
项目主题、ODS、DWD层建设实战
Day04_项目主题、ODS、DWD层建设实战
Section titled “Day04_项目主题、ODS、DWD层建设实战”知识点01:课程内容大纲与学习目标
Section titled “知识点01:课程内容大纲与学习目标”#课程内容大纲 1、项目业务表结构梳理、分析主题梳理 2、DataGrip工具的使用 满足日常开发、提高效率 3、ODS层构建 数据导入的4种方式及实现 4、DWD层构建 渐变维--SCD2--拉链表 背景、设计、实现 例1:拉链导入 例2:全量覆盖导入 例3:增量导入#学习目标 熟悉项目业务表结构、分析主题 掌握DataGrip工具的使用 掌握ODS层数据导入的方式、sqoop的使用 熟练掌握拉链表的背景、设计、实现 掌握DWD层数据导入知识点02:业务系统表结构
Section titled “知识点02:业务系统表结构”- 表结构图
- 订单相关
t_shop_order: 订单主表 记录订单基础信息(买家、卖家、订单来源、订单状态、订单评价状态、取货方式、是否需要备货)t_shop_order_address_detail: 订单副表 记录订单额外信息 与订单主表是1对1关系 (订单金额、优化金额、是否配送、支付接单配送到达完成各时间)t_shop_order_group: 订单组表 多笔订单构成一个订单组 (含orderID)t_order_pay: 订单组支付表 记录订单组支付信息 (订单组ID、订单总金额)t_order_settle: 订单结算表 记录一笔订单中配送员、圈主、平台、商家的分成 (含orderID)t_order_delievery_item: 订单配送表 记录配送员信息、收货人信息、商品信息(含orderID)t_refund_order: 订单退款表 记录退款相关信息(含orderID)t_goods_evaluation: 订单评价表 记录订单综合评分,送货速度评分等(含orderID)t_goods_evaluation_detail: 订单中商品评价信息表 记录订单中对所购买商品的评价信息(含orderID)t_shop_order_goods_details: 订单和商品的中间表 记录订单中商品的相关信息,如商品ID、数量、价格、总价、名称、规格、分类(含orderID)t_trade_record: 交易记录表 记录所有交易记录信息,比如支付、结算、退款- 店铺相关
t_store: 店铺详情表 记录一家店铺的详细信息t_trade_area: 商圈表 记录商圈相关信息,店铺需要归属商圈中t_location: 地址表 记录了地址信息以及地址的所属类别,如是商圈地址还是店铺地址,还是买家地址t_district: 区域字典表 记录了省市县区域的名称、别名、编码、父级区域ID- 商品相关
t_goods: 商品表 记录了商品相关信息t_goods_class: 商品分类表t_brand: 品牌表 记录了品牌的相关信息t_goods_collect: 商品收藏表- 用户相关
t_user_login: 登陆日志表 记录登陆日志信息,如登陆用户、类型、客户端标识、登陆时间、登陆ip、登出时间等t_store_collect: 店铺收藏表 记录用户收藏的店铺IDt_shop_cart: 购物车表 记录用户添加购物车的商品id、商品数量、卖家店铺ID- 系统配置相关
t_date: 时间日期维度表 记录了年月日周、农历等相关信息知识点03:项目分析主题梳理
Section titled “知识点03:项目分析主题梳理”主题是数据综合体,抽象的。一个分析主题的数据可能横跨多个数据源(多个表)。
1、所谓指标指的是该主题需要计算出哪些数据值,来衡量比较大小、好坏、高低、涨跌情况。
2、所谓维度指的是从哪些角度或者多个角度组合起来去计算指标
- 销售主题
- 指标
销售收入、平台收入配送成交额、小程序成交额、安卓APP成交额、苹果APP成交额、PC商城成交额订单量、参评单量、差评单量、配送单量、退款单量、小程序订单量、安卓APP订单量、苹果APP订单量、PC商城订单量- 维度
日期、城市、商圈、店铺、品牌、大类、中类、小类- 商品主题
- 指标
下单次数、下单件数、下单金额被支付次数、被支付金额、被退款次数、被退款件数、被退款金额、被加入购物车次数、被加入购物车件数、被收藏次数好评数、中评数、差评数- 维度
商品、日期- 用户主题
- 指标
登录次数、收藏店铺数、收藏商品数、加入购物车次数、加入购物车金额下单次数、下单金额、支付次数、支付金额- 维度
用户、日期知识点04:DataGrip业务数据导入
Section titled “知识点04:DataGrip业务数据导入”- step1:windows创建工程文件夹
要求无中文,无空格环境
把项目资料中的脚本文件添加至工程文件夹中
- step2:DataGrip创建Project
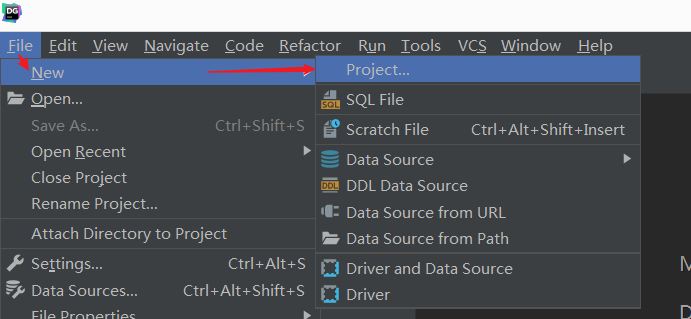
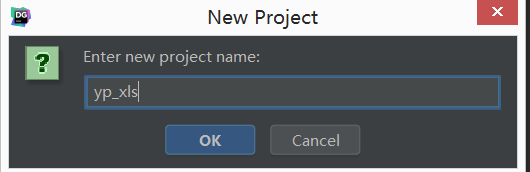

- step3:关联本地工程文件夹
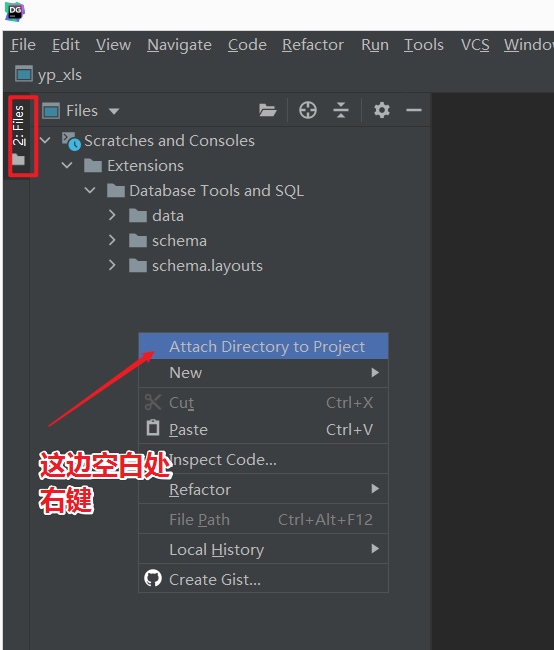
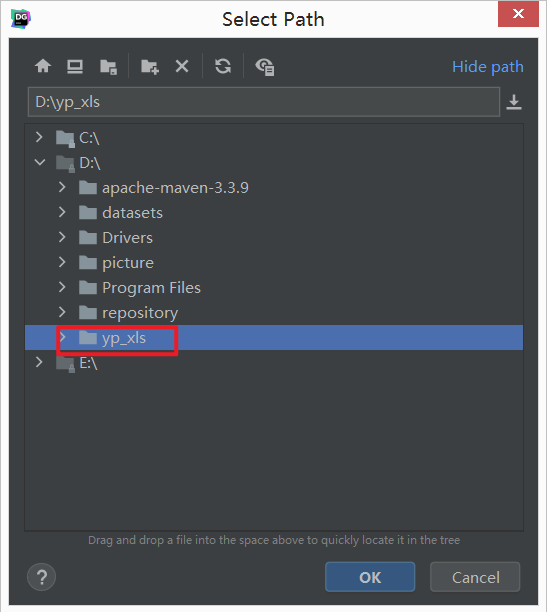
- step4:DataGrip连接MySQL
- step5:导入业务数据
- step6:选中yipin数据库,刷新,查看数据是否正常
知识点05:Hive中文注释乱码问题处理
Section titled “知识点05:Hive中文注释乱码问题处理”- 现象
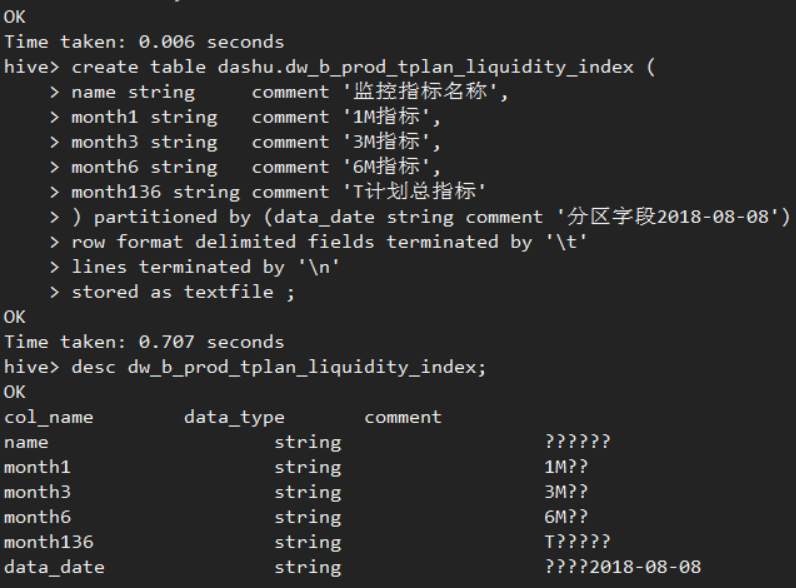
- 原因
Hive元数据信息存储在MySQL中。
Hive要求数据库级别的字符集必须是latin1。但是对于具体表中字段的字符集则没做要求。
默认情况下,字段字符集也是latin1,但是latin1不支持中文。
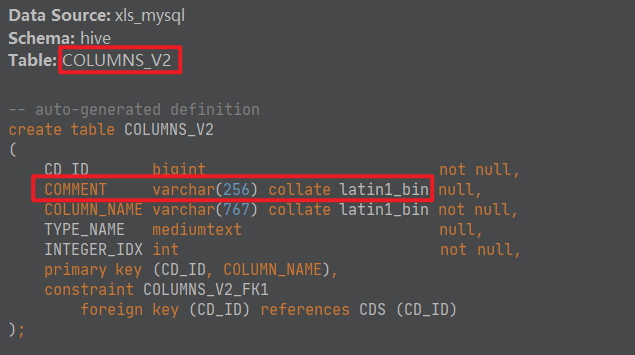
- 解决
在mysql中,对于记录注释comment信息的几个表字段字符集进行修改。
- step1:DataGrip打开MySQL console控制台
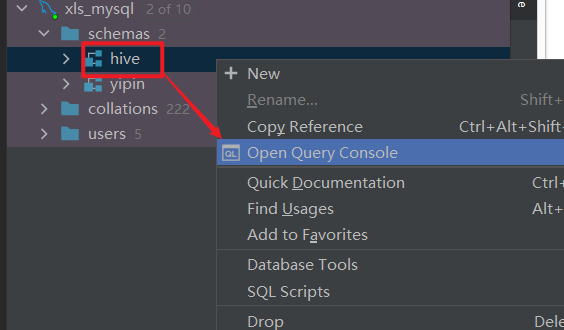
- step2:执行下述sql语句修改字符集
