
数仓建模架构
发布于 2022-08-23
day03_保险项目课程笔记
Section titled “day03_保险项目课程笔记”今日内容:
- 1- 数据仓库的基本介绍
- 2- 维度分析相关内容
- 3- 数仓建模相关内容
- 4- 缓慢渐变维
- 5- 数仓分层架构
- 6- 项目环境搭建工作
- 7- 完成基础数据集导入操作
1. 数据仓库的基本介绍
Section titled “1. 数据仓库的基本介绍”- 1- 何为数据仓库呢?
存储数据的仓库, 主要是用于存储过去历史发生过的数据, 基于主题对数据进行分析操作, 通过对过去历史数据的分析,从而能够对未来提供决策支持- 2- 数据仓库最大的特点:
既不生产数据也不消耗数据, 数据来源于各个数据源- 3- 数据仓库的四大特征:
面向于主题: 分析什么 , 什么就是你的主题集成性: 指的数据从各个数据源来 将各个数据源的数据全部汇聚在一起, 格式不尽相同非易失性(稳定性) : 存储都是过去既定发生过的数据, 这些数据一般不会发生修改时变性: 随着时间的推移, 原有分析的手段无法适应未来分析操作, 需要进行改变分析方案,同时数据也会进行新增操作- 4- OLTP 和 OLAP 区别:
OLTP: 关系型数据库(联机事务处理) 面向于事务,业务 捕获数据 存储最近发生的数据 交互式处理, 延迟比较低OLAP: 数据仓库 (联机分析处理) 面向于主题 分析数据 存储过去历史数据 批处理,延迟比较高- 5- 何为ETL:
ETL: 抽取 转换 加载
狭义上ETL: 指的数据从ODS层将数据抽取出来, 对数据进行清洗转换处理的操作, 将清洗转换后的数据加载到DW层过程
宽泛上ETL: 只要操作存在抽取 转换 加载的过程 认为属于ETL范畴 指的整个数仓的全过程- 6- 数据仓库和数据集市
数据仓库是包含数据集市的, 一般来说数据集市指的是基于主题/部门的统计过程, 称为一个集市
数据仓库指的构建集团的数据中心2. 维度分析
Section titled “2. 维度分析”- 维度:
指的: 分析问题的角度, 比如说: 分析过去10年订单, 可以从地区, 时间, 用户,店铺, 商圈等等
