
Hive&Spark问题
发布于 2022-10-02
hive高频问题和解答
Section titled “hive高频问题和解答”一、什么是数据仓库:
Section titled “一、什么是数据仓库:”- 是存储数据的仓库,
- 不生产数据,也不消费数据。
- 有4大特征:1-面向主题,2-集成性,3-非易失性,4-时变性
二、建模的方法
Section titled “二、建模的方法”- 有【三范式建模】和【维度建模】,大数据数仓用维度建模。
- 三范式建模:尽量不冗余,表数量较多。更适合业务系统, OLTP
- 维度建模: 形成少量宽表,宽表内允许大量冗余,更适合离线数仓,OLAP
三、维度建模的模型:
Section titled “三、维度建模的模型:”- 星形模型:一个事实表,周围有多个维度表关联他,
- 星座模型:多个星形模型间共用维度表。
- 雪花模型:在星形模型的基础上,维度表又关联子维度表。
四、维度建模的一般过程:
Section titled “四、维度建模的一般过程:”- 或问:维度建模的步骤:
- 1-选择业务过程 2-声明粒度 3-确认维度 4-确认事实
- 面试官再问:请结合项目来回答。通用模板:
- 我做的主题(或看板、模块)业务是XX(如销售),需要从mysql(或oracle。。。)的数百上千张表中选择23张表,导入ODS层。后续的层,我设计了细粒度的DWD,它只做清洗转换,粗粒度的DWS层,按日聚合,更粗的上卷的DM层或APP层。在DWD层或ODS层我将23张表区分成了x张事实表,y张维度表。对于我要做的统计需求,它写着”请统计每个aa每个bb每个cc。。。的销售额mm,销售量nn,。。“,我对它识别出来维度是aa,bb,cc,我决定关联那些y张维度表,我识别到mm,nn是指标,决定去x张事实表里找事实明细以便分组聚合。
- 以新零售为例:
- 我做的主题业务是销售主题,需要从mysql的数百上千张表中选择23张表,导入ODS层。后续的层,我设计了细粒度的DWD,它只做清洗转换,粗粒度的DWS层,按日聚合,更粗的上卷的DM层或APP层。在DWD层或ODS层我将23张表区分成了13张事实表,10张维度表。对于我要做的统计需求,它写着”请统计每天每个城市每个店铺的销售额,退款额,配送额,销售单量,退款单量。。“,我对它识别出来维度是日期,城市,店铺,我决定关联那10张维度表里的日期维度表,城市维度信息表,店铺维度信息表等,我还识别到销售额,退款额,配送额,销售单量,退款单量是指标,决定去13张事实表里关联订单信息表,退款信息表,配送信息表,找到事实明细以便聚合统计。