-- 以下语句是在mysql中执行,如果执行完还是乱码,则需要删除数据库,重新创建数据库,再创建表加载数据alter table hive.COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;alter table hive.TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;alter table hive.PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ;alter table hive.PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;alter table hive.INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;- step3:查看验证是否修改成功
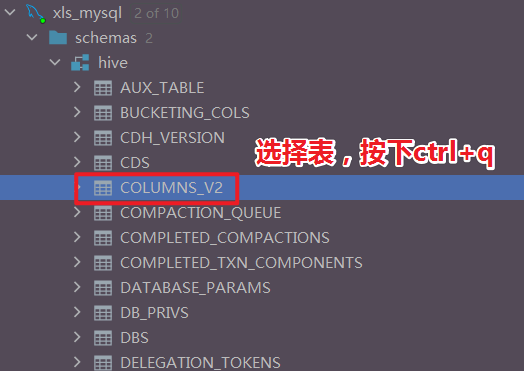
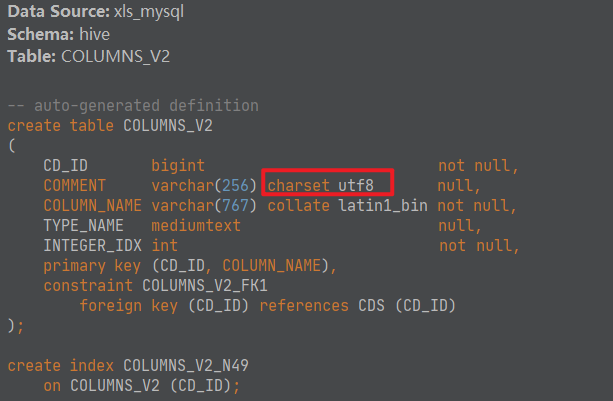
- step4:删除之前hive中创建的表,重新建表
知识点06:ODS层搭建—数据导入同步的方式
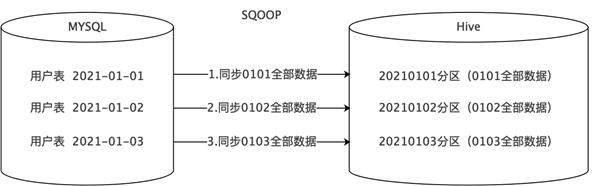
Section titled “知识点06:ODS层搭建—数据导入同步的方式”- 方式1:全量同步
- 每天新增一个日期分区,同步并存储当天的全量数据,历史数据定期删除。
- 适用于数据会有新增和更新,但是数据量较少,且历史快照不用保存很久的情况。
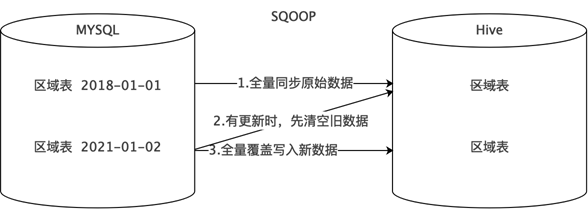
- 方式2:全量覆盖
- 不需要分区,每次同步都是先删后写,直接覆盖。
- 适用于数据不会有任何新增和变化的情况。
- 比如地区、时间、性别等维度数据,不会变更或很少会有变更,可以只保留最新值。
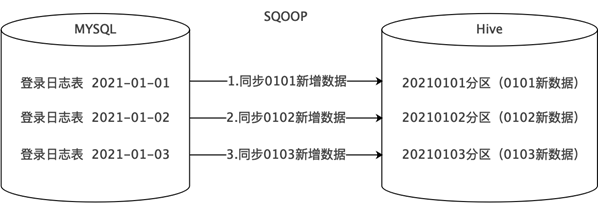
- 方式3:仅新增同步
- 每天新增一个日期分区,同步并存储当天的新增数据。
- 比如登录记录表、访问日志表、交易记录表、商品评价表等。
- 方式4:新增及更新同步
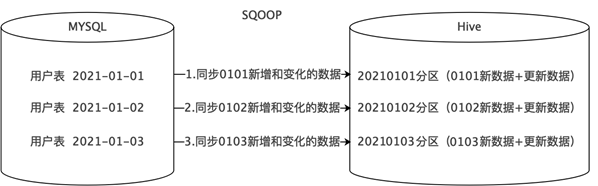
- 每天新增一个日期分区,同步并存储当天的新增和更新数据。
- 适用于既有新增又有更新的数据,比如用户表、订单表、商品表等。
- 首次执行与循环执行
- 首次建库时,需要对OLTP应用中的表全量数据进行采集,因此所有表都使用全量同步。
- 历史数据量可能会非常大,远远超出了增量过程。在执行时需要进行针对性的优化配置并采用分批执行。
- 后续的循环执行大多采用的是T+1模式。
知识点07:DataGrip连接Hive、建库ODS
Section titled “知识点07:DataGrip连接Hive、建库ODS”- DataGrip连接Hive
注意,本项目环境中使用的Hive版本是2.1.1-cdh6.2.1,因此需要使用Hive2版本的驱动。
- 建库ODS
库命名规范:业务简拼_ods,亿品新零售业务的ods层,可以命名为yp_ods。
表命名规范:ods层数据保持与原始数据一致,因此表名可以和原始表名一致。
比如t_shop_order表,可以命名为yp_ods.t_shop_order。
- step1:DataGrip中打开Hive console控制台
- step2:执行建库语句
create database if not exists yp_ods;- step3:选中创建好的数据库,刷新
知识点08:ODS层搭建—数据导入—全量覆盖
Section titled “知识点08:ODS层搭建—数据导入—全量覆盖”不需要分区,每次同步都是先删后写,直接覆盖。
适用于数据不会有任何新增和变化的情况。
比如区域字典表、时间、性别等维度数据,不会变更或很少会有变更,可以只保留最新值。
这里以t_district区域字典表为例,进行讲解。
- step1:ods层建表
提示:可以直接使用项目提供的sql脚本。
DROP TABLE if exists yp_ods.t_district;CREATE TABLE yp_ods.t_district( `id` string COMMENT '主键ID', `code` string COMMENT '区域编码', `name` string COMMENT '区域名称', `pid` int COMMENT '父级ID', `alias` string COMMENT '别名')comment '区域字典表'row format delimited fields terminated by '\t'stored as orc tblproperties ('orc.compress'='ZLIB');- step2:sqoop数据同步
- 因为表采用了ORC格式存储,因此使用sqoop导入数据的时候需要使用HCatalog API。
- 在sqoop并行导入的时候,需要—split-by xxx 这个参数指定数值类型字段进行切分。如果这个字段是一个文本格式,需要在命令中加入选项-Dorg.apache.sqoop.splitter.allow_text_splitter=true
方式1-使用1个maptask进行导入/usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \--username root \--password 123456 \--query "select * from t_district where 1=1 and \$CONDITIONS" \--hcatalog-database yp_ods \--hcatalog-table t_district \-m 1
方式1-使用2个maptask进行导入/usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \--connect 'jdbc:mysql://node1:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \--username root \--password 123456 \--query "select * from t_district where 1=1 and \$CONDITIONS" \--hcatalog-database yp_ods \--hcatalog-table t_district \--split-by id -m 2知识点09:ODS层搭建—数据导入—增量同步
Section titled “知识点09:ODS层搭建—数据导入—增量同步”每天新增一个日期分区,同步并存储当天的新增数据。
比如登录日志表、访问日志表、交易记录表、商品评价表,订单评价表等。