维度分类: 定性维度: 主要指的统计每天, 各个这样相关的维度 比如说: 统计每天的订单量, 此时 时间(天) 就是一个定性维度 定性维度在SQL上表现一般是放置 group by中 定量维度: 主要指的统计某一个具体的范围, 或者具体的值的维度 比如说: 统计年龄在10~20岁区间 性别为男, 每天的消费费用 年龄 和 性别 属于 定量维度 每天 属于 定性维度 如果确定是定量维度, 一般在SQL中放置在where条件中
分层和分级: 比如说, 根据地区维度进行统计, 此时对地区再次细化: 省份, 城市, 县区...
上卷和下钻: 必须要有一个衡量的标准 比如说: 以天为例, 上卷统计, 统计 月 年 下钻统计: 统计 小时
说明: 不管是上卷还是下钻, 不管是分层还是分级, 本质上都是在统计分析的时候, 让维度变得更多了- 指标:
指的: 指标是衡量事务发展的标准,也叫度量值
常见的指标的主要两大类: 绝对指标: 指的计算出具体值的操作, 比如 计算销售额, 订单量 sum() max() min() avg() count() ..... 相对指标: 指的不需要计算出具体的值, 更多是一些相对结果, 比如说 环比增长率, 转换率 流失率 同比增长 如果后续的指标都是一些相对指标, 可以对数据进行采样计算的3. 数仓建模
Section titled “3. 数仓建模”何为数仓建模: 指的如何在数据仓库中构建表
可以说, 数仓建模其实就是规范化如何建表一套理论支持
- 三范式建模:
三范式建模更多是应用传统业务环境中, 关系型数据库中的, 主要规定了: 表应该都要有主键, 在构建过程中尽量避免数据冗余发生, 尽量拆分表....- 维度建模:
维度建模主要是应用在分析性的数据库中, 比如数据仓库, 规定在进行建模的过程中, 以分析为前提, 只要是能够利于分析的, 就是好的建模方案, 在建模过程中, 允许数据出现一定的冗余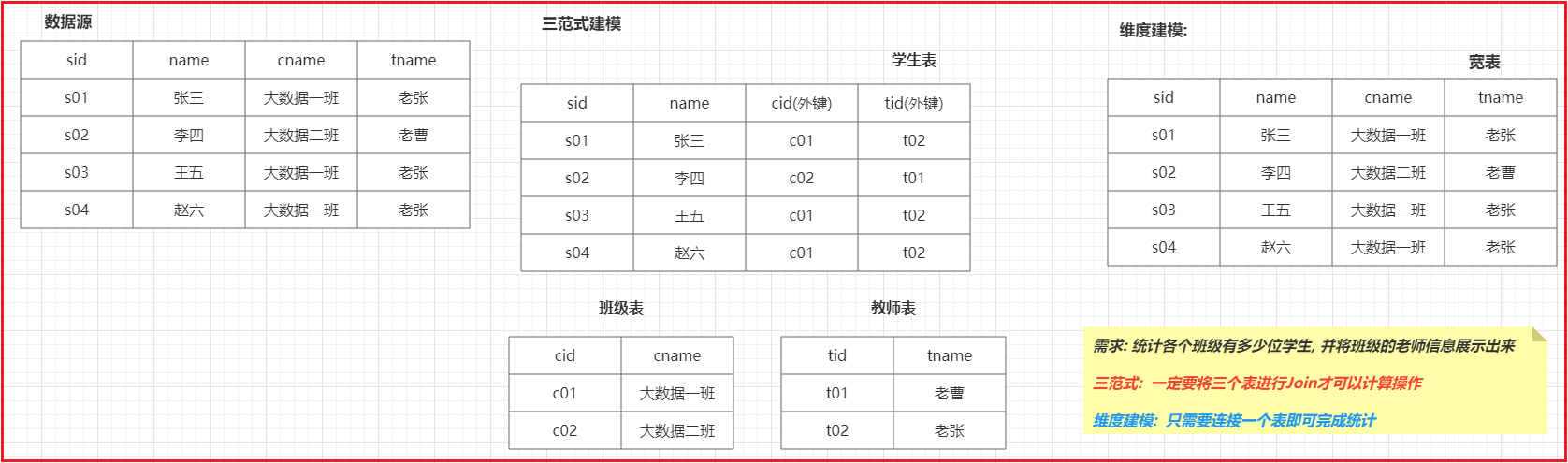
维度建模主要分为有二种类型的表:
- 事实表:
事实表: 反应用户行为的数据的表一般都是事实表 基于什么来统计分析, 什么就是我们的主题, 而主题所对应这些表, 一般都是事实表,或者说用于计算指标的表 事实表内部一般都是有大量的外键字段的