五、如何区分事实表和维度表
Section titled “五、如何区分事实表和维度表”- 事实表【每条记录像在讲一个故事】
- 一般是在一个时间点,发生了一件事,一般有数字度量比如金额。
- 比如交易信息表,登录日志表。
- 可以加上fact_前缀
- 后期新增的频率比较剧烈。
- 维度表【每条记录描述了一个事物或人物】
- 一般是描述事物的性质,或看待事物的角度。
- 比如客户信息表,地区,日期等。
- 表名可以加dim_前缀
- 又分为,高基数维度表和低基数维度表。
- 后期新增的频率比较缓慢。
六、hive的优化措施
Section titled “六、hive的优化措施”回答这个问题最好要有层次,每个层次回答2~3个点即可。
- 我从3个层面来做优化:
- 【1】-从建表的层面
create table order_info( order_id int, age tinyint)partitioned by (day string)clustered by(id)sorted by (id desc) -- 分桶时,数据默认按照分桶键升序排列into 4 bucketsstored as orc tblproperties( 'orc.compress'='snappy', 'orc.create.index'='true', "orc.bloom.filter.columns"="pcid",);select * from order_info where pcid<100- 1-使用ORC格式+snappy压缩。
- 2-ORC格式可以设置行组索引和布隆过滤器索引。
- 仅当是ORC格式时,索引才有意义,否则没有太大意义,hive3已经将索引废弃了。
- 3-大表最好建成分区表。还可以进一步建成分桶表。
- 4-数据类型最小化原则,比如年龄用tinyint,不用int
- 【2】-从参数设置层面
- 1-开启group by的负载均衡 set hive.groupby.skewindata=true
- 2-开启map端预聚合 set hive.map.aggr=true【与Spark中的RDD的reduceByKey很像】
- 3-jvm重用,推测执行。 需要去Hadoop的mapred-site.xml中进行配置
- 4-开启mapjoin
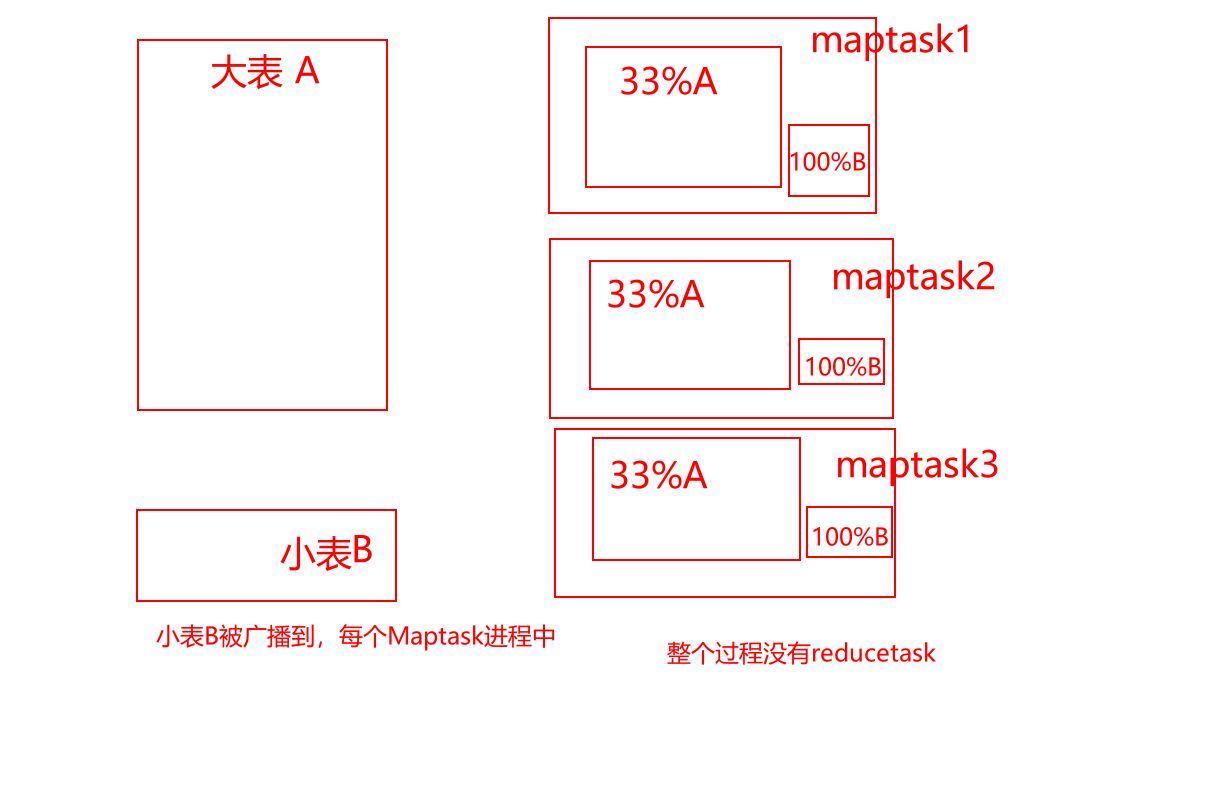
- 由4个参数控制:
--是否自动转换为mapjoinset hive.auto.convert.join = true;--小表的最大文件大小,默认为25000000,即25Mset hive.mapjoin.smalltable.filesize = 25000000;--是否将多个mapjoin合并为一个set hive.auto.convert.join.noconditionaltask = true;--多个mapjoin转换为1个时,所有小表的文件大小总和的最大值。set hive.auto.convert.join.noconditionaltask.size = 10000000;--假设有大表a,小表b,小表cselect *from aleft join b on a.id=b.idleft join c on a.id=c.id--拆成2个语句--mapjoin1select *from aleft join b on a.id=b.id--mapjoin2select *from aleft join c on a.id=c.id - 操作1--是否自动转换为mapjoinset hive.auto.convert.join = false;--因为上面是false,则另3个参数失效,所以无需设置另3个参数--下面只有2个表,其中大表90M,小表7M低于25M 。--下面的执行计划会看到【reduce join operator】,不会触发map join机制explain select * from bigtable aleft join smalltable1 b on a.sid=b.sidleft join smalltable2 c on a.sid=c.sid - 操作2--是否自动转换为mapjoinset hive.auto.convert.join = true;--小表的最大文件大小,默认为25000000,即25Mset hive.mapjoin.smalltable.filesize = 25000000;--下面只有2个表,其中大表90M,小表7M低于25M,会触发map join机制。--所以不会看到【reduce join operator】,会看到【map join operator】explain select * from bigtable aleft join smalltable1 b on a.sid=b.sid--下面的执行计划,有3个表,其中大表90M,b表7M低于25M,c表7M也低于25M,--7+7=14M,合起来<25M,也就是'合起来足够小',所以仍然会看到【map join operator】explain select * from bigtable aleft