这里以t_user_login登录日志表为例,进行讲解。
- step1:ods层建表
DROP TABLE if exists yp_ods.t_user_login;CREATE TABLE if not exists yp_ods.t_user_login( id string, login_user string, login_type string COMMENT '登录类型(登陆时使用)', client_id string COMMENT '推送标示id(登录、第三方登录、注册、支付回调、给用户推送消息时使用)', login_time string, login_ip string, logout_time string)COMMENT '用户登录记录表'partitioned by (dt string)row format delimited fields terminated by '\t'stored as orc tblproperties ('orc.compress' = 'ZLIB');- step2:sqoop数据同步
- 首次(全量)
1、不管什么模式,首次都是全量同步;再次循环同步的时候,可以自己通过where条件来控制同步数据的范围;
2、${TD_DATE}表示分区日期,正常来说应该是今天的前一天,因为正常情况下,都是过夜里12点,干前一天活,那么数据的分区字段应该属于前一天。
3、这里为了演示,${TD_DATE}先写死。
TD_DATE=
date -d '1 days ago' "+%Y-%m-%d"
#下面这里用于课堂演示/usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \--username root \--password 123456 \--query "select *, '2022-06-11' as dt from t_user_login where 1=1 and \$CONDITIONS" \--hcatalog-database yp_ods \--hcatalog-table t_user_login \-m 1
#下面这是自动化调度方案脚本 需要配合shell执行
#!/bin/bashTD_DATE=`date -d '1 days ago' "+%Y-%m-%d"`
/usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \--username root \--password 123456 \--query "select *, '${TD_DATE}' as dt from t_user_login where 1=1 and \$CONDITIONS" \--hcatalog-database yp_ods \--hcatalog-table t_user_login \-m 1
#你需要创建一个脚本: a.sh#修改脚本权限: chmod +x a.sh#运行脚本/root/a.sh或者./a.sh
= 解释: '${TD_DATE}' 是昨天的日期- 循环(增量同步)
自己通过where条件来控制同步数据的范围;
比如对于t_user_login表,可以通过login_time登录时间这个字段来确定增量数据的范围。
#!/bin/bashdate -s '2022-06-13'#你认为现在是2022-06-13TD_DATE=`date -d '1 days ago' "+%Y-%m-%d"`/usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \--username root \--password 123456 \--query "select *, '${TD_DATE}' as dt from t_user_login where 1=1 and (login_time between '${TD_DATE} 00:00:00' and'${TD_DATE} 23:59:59') and \$CONDITIONS" \--hcatalog-database yp_ods \--hcatalog-table t_user_login \-m 1知识点10:ODS层搭建—数据导入—新增和更新同步
Section titled “知识点10:ODS层搭建—数据导入—新增和更新同步”每天新增一个日期分区,同步并存储当天的新增和更新数据。
适用于既有新增又有更新的数据,比如用户表、订单表、商品表等。
这里以t_store店铺表为例,进行讲解。
- step1:ods层建表
CREATE TABLE yp_ods.t_store( `id` string COMMENT '主键', `user_id` string, `store_avatar` string COMMENT '店铺头像', `address_info` string COMMENT '店铺详细地址', `name` string COMMENT '店铺名称', `store_phone` string COMMENT '联系电话', `province_id` INT COMMENT '店铺所在省份ID', `city_id` INT COMMENT '店铺所在城市ID', `area_id` INT COMMENT '店铺所在县ID', `mb_title_img` string COMMENT '手机店铺 页头背景图', `store_description` string COMMENT '店铺描述', `notice` string COMMENT '店铺公告', `is_pay_bond` TINYINT COMMENT '是否有交过保证金 1:是0:否', `trade_area_id` string COMMENT '归属商圈ID', `delivery_method` TINYINT COMMENT '配送方式 1 :自提 ;3 :自提加配送均可; 2 : 商家配送', `origin_price` DECIMAL, `free_price` DECIMAL, `store_type` INT COMMENT '店铺类型 22天街网店 23实体店 24直营店铺 33会员专区店', `store_label` string COMMENT '店铺logo', `search_key` string COMMENT '店铺搜索关键字', `end_time` string COMMENT '营业结束时间', `start_time` string COMMENT '营业开始时间', `operating_status` TINYINT COMMENT '营业状态 