事实表分类: 了解 事务事实表: 最初始的事实表, 从业务中所确定出来事实表, 一般都是 事务事实表 周期快照事实表: 指的那些进行了提前聚合之后的事实表或者结果表 项目一的, 在DWS层, 形成了日统计宽表 后续在计算效率更高 DM层, 计算月 年 累计快照事实表: 表中每一条记录反应了一个事件从开始到结束整个生命周期全过程- 维度表:
维度表: 在基于事实表进行统计分析的时候, 需要关联到其他的表, 这些表都是维度表 维度表一般都是平台或者系统自建的一些表
维度表分类: 低基数维度表: 指的数据量一般只有几十条到几千条或者数据条数比较稳定的表 高基数维度表: 指的数据量一般都是万级别或者 千万级别数据表在维度建模中, 有三种反应数仓发展模式:
- 星型模型:
- 特点: 只有一个事实表, 也就意味着只有一个分析的主题, 在事实表周围围绕了多个维度表, 维度表与维度表之间没有任何的关联
- 数仓发展: 初期
- 雪花模型:
- 特点: 只有一个事实表, 也就意味着只有一个分析的主题,在事实表周围围绕了多个维度表, 维度表可以接着关联其他的维度表
- 数仓发展: 数仓发展进入畸形状态, 在数仓构建中, 尽量避免出现这种模型
- 星座模型:
- 特点: 有多个事实表, 也就意味着有了多个分析的主题, 在事实表周围围绕了多个维度表, 当条件吻合情况下, 多个事实表之间是可以共享维度表
- 数仓发展: 中 后 期

4. 缓慢渐变维
Section titled “4. 缓慢渐变维”作用: 解决历史变更数据是否需要存储的问题
思考: 如果不存储历史数据, 只存储最新数据即可, 有什么问题呢? 会导致分析的结果不准确
举个栗子: 比如说: 有一个哥们居住在北京, 在2021-01月 到 2021-06月份共计消费10w ,在2021-07月份从北京搬家到三亚, 在2021-07~2021-12月份 在三亚花费10w
如果没有维护用户历史变化, 在2022年进行统计分析这一年的各个地区的销售总额的时候, 用户表仅存储这个哥们在三亚居住,并不知道其有半年是在北京居住 在进行统计的时候, 会将其在北京花费的10w元, 计入到三亚的消费中, 导致北京地区销售总额少了10w , 而三亚变多了