join smalltable1 b on a.sid=b.sidleft join smalltable2 c on a.sid=c.sid - 操作3--是否自动转换为mapjoinset hive.auto.convert.join = true;--小表的最大文件大小,默认为25000000,即25M,现手动改成10Mset hive.mapjoin.smalltable.filesize = 10000000;--下面的执行计划,有3个表,其中大表90M,b表7M低于10M,c表7M也低于10M,--7+7=14M,合起来>10M,也就是'合起来不够小',所以会看到【reduce join operator】,不会触发map joinexplain select * from bigtable aleft join smalltable1 b on a.sid=b.sidleft join smalltable2 c on a.sid=c.sid - 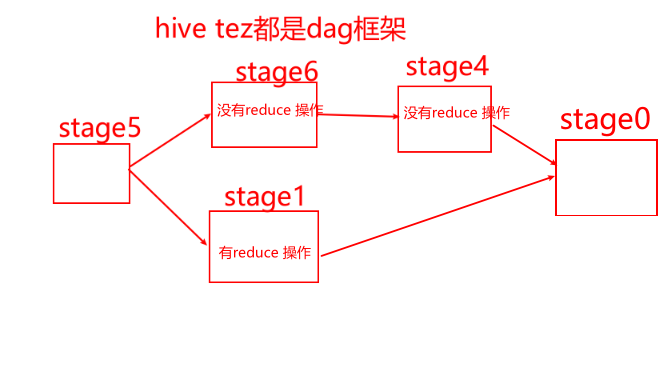 - 操作4,3个表及以上join时,noconditionaltask才有意义。虽然引入noconditionaltask,但是14M>10M,所以noconditionaltask不起作用--是否自动转换为mapjoinset hive.auto.convert.join = true;--小表的最大文件大小,默认为25000000,即25Mset hive.mapjoin.smalltable.filesize = 25000000;--是否将多个mapjoin合并为一个set hive.auto.convert.join.noconditionaltask = true;--多个mapjoin转换为1个时,所有小表的文件大小总和的最大值。set hive.auto.convert.join.noconditionaltask.size = 10000000;--下面的执行计划,有3个表,其中大表90M,b表7M低于25M,c表7M也低于25M,--7+7=14M,合起来虽然<25M,但是>10M,会触发map join,但是会有多个stage阶段。