0 :未营业 ;1 :正在营业', `create_user` string, `create_time` string, `update_user` string, `update_time` string, `is_valid` TINYINT COMMENT '0关闭,1开启,3店铺申请中', `state` string COMMENT '可使用的支付类型:MONEY金钱支付;CASHCOUPON现金券支付', `idCard` string COMMENT '身份证', `deposit_amount` DECIMAL(11,2) COMMENT '商圈认购费用总额', `delivery_config_id` string COMMENT '配送配置表关联ID', `aip_user_id` string COMMENT '通联支付标识ID', `search_name` string COMMENT '模糊搜索名称字段:名称_+真实名称', `automatic_order` TINYINT COMMENT '是否开启自动接单功能 1:是 0 :否', `is_primary` TINYINT COMMENT '是否是总店 1: 是 2: 不是', `parent_store_id` string COMMENT '父级店铺的id,只有当is_primary类型为2时有效')comment '店铺表'partitioned by (dt string) row format delimited fields terminated by '\t' stored as orc tblproperties ('orc.compress'='ZLIB');- step2:sqoop数据同步
实现新增及更新同步的关键是,表中有两个跟时间相关的字段:
create_time 创建时间 一旦生成 不再修改
update_time 更新时间 数据变化时间修改
自己通过where条件来控制同步数据的范围。
- 首次
#下面这是自动化调度方案脚本 需要配合shell执行
#!/bin/bashTD_DATE=`date -d '1 days ago' "+%Y-%m-%d"`/usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \--username root \--password 123456 \--query "select *, '${TD_DATE}' as dt from t_store where 1=1 and \$CONDITIONS" \--hcatalog-database yp_ods \--hcatalog-table t_store \-m 1- 循环
注意了,如果这里将时间范围控制在公元前5000年到today,那么不出意外,这应该是全量数据,
其效果和上面的首次导入一样。
今天是哪一天,日期值就应该是今天的前一天。
#下面这是自动化调度方案脚本 需要配合shell执行#!/bin/bashdate -s '2022-06-13'TD_DATE=`date -d '1 days ago' "+%Y-%m-%d"`/usr/bin/sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \--connect 'jdbc:mysql://192.168.88.80:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \--username root \--password 123456 \--query "select *, '${TD_DATE}' as dt from t_store where 1=1 and ((create_time between '${TD_DATE} 00:00:00' and '${TD_DATE} 23:59:59') or (update_time between '${TD_DATE} 00:00:00' and '${TD_DATE} 23:59:59')) and \$CONDITIONS" \--hcatalog-database yp_ods \--hcatalog-table t_store \-m 1知识点11:ODS层搭建—数据导入—最终完整版
Section titled “知识点11:ODS层搭建—数据导入—最终完整版”- 掌握完全量覆盖、增量同步、新增和更新同步如何实现之后
- 对于ODS的表其他操作类比进行。
- 可以使用课程中提供的脚本批量执行,提高效率。
- 注意数据同步之后,最好和mysql数据源表做一次校验比对,同时也验证一下同步数据是否成功、正确。
- step1:关于ODS层建表语句sql文件的执行
- Datagrip中选中sql文件执行
- step2:关于ODS层sqoop数据同步的shell脚本执行
- 执行之前,把脚本中的写死的日期根据当前操作的实际情况修改一下。
- 可以选择复制shell脚本中的sqoop导入命令 一个一个一次执行
- 也可以选择上传shell脚本到hadoop01服务器上,执行如下命令
chmod u+x sqoop_import.shsh sqoop_import.sh
- 这样shell脚本就会依次执行每一个sqoop任务了。知识点12:DWD层搭建—功能职责、事实表维度表识别
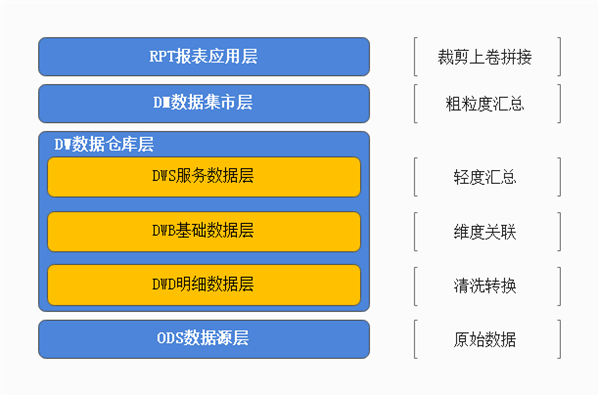
Section titled “知识点12:DWD层搭建—功能职责、事实表维度表识别”- dwd层功能与职责
- dwd层中文叫做明细数据层。
- 主要功能:
- 数据清洗转换、提供质量保证;
- 区分事实、维度。
- 表名规范 dwd.fact_xxxxxx dwd.dim_yyyyyy
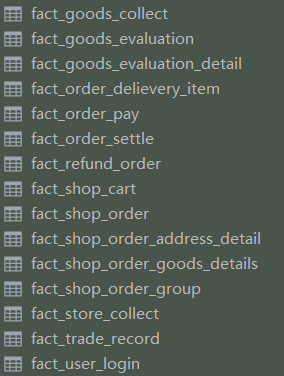
- 事实表
订单主副表、订单结算、订单组、订单退款、订单商品快照、购物车、店铺收藏等
- 维度表
用户、区域、时间、店铺、商圈、地址信息、商品、商品分类、品牌等
- 注意事项
- 有些情况下,一张表到底是属于事实表还是维度表,其实是跟后续的分析主题相关的。
- 主题选取不同,可能对导致表的定位不同。
- 举一个极端的例子:品牌表,如果后续专门研究分析品牌主题,那么做事实表可能更好。
- 本项目总共实现3个主题:销售主题、商品主题、用户主题(练习)
- 使用DataGrip在Hive中创建dwd层
create database if not exists yp_dwd;行存储和列存储
Section titled “行存储和列存储”行存储:TextFile,Sequencefile列存储:ORC,ParQuet