如果维护了整个历史变化行为, 此时我们就可以精确计算出各个地区的销售额如何实现历史变化的维护操作. 主要提供了三种方案:
- SCD1: 不维护历史变化, 直接覆盖操作, 仅适用于错误数据的处理操作
- SCD2: 也被称为 拉链表, 会维护历史变更行为
在表中多加两个字段, 一个是开链时间(起始时间|生效时间) 一个闭链时间(截止时间|失效时间), 一旦发现有数据变更, 首先会将上一条记录闭链时间从 9999-99-99 变更为当天时间上一天即可, 然后新增一条当前最新的数据, 此时开链时间为当天的时间, 闭链时间为 9999-99-99
好处: 可以维护更多的历史变化行为 实现比较简单 (left join 和 union all)
弊端: 数据冗余程度比较高,占用磁盘空间较大- SCD3: 会维护历史变更行为
当数据发生变更的时候, 通过修改表的结构, 增加一个新的字段, 记录最新的数据即可
好处: 尽量减少数据冗余的情况
弊端: 无法保存太多历史版本 维护不方便 效率比较低
适用于: 磁盘空间不充足, 需要保留历史版本比较少的情况
如果磁盘充足的, 建议都使用拉链表解决方案5. 数据仓库的分层架构
Section titled “5. 数据仓库的分层架构”- 为什么要进行数仓分层呢?
1- 结构规整, 利于维护2- 提升开发效率3- 进行业务的划分, 功能划分- ODS层: 数据源层(贴源层)
数据源层: 对接数据源, 一般会和数据源保持相同粒度, 将数据源中完整的拷贝到ODS层中, 一般在构建ODS层的时候, 会加一个分区的字段, 用于标记数据是在何时抽取到数据仓库中- DW层: 数据仓库层
数据仓库层: 数据来源于 ODS层, 需要对ODS层进行清洗转换处理的操作, 将数据加载到DW层中, 在DW层更多基于数据进行统计分析处理的操作 如果业务比较复杂 一般在DW层再次进行细化的分层操作- app|da|rpt|ads层: 数据应用层
数据应用层: 用于对接上层应用, 数据是来源于DW层分析之后的结果数据, 此层一般会根据上层应用需要什么指标的结果数据, 从DW层抽取出对应的结果数据, 放置到数据应用层中当前保险项目其实就是基于以上三层进行构建的, 并没有复杂的分层