explain select * from bigtable aleft join smalltable1 b on a.sid=b.sidleft join smalltable2 c on a.sid=c.sid - 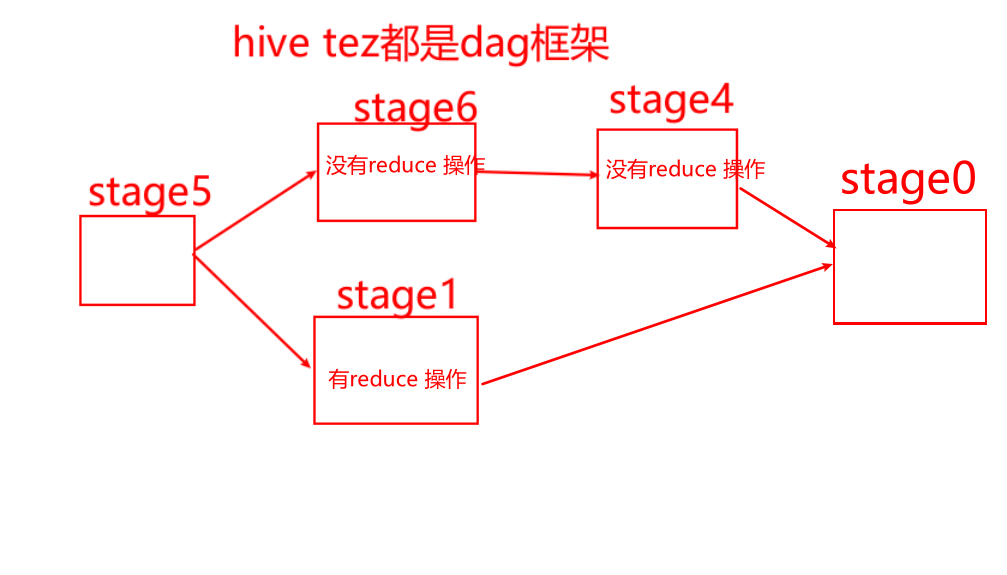 - 操作5,将noconditionaltask.size从10M提升到20M,14M<20M,所以noconditionaltask起作用了--是否自动转换为mapjoinset hive.auto.convert.join = true;--小表的最大文件大小,默认为25000000,即25Mset hive.mapjoin.smalltable.filesize = 25000000;--是否将多个mapjoin合并为一个set hive.auto.convert.join.noconditionaltask = true;--多个mapjoin转换为1个时,所有小表的文件大小总和的最大值。set hive.auto.convert.join.noconditionaltask.size = 20000000;--下面的执行计划,有3个表,其中大表90M,b表7M低于25M,c表7M也低于25M,--7+7=14M,合起来既<25M,又<20M(故意手动提升10M到20M),不仅会触发map join,又会将多个stage阶段合并成1个stage。explain select * from bigtable aleft join smalltable1 b on a.sid=b.sidleft join smalltable2 c on a.sid=c.sid - 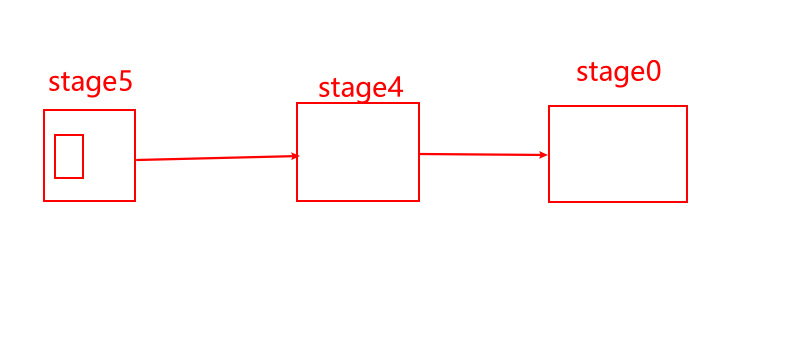 - 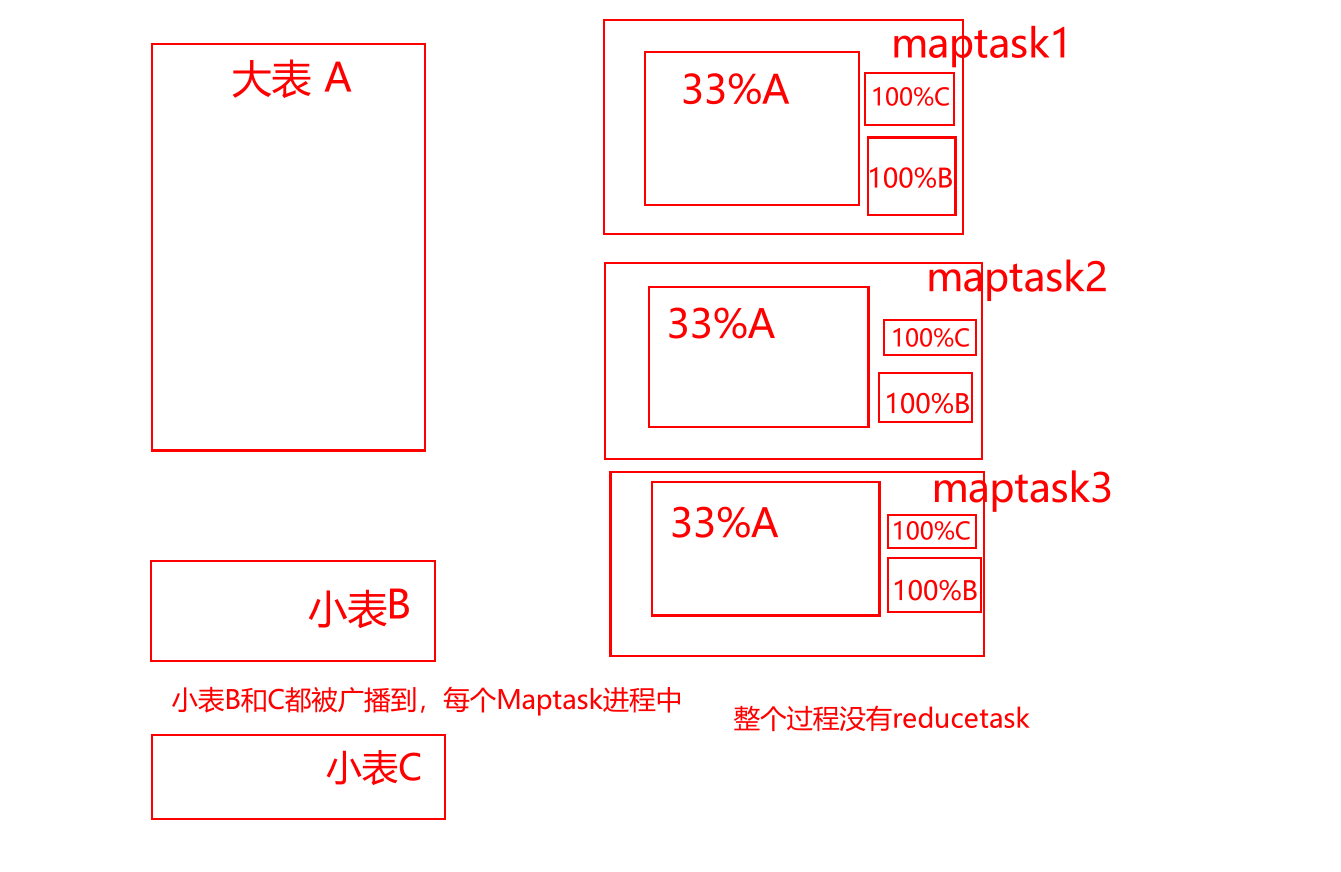 - 比如遇到一个30M的小表,可以将mapjoin的小表阈值提升到40M,则30M<40M,就可以走mapjoin。在DWB层店铺宽表,mapjoin的小表阈值提升到40M,运行时间缩减50%。20分钟->10分钟。小结:参数Aset hive.mapjoin.smalltable.filesize = 25000000;参数Bset hive.auto.convert.join.noconditionaltask.size = 10000000;如果小表合起来>参数A,则mapjoin不起作用如果小表合起来<参数A,但是>参数B,则mapjoin起作用,但是会有多个stage阶段如果小表合起来<参数A,也<参数B,则mapjoin起作用,而且将多个stage阶段,合并成1个stage。- 5-reduce端的个数,内存大小
- 一般来说,MapReduce的性能瓶颈,会出现在reduce端更多一些。
- 一般来说,reduce的个数和内存大小,越多越好