结论: ods层: ORC + ZLIB 考虑到ods层的数据操作不是特别频繁,主要考虑磁盘节省问题 其它层: ORC + SNAPPY 考虑到其他层的数据操作特别频繁,主要考虑查询性能问题Hive如何通过脚本来执行HiveSQL
Section titled “Hive如何通过脚本来执行HiveSQL”方式1: hive -S -e "SQL命令"方式2: hive -f HiveSQL脚本 hive -f "test1.sql"方式3: 可以将hive -f封装在shell脚本中 #!/bin/bash /usr/bin/hive -f /root/test.sql
执行shell脚本,间接执行hive脚本
如何在MySQL中不进入的情况下执行脚本mysql -u root -p123456 < test2.sql知识点13:渐变维—拉链表—背景
Section titled “知识点13:渐变维—拉链表—背景”拉链表属于之前所讲缓慢渐变维中SCD2情况,主要解决的是记录历史状态的问题。
- 详见课堂提供PPT资料
知识点14:渐变维—拉链表—设计
Section titled “知识点14:渐变维—拉链表—设计”- 详见课堂提供PPT资料
知识点15:渐变维—拉链表—实现
Section titled “知识点15:渐变维—拉链表—实现”- 详见课堂提供PPT资料
DWD层职责
Section titled “DWD层职责”1、区分维度表和事实表 事实表:描述的一种客观事实行为2、构建拉链表 如果你想保留历史的状态记录,则可以使用拉链表create database if not exists yp_dwd;知识点16:DWD层搭建—3种导入方式
Section titled “知识点16:DWD层搭建—3种导入方式”
- 方式一:拉链导入
- 适合场景:增量及更新同步表
- 表设计要求:start_date开始时间、end_date结束时间
- start_date 表示数据有效的开始时间 可以作为表的分区字段来使用
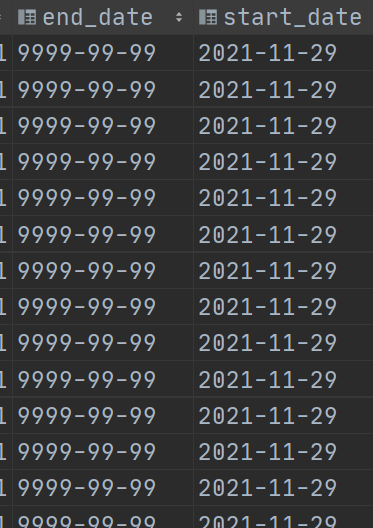
- end_date 表示数据失效的时间,默认数据都是9999-99-99 表示一直有效 。当有更新的时候,通过拉链表操作修改end_date。
- 典型代表:fact_shop_order 订单表、fact_order_settle订单结算表等
- 方式二:全量覆盖导入
- 适合场景:不考虑历史数据是否存在,每次导入直接覆盖
- 表设计要求:没啥要求,也不用分区,也不用拉链。
- 典型代表:dim_district区域字典表、dim_date时间维度表
- 方式三:增量导入
- 适合场景:仅考虑每次的增量数据同步
- 表设计要求:
- 分区表partitioned by (dt string),分区字段往往是时间日期。
- 一个日期一个分区,一次增量导入。
- 典型代表:fact_goods_evaluation订单评价表、fact_user_login登录记录表。
知识点17:DWD层搭建—订单事实表—建表与首次导入
Section titled “知识点17:DWD层搭建—订单事实表—建表与首次导入”- step1:建表操作
-- 1、在DWD层构建的拉链表使用start_date来作为分区字段,这样就可以对拉链表进行分区,提高查询效率-- 2、从DWD层开始,我们表数据存放格式用的是ORC,压缩方式用的是SNAPPY
-- 构建订单事实表的拉链表create database if not exists yp_dwd;-- 1、创建表DROP TABLE if EXISTS yp_dwd.fact_shop_order;CREATE TABLE if not exists yp_dwd.fact_shop_order( -- 拉链表 id string COMMENT '根据一定规则生成的订单编号', order_num string COMMENT '订单序号', buyer_id string COMMENT '买家的userId', store_id string COMMENT '店铺的id', order_from string COMMENT '此字段可以转换 1.安卓\; 2.ios\; 3.小程序H5 \; 4.PC', order_state int COMMENT '订单状态:1.已下单\; 2.已付款, 3. 已确认 \;4.配送\; 5.已完成\; 6.退款\;7.已取消', create_date string COMMENT '下单时间', finnshed_time timestamp COMMENT '订单完成时间,当配送员点击确认送达时,进行更新订单完成时间,后期需要根据订单完成时间,进行自动收货以及自动评价', is_settlement tinyint COMMENT '是否结算\;0.待结算订单\; 1.已结算订单\;', is_delete tinyint COMMENT '订单评价的状态:0.未删除\; 1.已删除\;(默认0)', evaluation_state tinyint COMMENT '订单评价的状态:0.未评价\; 1.已评价\;(默认0)', way string COMMENT '取货方式:SELF自提\;SHOP店铺负责配送', is_stock_up int COMMENT '是否需要备货 0:不需要 1:需要 2:平台确认备货 3:已完成备货 4平台已经将货物送至店铺 ', create_user string, create_time string, update_user string, update_time string, is_valid tinyint COMMENT '是否有效 0: false\; 1: true\; 订单是否有效的标志', end_date string COMMENT '拉链结束日期') COMMENT '订单表'partitioned by (start_date string)row format delimited fields terminated by '\t'stored as orc tblproperties ('orc.compress' = 'SNAPPY');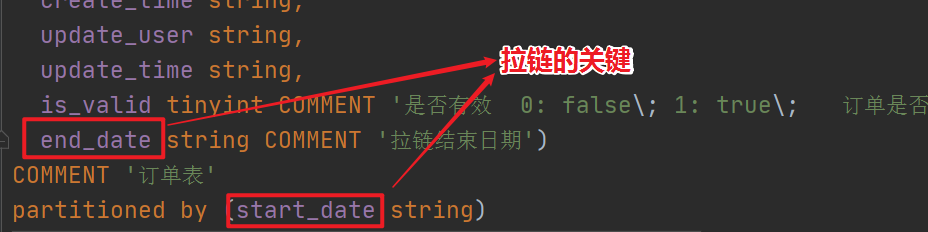
- step2:首次导入
- 如果是动态分区插入,别忘了相关参数
- 如果ods层中表的字段有枚举类型,可以在ETL到dwd的过程中使用case when语句转换。
- step3:查看验证表结果
知识点18:DWD层搭建—订单事实表—循环与拉链导入
