 检查文件是否存在,若不存在则抛出`FileNotFoundError`异常 2.2 检查文件大小是否超过512MB,若超过则抛出`ValueError`异常 2.3 使用`cozepy`库的`files.upload`方法上传文件,打印成功信息并返回文件响应对象,若失败则返回`None`3. 定义`generate_questions`函数: 3.1 调用`upload_file`函数上传简历文件,若上传失败则打印信息并返回 3.2 获取上传文件的ID,构建包含文件和文本请求(生成面试题)的消息列表发送给机器人 3.3 流式调用Coze聊天API,处理响应事件,累积结果文本 3.4 创建结果保存目录,将结果文本写入Markdown文件并返回4. 定义`handle_dir`函数: 4.1 检查目录是否存在且是否为目录,若不满足则打印信息并返回 4.2 定义支持处理的文件扩展名列表 4.3 遍历目录下所有文件,筛选出符合扩展名要求的文件 4.4 对每个符合条件的文件调用`generate_questions`函数进行处理 4.5 统计处理成功和失败的文件数量并返回结果"""代码实现:
"""需求:借助CozeSDK实现批量基于简历文件生成面试题思路步骤:1. 准备部分: 1.1 导入相关库和模块 1.2 设置Coze API密钥,创建Coze客户端实例,并指定机器人ID与用户ID2. 定义`upload_file`函数: 2.1 检查文件是否存在,若不存在则抛出`FileNotFoundError`异常 2.2 检查文件大小是否超过512MB,若超过则抛出`ValueError`异常 2.3 使用`cozepy`库的`files.upload`方法上传文件,打印成功信息并返回文件响应对象,若失败则返回`None`3. 定义`generate_questions`函数: 3.1 调用`upload_file`函数上传简历文件,若上传失败则打印信息并返回 3.2 获取上传文件的ID,构建包含文件和文本请求(生成面试题)的消息列表发送给机器人 3.3 流式调用Coze聊天API,处理响应事件,累积结果文本 3.4 创建结果保存目录,将结果文本写入Markdown文件并返回4. 定义`handle_dir`函数: 4.1 检查目录是否存在且是否为目录,若不满足则打印信息并返回 4.2 定义支持处理的文件扩展名列表 4.3 遍历目录下所有文件,筛选出符合扩展名要求的文件 4.4 对每个符合条件的文件调用`generate_questions`函数进行处理 4.5 统计处理成功和失败的文件数量并返回结果"""
# 导入必要的库和模块import jsonimport loggingimport osfrom pathlib import Pathfrom typing import Optional
from cozepy import COZE_CN_BASE_URL, ChatStatus, Coze, DeviceOAuthApp, Message, MessageContentType, TokenAuth, \ MessageObjectString, ChatEventType # noqa 忽略未使用的导入警告
# Coze API密钥,用于身份验证coze_api_token = 'token'
# 创建Coze客户端实例,使用TokenAuth进行身份验证,并指定中文API地址coze = Coze(auth=TokenAuth(token=coze_api_token), base_url=COZE_CN_BASE_URL)
# 在Coze中创建机器人实例,复制网页链接中的最后一个数字作为机器人ID[1](@ref)bot_id = "botid" # 直接指定机器人ID
# 用户ID用于标识用户身份,开发者可以使用自定义业务ID或随机字符串user_id = "userid"
def upload_file(file_path: str): """ 上传文件到Coze并返回文件信息[1,5](@ref) """ # 检查文件是否存在 if not os.path.exists(file_path): raise FileNotFoundError(f"文件不存在: {file_path}")
# 检查文件大小(Coze限制为512MB)[5](@ref) file_size = os.path.getsize(file_path) # 获取文件大小(字节) if file_size > 512 * 1024 * 1024: # 512MB限制检查 raise ValueError("文件大小超过512MB限制")
# 使用cozepy的files.upload方法上传文件[1,4](@ref) file_response = coze.files.upload(file=Path(file_path)) # 上传文件并获取响应 print(f"文件上传成功!文件ID: {file_response.id}") # 打印上传成功信息和文件ID return file_response # 返回文件响应对象
def generate_questions(path: str): """ 处理简历文件,上传到Coze并获取分析结果 参数: path: 简历文件的路径 返回: 分析结果文本 """ # 调用upload_file函数上传简历文件 uploaded_file = upload_file(path) # 检查上传是否成功 if not uploaded_file: print(f"文件上传失败:{path}。") # 打印上传失败信息 return # 失败时直接返回
# 获取上传文件的ID,后续消息会用到 file_id = uploaded_file.id
# 构建发送给机器人的消息列表 additional_messages = [ # 构建用户问题消息 Message.build_user_question_objects( [ # 可以同时传入多种类型的文件[1](@ref) MessageObjectString.build_file(file_id=file_id), # 添加文件到消息 MessageObjectString.build_text('帮我生成一下面试题') # 添加文本请求 # 如果是音频文件,使用:MessageObjectString.build_audio(file_id=file_id) # 还可以添加文本描述 ] ) ] # 初始化结果文本变量 result_text = ''
# 设置机器人参数(当前为空) parameters = {}
try: # 初始化标志变量,用于跟踪首次内容和推理内容 is_first_reasoning_content = True is_first_content = True