- 手动指定reduce端的个数 set mapreduce.job.reduces = 5;
- 让程序自动推断reduce的个数set mapreduce.job.reduces = -1;set hive.exec.reducers.max=1009;set hive.exec.reducers.bytes.per.reducer=256000000;
- 双11,双12, 618,数据量暴增,reduce端的个数之前是20个,跑批失败,现增加到40个,且reduce内存加大,跑批成功。
- 6-合并小文件

//设置map端输出进行合并,默认为trueset hive.merge.mapfiles = true//设置reduce端输出进行合并,默认为falseset hive.merge.mapredfiles = true//设置合并文件的大小set hive.merge.size.per.task = 256*1000*1000//当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。set hive.merge.smallfiles.avgsize=16000000- 【3】-从SQL编写层面
- 1-对分区表进行分区限制 where 分区字段=‘具体值’ 或者 分区字段>=‘具体值’,则不会加载全表。
- 2-表在join之前,提前where过滤无用数据。(谓词下推)
select *from table1 ajoin table2 b on a.id=b.idwhere a.age>20 and b.sex='男' - 优化成select *from (select * from table1 where age>20) ajoin (select * from table2 where sex='男') b on a.id=b.id- 3-不写select * ,而枚举具体字段。(列值裁剪)
select a.age, a.name, b.sexfrom (select * from table1 where age>20) ajoin (select * from table2 where sex='男') b on a.id=b.id - 优化为select a.age, a.name, b.sexfrom (select id,age,name from table1 where age>20) ajoin (select id,sex from table2 where sex='男') b on a.id=b.id- 4-用2次group by + count(),替代count(distinct)