原因: 当前项目是基于spark SQL来进行统计分析, spark SQL 擅长进行不断迭代计算操作, 有时候直接通过一个应用程序完成整个计算流程, 所以整个保险项目中分层架构没有那么明显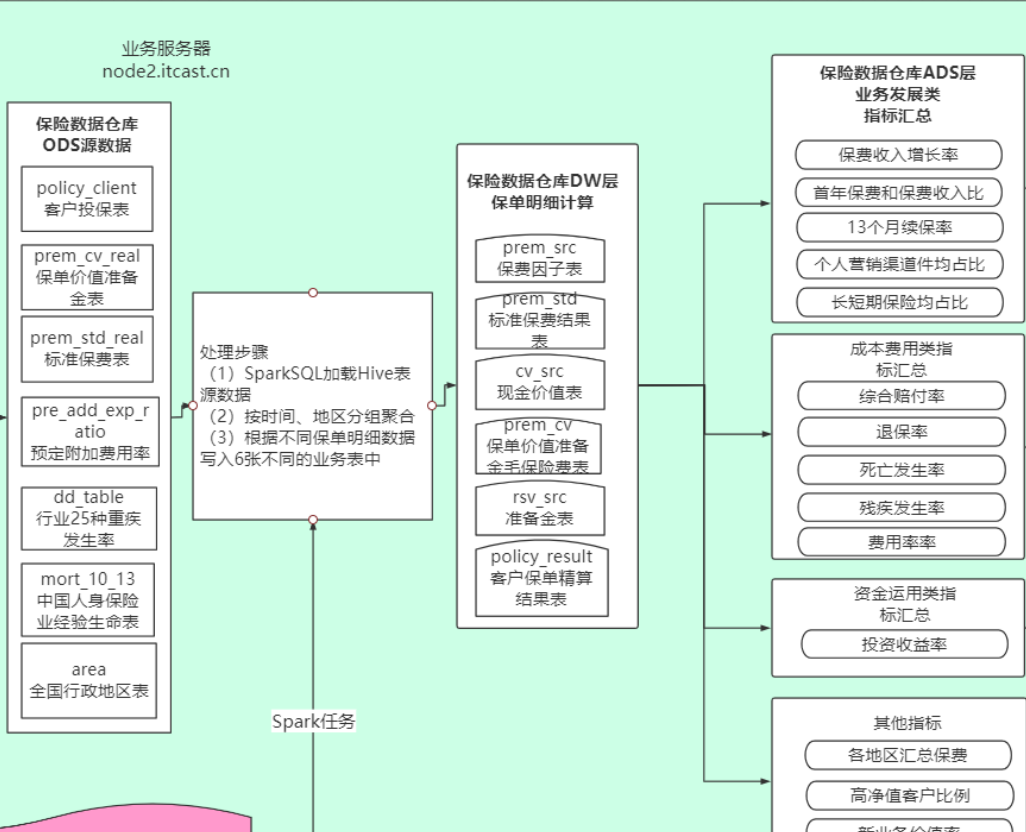
6. 项目环境 搭建工作
Section titled “6. 项目环境 搭建工作”6.1. pycharm构建环境:
Section titled “6.1. pycharm构建环境:”6.1.1 清洗项目的所有的远端环境:
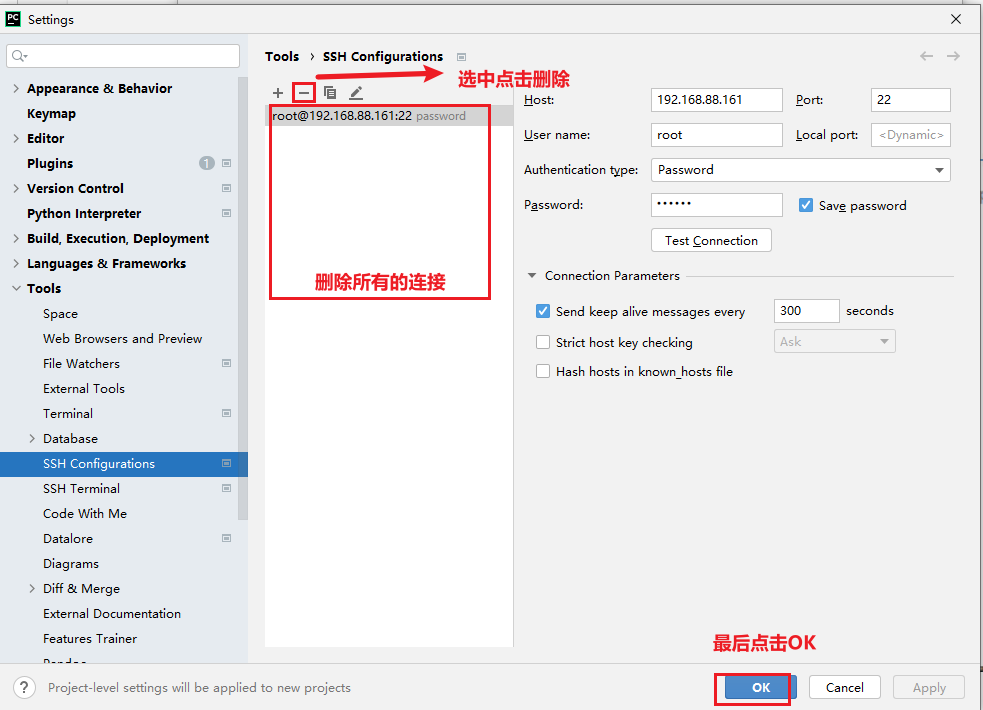
Section titled “6.1.1 清洗项目的所有的远端环境:”- 1- 清洗所有的远端环境
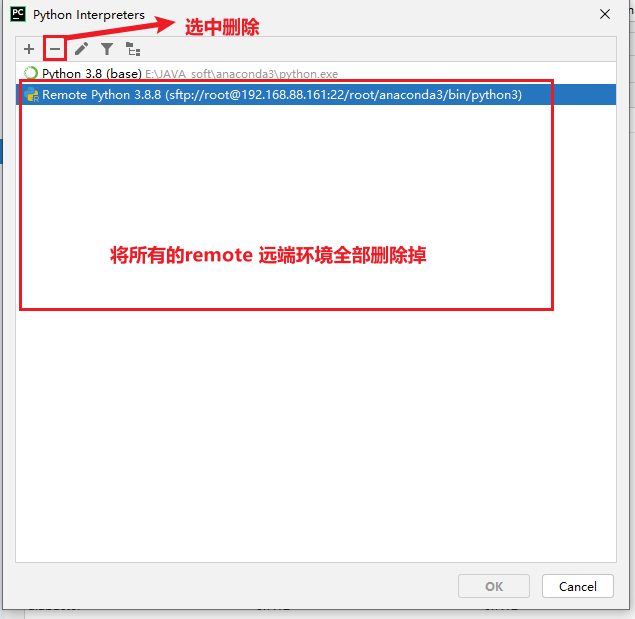
删除后, 一路点击确定ok. 关闭界面
- 2- 清理所有的远端连接:
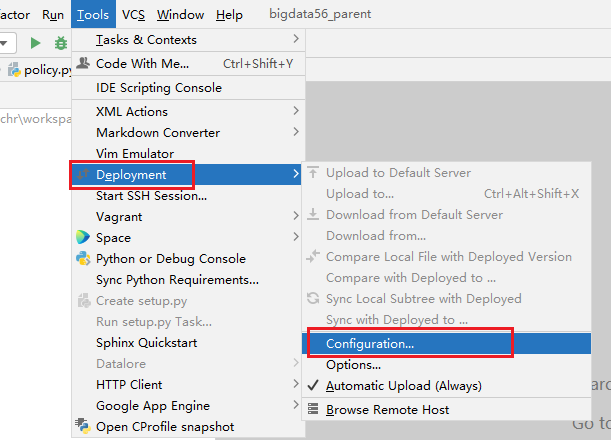
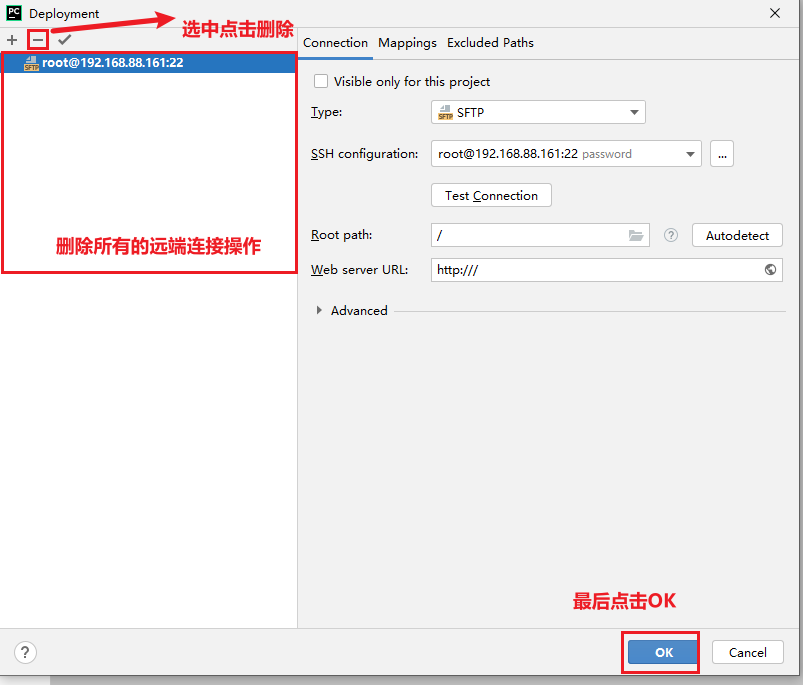
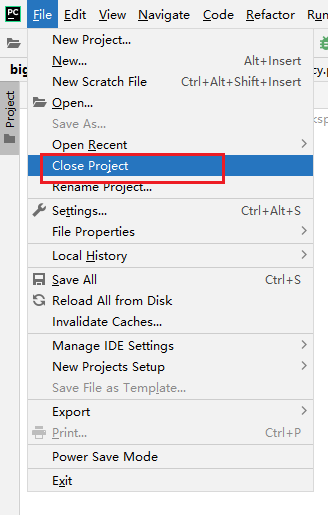
最后关闭当前项目:
6.1.2 基于远端环境构建空白项目环境
Section titled “6.1.2 基于远端环境构建空白项目环境”
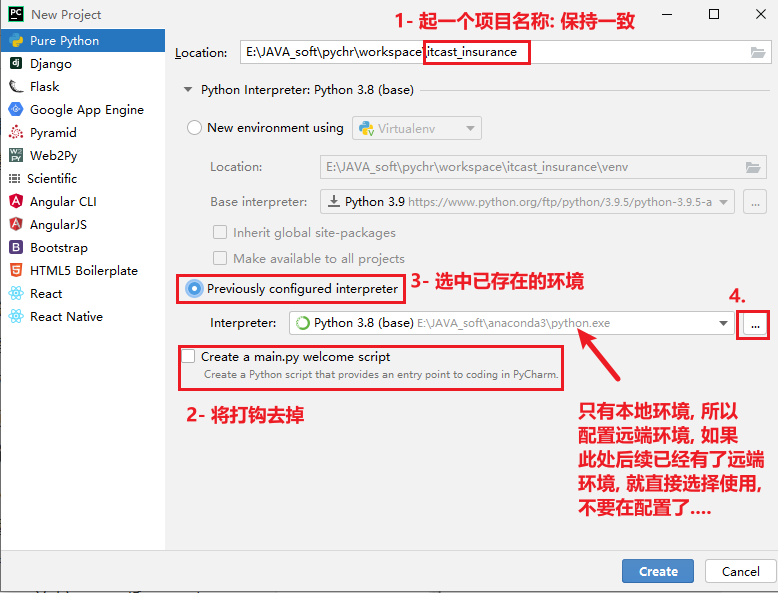
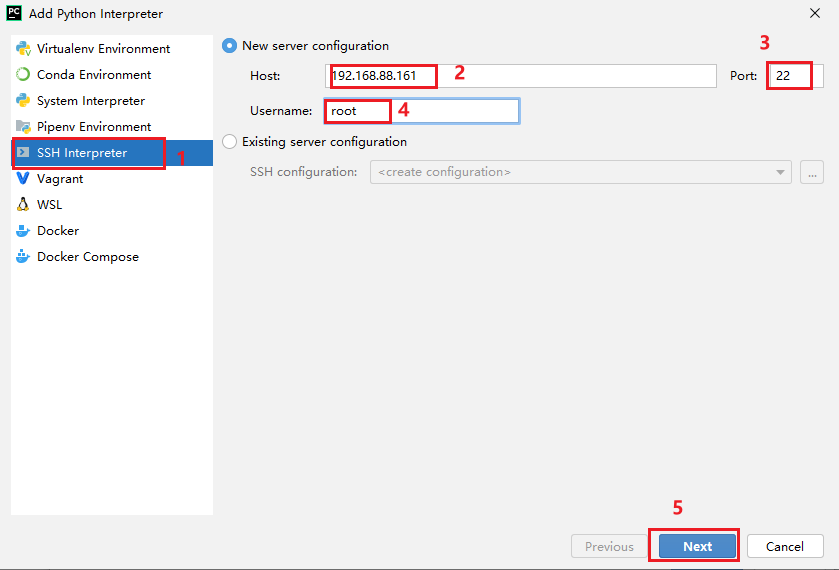
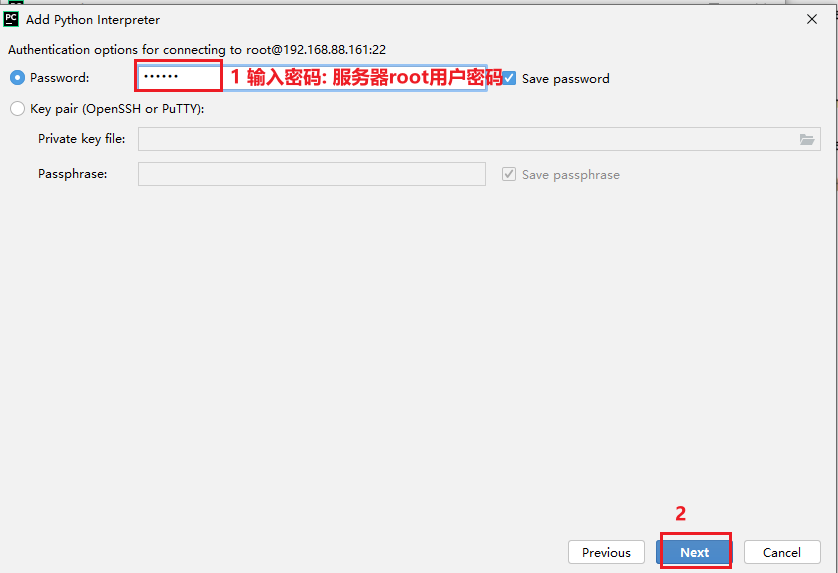
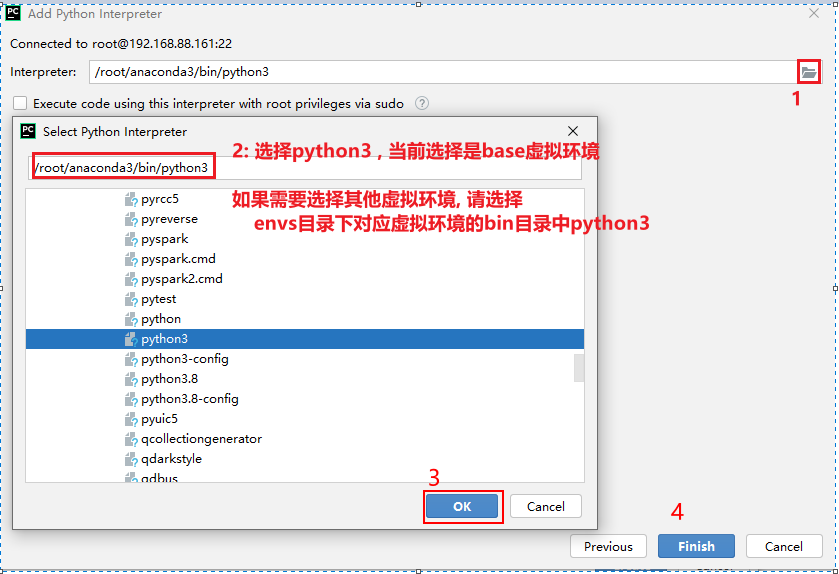
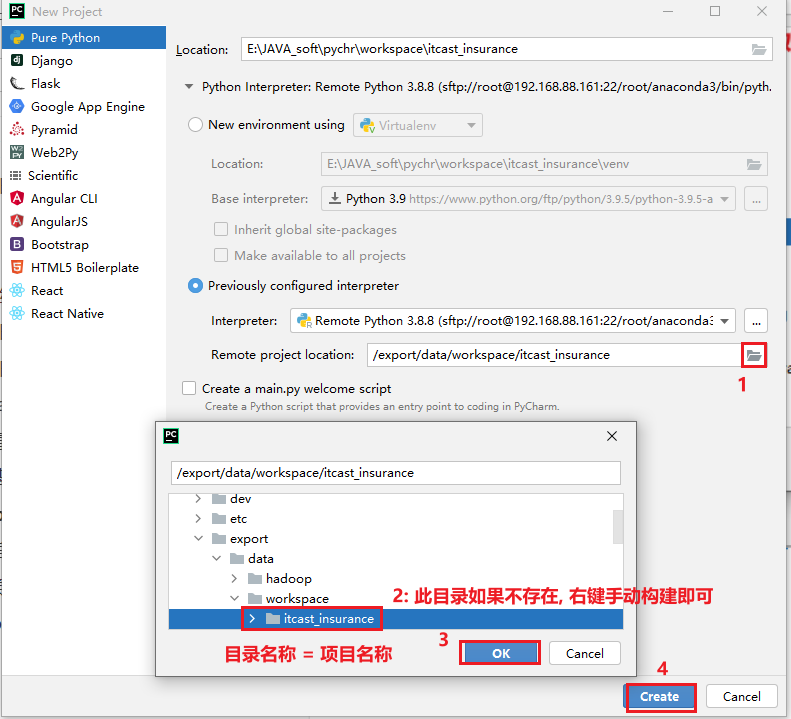
配置自动提交本地代码到远端:
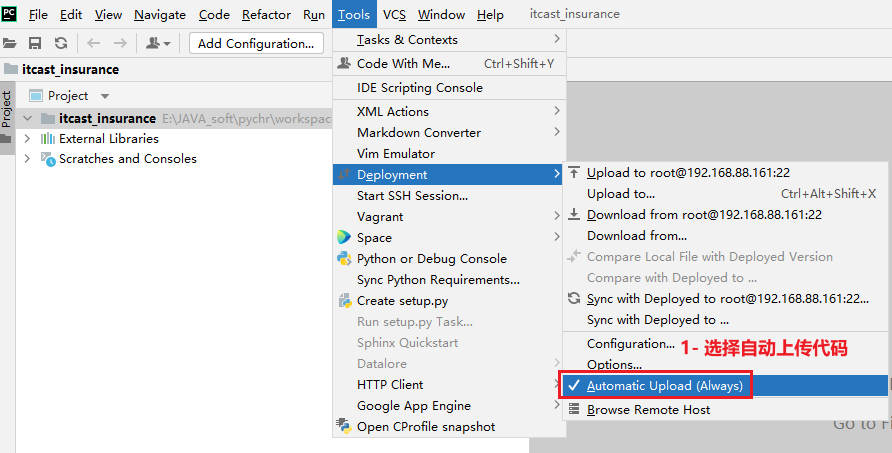
如果后续校验发现, 本地代码和远端不匹配, 此时性需要手动进行上传操作:
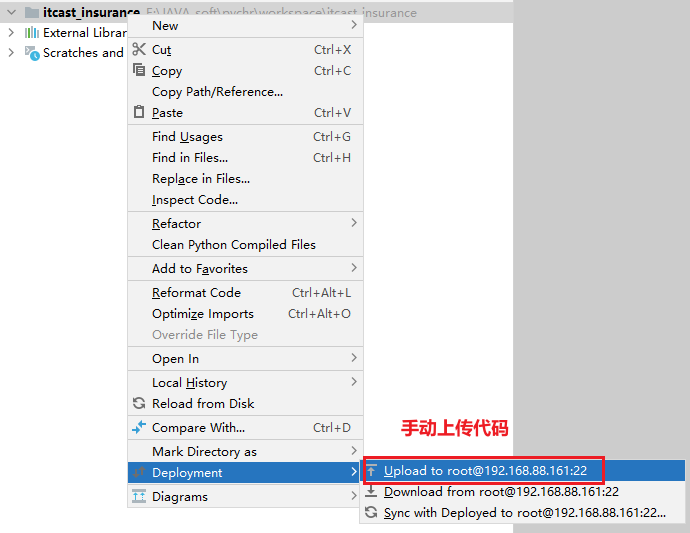