Section titled “知识点18:DWD层搭建—订单事实表—循环与拉链导入”- step1:修改mysql中t_shop_order表数据
模拟业务有新增订单、更新订单数据发生;
因为上次ODS导入时,指定分区时间为2022-06-12,所以这里在模拟数据时把时间设为2022-06-13这一天的的新增及更新操作。
--新增订单INSERT INTO yipin.t_shop_order (id, order_num, buyer_id, store_id, order_from, order_state, create_date, finnshed_time, is_settlement, is_delete, evaluation_state, way, is_stock_up, create_user, create_time, update_user, update_time, is_valid)VALUES ('dd88888888888888', '251', '2f322c3f55e211e998ec7cd30ad32e2e', 'e438ca06cdf711e998ec7cd30ad32e2e', 3, 2, '2022-06-22 17:52:23', null, 0, 0, 0, 'SELF', 0, '2f322c3f55e211e998ec7cd30ad32e2e', '2022-06-22 17:52:23', '2f322c3f55e211e998ec7cd30ad32e2e', '2022-06-22 18:52:34', 1);
--更新订单UPDATE yipin.t_shop_orderSET order_num=888, update_time='2022-06-22 12:12:12'WHERE id = 'dd190601303220fc01';- step2:ODS层抽取新增、更新数据
- 使用sqoop新增和更新同步实现。
--在mysql中,首先验证sql能否够将新增及更新数据查询出来select *, '2022-06-22' as dt from t_shop_order where 1=1 and (create_time between '2022-06-22 00:00:00' and '2022-06-22 23:59:59') or (update_time between '2022-06-22 00:00:00' and '2022-06-22 23:59:59')
sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \ --connect 'jdbc:mysql://node1:3306/yipin?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \ --username root \ --password 123456 \ --query "select *, '2022-06-22' as dt from yipin.t_shop_order t where 1=1 and (t.create_time between '2022-06-22 00:00:00' and '2022-06-22 23:59:59') or (t.update_time between '2022-06-22 00:00:00' and '2022-06-22 23:59:59') and \$CONDITIONS" \ --hcatalog-database yp_ods \ --hcatalog-table t_shop_order \ -m 1- step3:创建中间临时表,用于保存拉链结果
临时表的结构和最终的拉链表结构一样。
DROP TABLE if EXISTS yp_dwd.fact_shop_order_tmp;CREATE TABLE yp_dwd.fact_shop_order_tmp( id string COMMENT '根据一定规则生成的订单编号', order_num string COMMENT '订单序号', buyer_id string COMMENT '买家的userId', store_id string COMMENT '店铺的id', order_from string COMMENT '此字段可以转换 1.安卓\; 2.ios\; 3.小程序H5 \; 4.PC', order_state int COMMENT '订单状态:1.已下单\; 2.已付款, 3. 已确认 \;4.配送\; 5.已完成\; 6.退款\;7.已取消', create_date string COMMENT '下单时间', finnshed_time timestamp COMMENT '订单完成时间,当配送员点击确认送达时,进行更新订单完成时间,后期需要根据订单完成时间,进行自动收货以及自动评价', is_settlement tinyint COMMENT '是否结算\;0.待结算订单\; 1.已结算订单\;', is_delete tinyint COMMENT '订单评价的状态:0.未删除\; 1.已删除\;(默认0)', evaluation_state tinyint COMMENT '订单评价的状态:0.未评价\; 1.已评价\;(默认0)', way string COMMENT '取货方式:SELF自提\;SHOP店铺负责配送', is_stock_up int COMMENT '是否需要备货 0:不需要 1:需要 2:平台确认备货 3:已完成备货 4平台已经将货物送至店铺 ', create_user string, create_time string, update_user string, update_time string, is_valid tinyint COMMENT '是否有效 0: false\; 1: true\; 订单是否有效的标志', end_date string COMMENT '拉链结束日期')COMMENT '订单表'partitioned by (start_date string)row format delimited fields terminated by '\t'stored as orc tblproperties ('orc.compress' = 'SNAPPY')- step4:拉链操作,结果to临时表