--写法一select sex ,count(distinct age ) as cnt from a group by sex;--写法二select sex, count(age) as cntfrom (select sex, age from a group by sex, age) as xgroup by sex;- 5-用【a inner join b】 替代 【in】 , 用【select a.* from a left join b on a.id=b.id where b.id is null】 替代 【not in】
select * from a where a.id in (select id form b);--用【a inner join b】 替代 【in】select a.* from a join b on a.id=b.id;select * from a where a.id not in (select id form b);-- 用【select a.* from a left join b on a.id=b.id where b.id is null】 替代 【not in】select a.* from a left join b on a.id=b.id where b.id is null;- 6-将union all用grouping sets代替
- 7-将空值的key加上随机数 或 过滤掉空值数据(where a.id is not null or lower(a.id)!=‘null’)。
- 将倾斜的key单独计算再跟非倾斜的key union all起来。
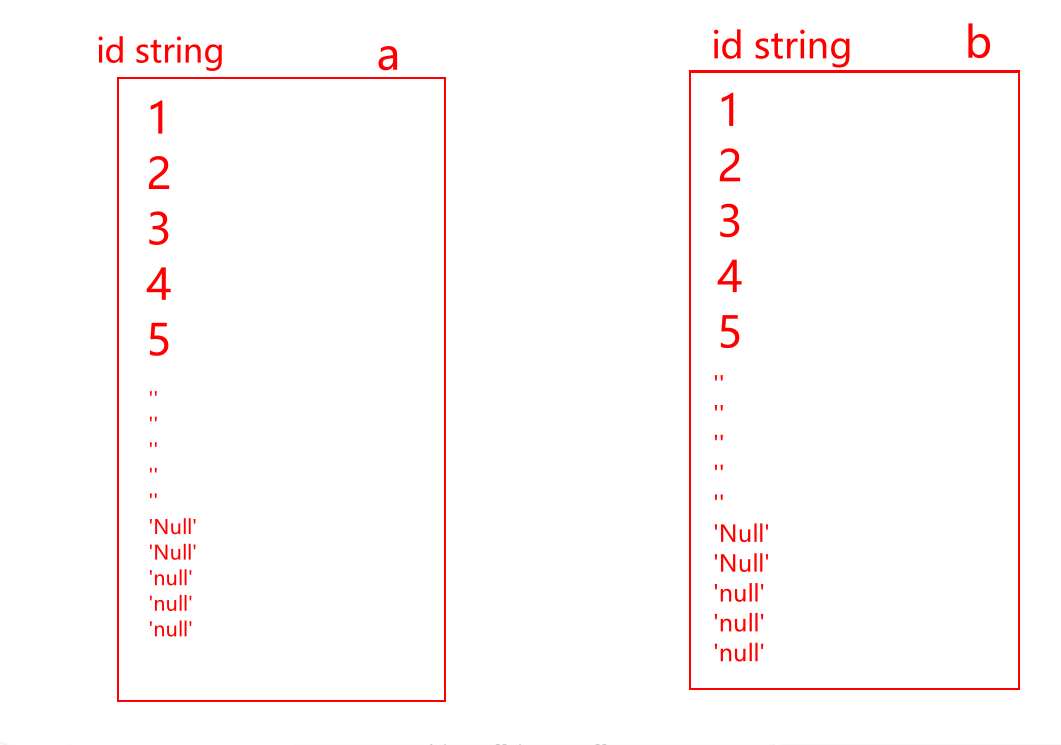
--解决方案一,过滤掉空值select a.*from (select * from a where a.id!='' and lower(a.id) !='null')ajoin (select * from b where b.id!='' and lower(b.id) !='null') b on a.id=b.id;--解决方案二,给空值加随机数select a.* from a join b on if(a.id='' or lower(a.id) ='null',concat(a.id,rand()),a.id)=if(b.id='' or lower(b.id) ='null',concat(b.id,rand()),b.id)select '倾斜key', sum(),count() from table1 where key='倾斜key'union allselect key,sum(),count() from table1 where key!='倾斜key' group by key七、如何理解Spark的RDD