最后, 配置一下pycharm的py脚本模板:
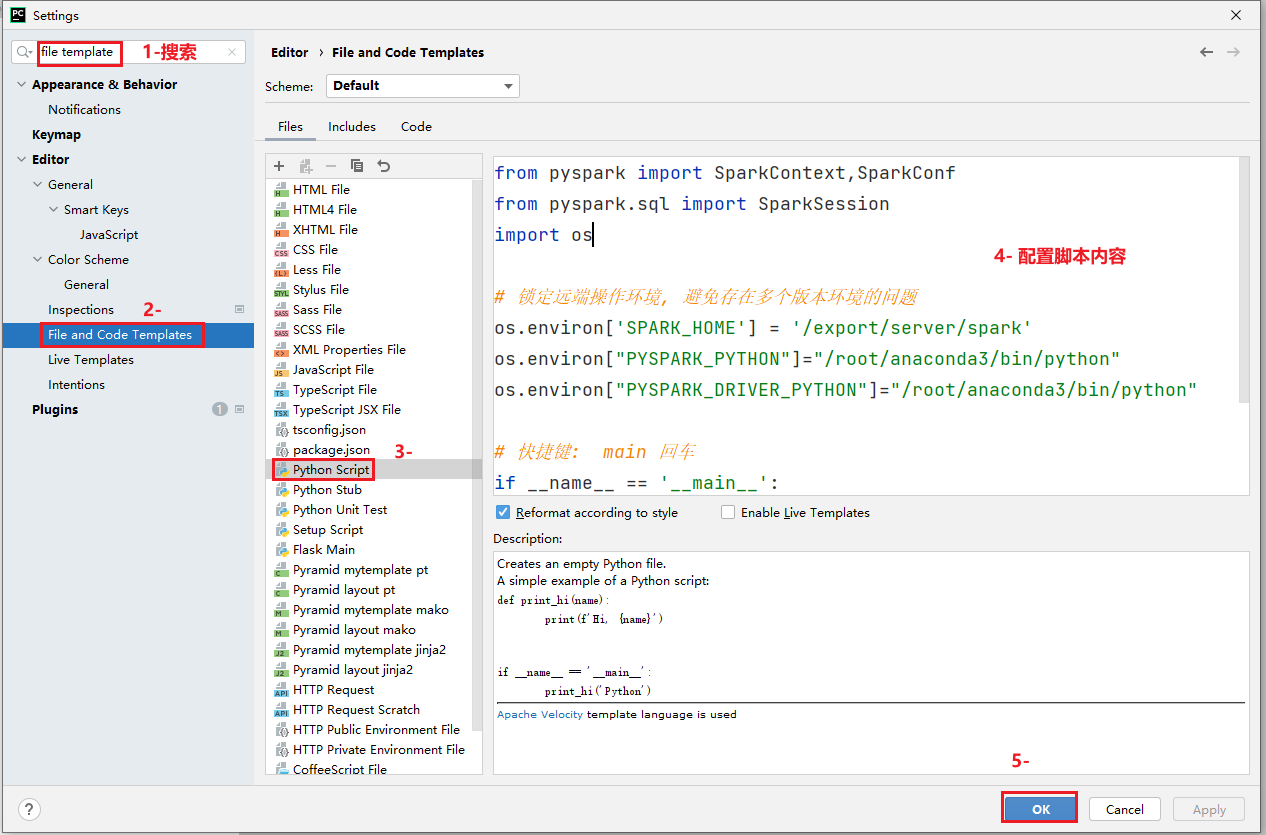
from pyspark import SparkContext,SparkConffrom pyspark.sql import SparkSessionimport os
# 锁定远端操作环境, 避免存在多个版本环境的问题os.environ['SPARK_HOME'] = '/export/server/spark'os.environ["PYSPARK_PYTHON"]="/root/anaconda3/bin/python"os.environ["PYSPARK_DRIVER_PYTHON"]="/root/anaconda3/bin/python"
# 快捷键: main 回车if __name__ == '__main__': print("pyspark模板")6.1.3 构建项目基本目录环境
Section titled “6.1.3 构建项目基本目录环境”
6.2 基于pycharm连接各个服务器
Section titled “6.2 基于pycharm连接各个服务器”目的: 基于pycharm实现对远端文件的管理操作, 以及替换CRT操作命令界面
6.2.1: 首先配置连接服务器的信息
Section titled “6.2.1: 首先配置连接服务器的信息”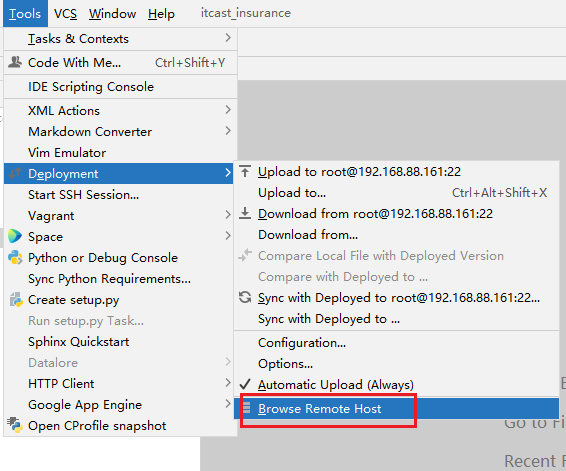
配置其他的远端服务器地址:
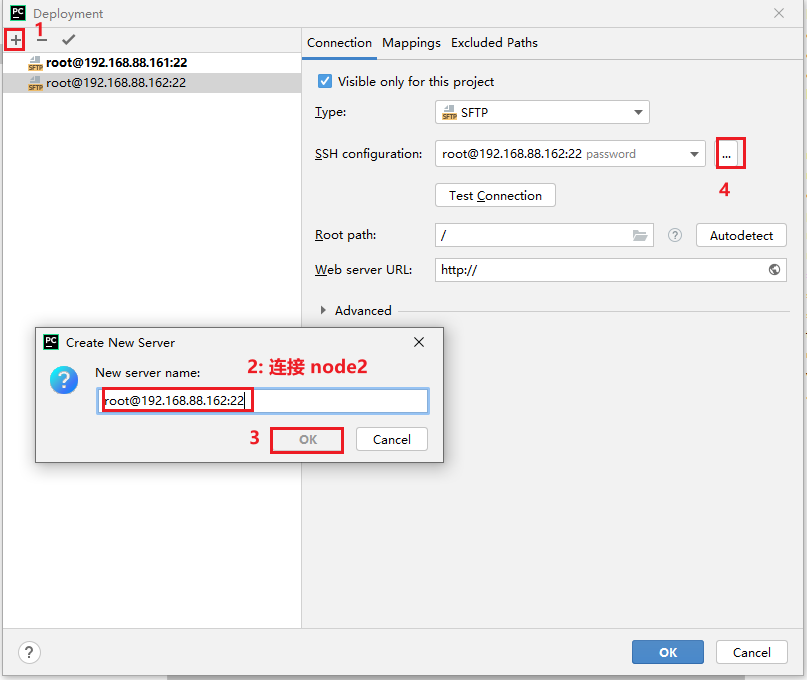
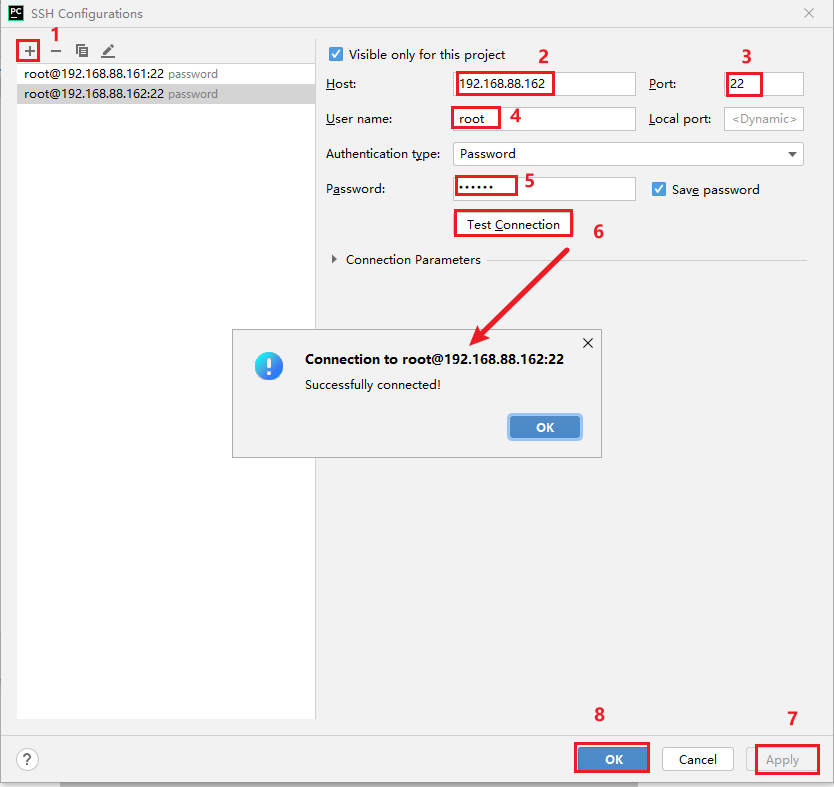
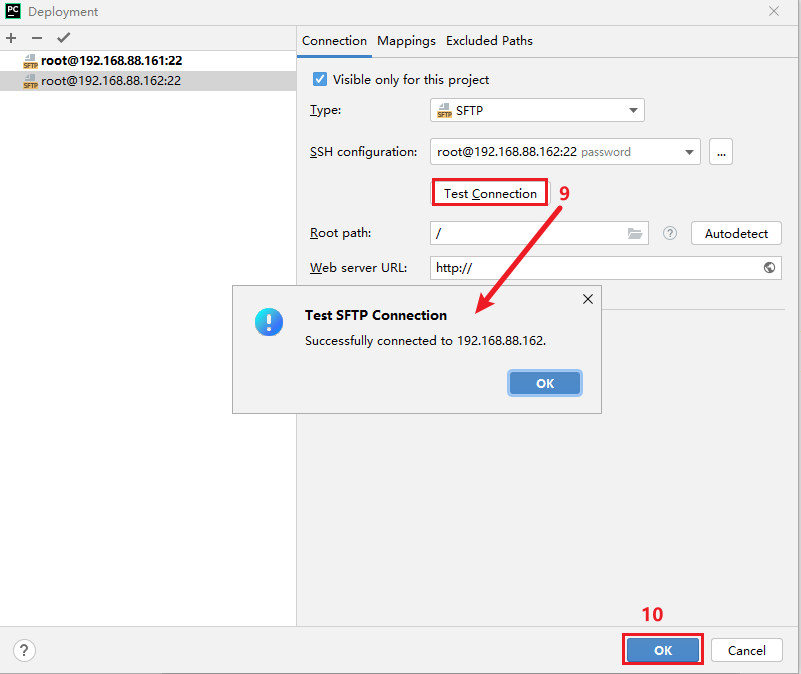

第三台配置与第二台是一模一样的操作
说明:
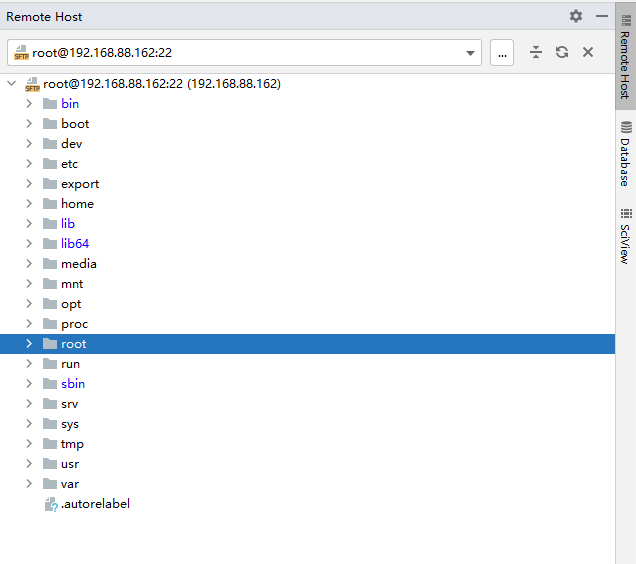
在pycharm中.我们可以直接基于上面目录, 完成对远端文件进行上传 下载 修改 移动 复制, 改名, 修改权限 等等相关操作, 只要是文件系统支持的操作, 在pycharm基本都是可以实现的