insert overwrite table yp_dwd.fact_shop_order_tmp--第一个select查的是ods层新增的数据selectt.id as id,t.order_num as order_num,t.buyer_id as buyer_id,t.store_id as store_id,case t.order_from when '1' then 'android' when '2' then 'ios' when '3' then 'miniapp' when '4' then 'pcweb' else 'other' end as order_from,t.order_state as order_state,t.create_date as create_date,t.finnshed_time as finnshed_time,t.is_settlement as is_settlement,t.is_delete as is_delete,t.evaluation_state as evaluation_state,t.way as way,t.is_stock_up as is_stock_up,t.create_user as create_user,t.create_time as create_time,t.update_user as update_user,t.update_time as update_time,t.is_valid as is_valid,'9999-99-99' as end_date,substr(t.create_time, 0, 10) as start_datefrom yp_ods.t_shop_order twhere 1 = 1 and (t.create_time between '2022-06-22 00:00:00' and '2022-06-22 23:59:59')
union all
--第二个select是为了将dwd层原来的数据(有变更的)设置为失效selectt1.id,t1.order_num,t1.buyer_id,t1.store_id,t1.order_from,t1.order_state,t1.create_date,t1.finnshed_time,t1.is_settlement,t1.is_delete,t1.evaluation_state,t1.way,t1.is_stock_up,t1.create_user,t1.create_time,t1.update_user,t1.update_time,t1.is_valid,-- 若左关联ods的表的结果为null,则代表这条数据没有更新,按原来的数据算-- 若左关联ods的表结果不为null,则代表这个数据有更新,原dwd层的数据设置为失效(END_DATE更新)if((t2.id is null or t1.end_date < '9999-99-99'), t1.end_date, '2022-06-21') as end_date,t1.start_datefrom yp_dwd.fact_shop_order t1 left join (select * from yp_ods.t_shop_order where dt='2022-06-22') t2 on t1.id=t2.id where 1=1;- step5:查询临时表验证
select *from yp_dwd.fact_shop_order_tmp where id='dd190601303220fc01';
--可以看到,这条订单有两条数据--第一条根据end_date信息可以表名是历史状态数据--第一条根据end_date信息是9999-99-99表明是当前有效的状态数据- step6:临时表结果覆盖拉链表
INSERT OVERWRITE TABLE yp_dwd.fact_shop_order partition (start_date)SELECT * from yp_dwd.fact_shop_order_tmp;知识点19:DWD层搭建—时间维度表—全量覆盖导入
Section titled “知识点19:DWD层搭建—时间维度表—全量覆盖导入”- 建表操作
DROP TABLE if EXISTS yp_dwd.dim_district;CREATE TABLE yp_dwd.dim_district( id string COMMENT '主键ID', code string COMMENT '区域编码', name string COMMENT '区域名称', pid string COMMENT '父级ID', alias string COMMENT '别名')COMMENT '区域字典表'row format delimited fields terminated by '\t'stored as orctblproperties ('orc.compress' = 'SNAPPY');- 全量覆盖操作
INSERT overwrite TABLE yp_dwd.dim_districtselect * from yp_ods.t_districtWHERE code IS NOT NULL AND name IS NOT NULL;知识点20:DWD层搭建—订单评价表—增量导入
Section titled “知识点20:DWD层搭建—订单评价表—增量导入”- 建表
#解释:每一次增量的数据都创建一个分区进行保存
DROP TABLE if EXISTS yp_dwd.fact_goods_evaluation;CREATE TABLE yp_dwd.fact_goods_evaluation( id string, user_id string COMMENT '评论人id', store_id string COMMENT '店铺id', order_id string COMMENT '订单id', geval_scores int COMMENT '综合评分', geval_scores_speed int COMMENT '送货速度评分0-5分(配送评分)', geval_scores_service int COMMENT '服务评分0-5分', geval_isanony tinyint COMMENT '0-匿名评价,1-非匿名', create_user string, create_time string, update_user string, update_time string, is_valid tinyint COMMENT '0 :失效,1 :开启')COMMENT '订单评价表'partitioned by (dt string)row format delimited fields terminated by '\t'stored as orctblproperties ('orc.compress' = 'SNAPPY');- 第一次导入(全量)