# 流式调用Coze聊天API stream = coze.chat.stream( bot_id=bot_id, # 指定机器人ID user_id=user_id, # 指定用户ID additional_messages=additional_messages, # 添加用户消息 parameters=parameters, # 设置参数 )
# 打印日志ID,用于后续调试或跟踪 print("日志ID:", stream.response.logid)
# 处理流式响应事件 for event in stream: # 检查是否为消息增量事件 if event.event == ChatEventType.CONVERSATION_MESSAGE_DELTA: # 检查是否包含推理内容 if event.message.reasoning_content: pass # 忽略推理内容 else: # 处理普通内容 if is_first_content and not is_first_reasoning_content: is_first_content = not is_first_content result_text += event.message.content # 累积结果文本
# 检查是否完成聊天 if event.event == ChatEventType.CONVERSATION_CHAT_COMPLETED: print() # 打印空行 print("token使用情况:", event.chat.usage.token_count) # 打印token使用统计 break # 跳出循环
# 检查是否聊天失败 if event.event == ChatEventType.CONVERSATION_CHAT_FAILED: print() # 打印空行 print("聊天失败", event.chat.last_error) # 打印失败原因 break # 跳出循环
except Exception as e: print(f"聊天过程发生错误: {str(e)}") # 捕获并打印聊天过程中的异常
# 获取输入文件的目录路径 parent = os.path.dirname(path) # 提取文件名(不含扩展名) file_name = path.split('/')[-1].split('.')[0]
# 构建结果保存目录 result_dir = parent + '/question_generated'
# 创建结果目录(如果不存在) os.makedirs(result_dir, exist_ok=True)
# 构建结果文件的完整路径 result_file = result_dir + '/' + file_name + '.md'
# 将结果文本写入Markdown文件 with open(result_file, 'w', encoding='utf-8') as f: f.write(result_text)
# 返回结果文本 return result_text
def handle_dir(dir_path: str): # 检查目录是否存在 if not os.path.exists(dir_path): print(f"目录不存在: {dir_path}") return None
# 检查是否为目录 if not os.path.isdir(dir_path): print(f"路径不是一个目录: {dir_path}") return None
# 定义需要处理的文件扩展名(小写) supported_extensions = ['.docx', '.pdf', '.doc']
# 初始化统计变量 total_files = 0 processed_files = 0 failed_files = []
print(f"开始处理目录: {dir_path}") print(f"支持的文件格式: {', '.join(supported_extensions)}")
# 遍历目录中的所有文件 for root, dirs, files in os.walk(dir_path): for file in files: # 获取文件扩展名(转为小写以便匹配) _, ext = os.path.splitext(file.lower())
# 检查是否为支持的文件格式 if ext in supported_extensions: total_files += 1 # 构建完整的文件路径 file_path = os.path.join(root, file)
print(f"\n[{total_files}] 开始处理文件: {file_path}") try: # 调用handle_resume函数处理文件 result = generate_questions(file_path) if result: processed_files += 1 print(f"文件处理成功: {file}") else: failed_files.append(file_path) print(f"文件处理失败: {file}") except Exception as e: failed_files.append(file_path) print(f"处理文件时发生异常: {file}, 错误信息: {str(e)}")
# 打印处理总结 print("\n" + "=" * 50) print(f"处理完成!") print(f"总文件数: {total_files}") print(f"成功处理: {processed_files}") print(f"处理失败: {len(failed_files)}") if failed_files: print("\n失败的文件列表:") for file in failed_files: print(f"- {file}") print("=" * 50)
# 返回处理结果统计 return { 'total_files': total_files, 'processed_files': processed_files, 'failed_files': failed_files }
if __name__ == '__main__':
# 测试批量处理文件夹 dir_path = '文件目录' result = handle_dir(dir_path) print(f"\n批量处理结果: {result}") 发布于 2025-12-31