如果要进行上传或者下载, 直接拖拽即可完成(仅支持在pycharm内部)6.2.2 尝试打开多个控制台
Section titled “6.2.2 尝试打开多个控制台”
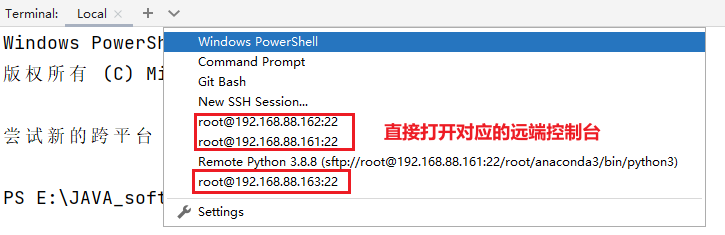
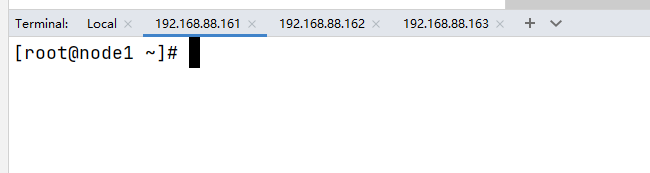
6.3 基于pycharm连接 mysql和 spark SQL
Section titled “6.3 基于pycharm连接 mysql和 spark SQL”6.3.1 连接 mysql
Section titled “6.3.1 连接 mysql”
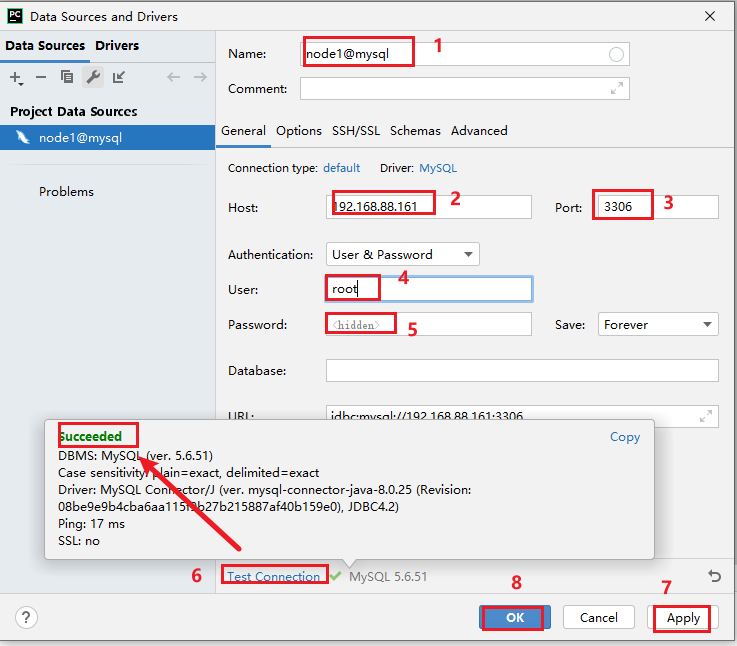
6.3.2 连接 spark
Section titled “6.3.2 连接 spark”- 1- 启动 hadoop环境:
node1: 任意位执行: start-all.sh
执行后 需要校验各个节点是否启动成功:node1: NameNode ResourceManager NodeManager DataNodenode2: NodeManager DataNode SecondaryNameNodenode3: NodeManager DataNode
OK后, 需要打开浏览器: node1:9870 和 node1:8088node1:9870: 需要校验 安全模式是否退出(30s时间) 需要校验 datanode节点存活数量是否3个
node1:8088: 需要校验: active 从节点为 3个- 2- hive的metastore
node1:cd /export/server/hive/binnohup ./hive --service metastore &
启动后, 一定要看一下有runjar的产生, 建议等待一分钟后 在通过 jps查看一次- 3- 启动spark的thrift server服务(模拟 hive的 hiveserver2)
node1:
cd /export/server/spark/sbin./start-thriftserver.sh \--hiveconf hive.server2.thrift.port=10000 \--hiveconf hive.server2.thrift.bind.host=node.itcast.cn \--master local[2]
启动后, 通过 jps查看, 必须看到: SparkSubmit- 4- 通过 pycharm连接spark
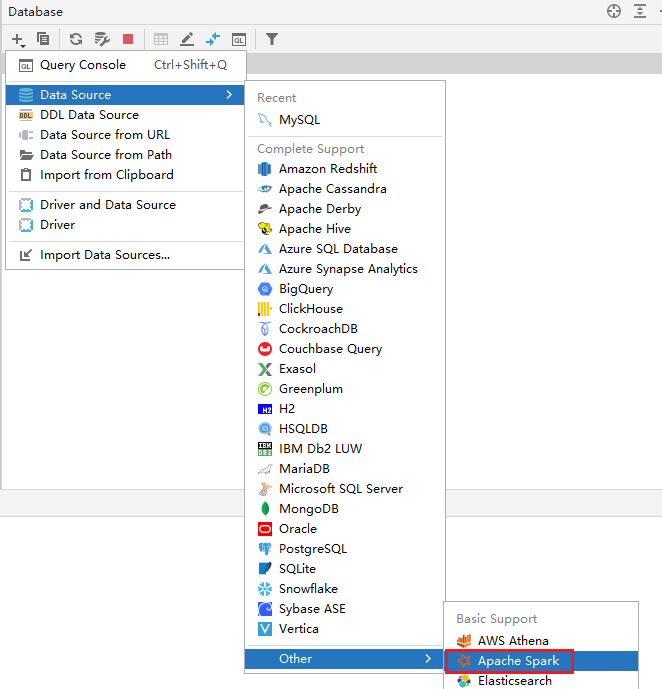
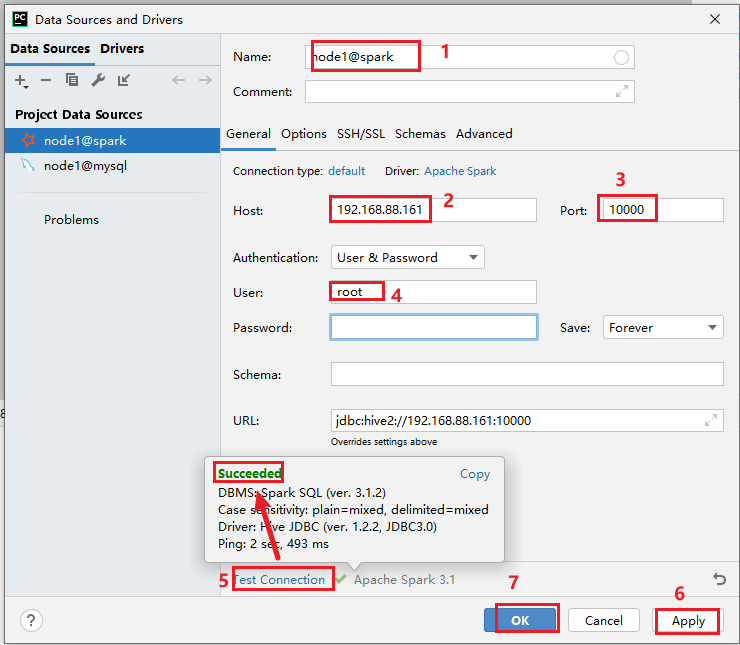
7. 完成基础数据集的导入操作(生产中基本不存在)
Section titled “7. 完成基础数据集的导入操作(生产中基本不存在)”指的: 将数据源的数据导入到MySQL中

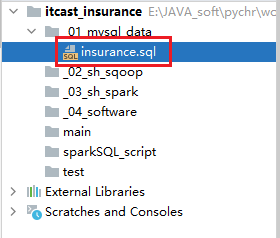
- 1- 将insurance.sql 复制到项目的 _01_mysql_data 目录中
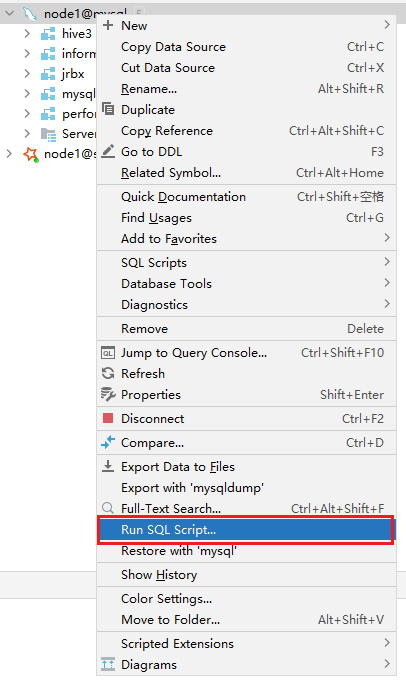
- 2- 执行 SQL脚本
成果:
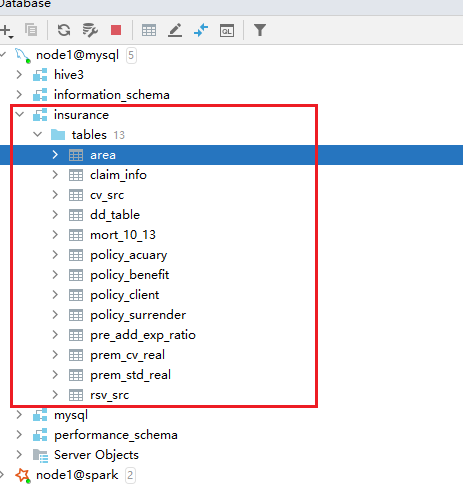
表说明:
| area | 全国行政地区表 |
|---|---|
| claim_info | 理赔信息表 |
| mort_10_13 | 中国人身保险业经验生命表(2010-2013) |
| dd_table | 行业25种重疾发生率 |
| pre_add_exp_ratio | 预定附加费用率 |
| prem_std_real | 标准保费真实参照表 |
| prem_cv_real | 保单价值准备金毛保险费,真实参照表 |
| policy_client | 客户信息表 |
| policy_benefit | 客户投保详情表 |
| policy_surrender | 退保记录表 |
将mysql的数据导出到文件中操作(无需执行):
mysqldump -uroot -p --databases insurance >/opt/insurance/1_data_mysql/insurance.sql 发布于 2022-08-23