-- 从ods层进行加载INSERT overwrite TABLE yp_dwd.fact_goods_evaluation PARTITION(dt)select id, user_id, store_id, order_id, geval_scores, geval_scores_speed, geval_scores_service, geval_isanony, create_user, create_time, update_user, update_time, is_valid, substr(create_time, 1, 10) as dt -- 2022-06-12from yp_ods.t_goods_evaluation;- 增量导入操作
#1、在MySQL中添加新增数据INSERT INTO `t_goods_evaluation`VALUES ('00a56b465bfb11e998ec7cd30ad32e21', '430eff5a55d911e998ec7cd30ad32e2e', '7b09b44e5b6d11e998ec7cd30ad32e2e', 'dd190411306814f411', 10, 10, 10, 1, '430eff5a55d911e998ec7cd30ad32e2e', '2022-06-13 09:42:02', NULL, NULL, 1), ('02b78f65636811e998ec7cd30ad32e21', '90ec8d524eaa11e998ec7cd30ad32e2e', '5d3b50ab601c11e998ec7cd30ad32e2e', 'dd1904203696383c11', 10, 10, 10, 1, '90ec8d524eaa11e998ec7cd30ad32e2e', '2022-06-13 20:29:58', NULL, NULL, 1), ('03add7e8754d11e998ec7cd30ad32e21', '1e851bf8642e11e998ec7cd30ad32e2e', 'b169106f695311e998ec7cd30ad32e2e', 'dd1905123740785aa1', 10, 10, 10, 0, '1e851bf8642e11e998ec7cd30ad32e2e', '2022-06-13 15:02:05', NULL, NULL, 1), ('046d29a7634711e998ec7cd30ad32e21', '3c3bcb4f55bc11e998ec7cd30ad32e2e', '5d3b50ab601c11e998ec7cd30ad32e2e', 'dd1904203530974fc1', 10, 10, 10, 1, '3c3bcb4f55bc11e998ec7cd30ad32e2e', '2022-06-13 16:33:48', NULL, NULL, 1), ('0513896665b511e998ec7cd30ad32e21', '835ddd8c633911e998ec7cd30ad32e2e', 'd5da2741552611e998ec7cd30ad32e2e', 'dd190421325267961f1', 10, 10, 10, 1, '835ddd8c633911e998ec7cd30ad32e2e', '2022-06-13 18:46:16', NULL, NULL, 1);
#2、将MySQL中新增数据导入到ods层sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \--connect 'jdbc:mysql://192.168.88.80:3306/yipin?enabledTLSProtocols=TLSv1.2&useUnicode=true&characterEncoding=UTF-8&autoReconnect=true' \--username root \--password 123456 \--query "select *, '2022-06-13' as dt from t_goods_evaluation where 1=1 and (create_time between '2022-06-13 00:00:00' and '2022-06-13 23:59:59') and \$CONDITIONS" \--hcatalog-database yp_ods \--hcatalog-table t_goods_evaluation \-m 1
#3、将ods层新导入的数据加载到dwd
INSERT overwrite TABLE yp_dwd.fact_goods_evaluation PARTITION(dt)select id, user_id, store_id, order_id, geval_scores, geval_scores_speed, geval_scores_service, geval_isanony, create_user, create_time, update_user, update_time, is_valid, substr(create_time, 1, 10) as dtfrom yp_ods.t_goods_evaluationwhere dt='2022-06-13';知识点21:DWD层搭建—最终完整版
Section titled “知识点21:DWD层搭建—最终完整版”
- 对于DWD的层中其他表操作,可以使用课程中提供的脚本批量执行,提高效率。
- 前提是:必须掌握拉链表的使用。
附件:Hive相关配置参数
Section titled “附件:Hive相关配置参数”--分区SET hive.exec.dynamic.partition=true;SET hive.exec.dynamic.partition.mode=nonstrict;set hive.exec.max.dynamic.partitions.pernode=10000;set hive.exec.max.dynamic.partitions=100000;set hive.exec.max.created.files=150000;--hive压缩set hive.exec.compress.intermediate=true;set hive.exec.compress.output=true;--写入时压缩生效set hive.exec.orc.compression.strategy=COMPRESSION;