Section titled “七、如何理解Spark的RDD”他是弹性分布式数据集弹性就是,计算以内存为主,如果内存不够,可以借用磁盘分布式就是,计算是分布式的。数据集,可以当做1个容器进行灵活操作RDD有5大特性 1-有分区列表 2-有计算函数 3-有依赖关系 4-【可选】仅当元素是key-value时,有分区器 5-【可选】位置优先性元素不可变,可分区,并行计算 对RDD的计算链条形成的DAG,并划分成stage,方便在stage内合并成pipeline计算。还有一些别的框架没有的功能,缓存持久化【rdd.cache() rdd.persist()】,广播变量,累加器等高级特性。八、SparkOnYarn的调度流程
Section titled “八、SparkOnYarn的调度流程”理解的话,看下面20步 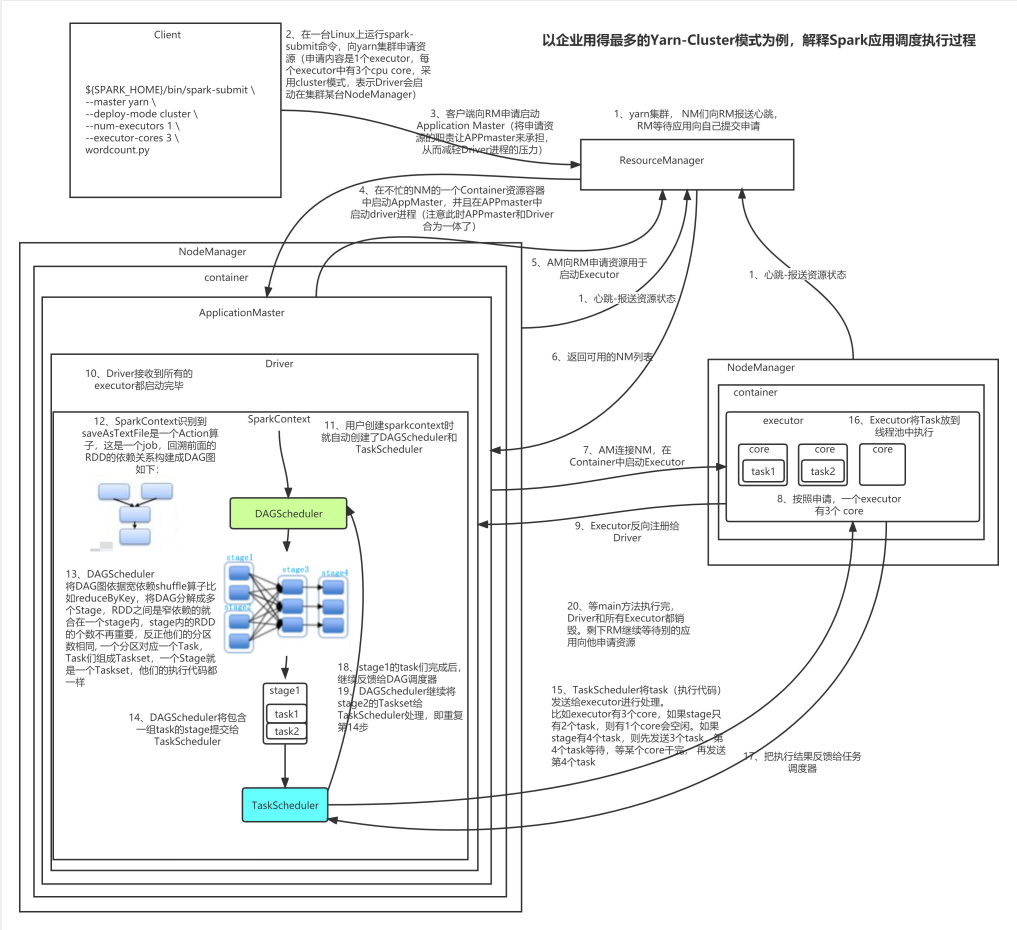 面试的话,只用说下面7步即可
面试的话,只用说下面7步即可 
七、Hive经典10题
Section titled “七、Hive经典10题”- 在pycharm或datagrip中配置hive数据源
- 需要再Linux后台启动
- hadoop的start-all.sh(HDFS和YARN服务)
- hive的metastore服务
- hive的hiveserver2服务
- mysqld服务
- 需要再Linux后台启动
- 完整代码
show databases ;create database if not exists test_sql;use test_sql;-- 一些语句会走 MapReduce,所以慢。 可以开启本地化执行的优化。set hive.exec.mode.local.auto=true;-- (默认为false)--第1题:访问量统计CREATE TABLE test_sql.test1 ( userId string, visitDate string, visitCount INT ) ROW format delimited FIELDS TERMINATED BY "\t";INSERT overwrite TABLE test_sql.test1VALUES ( 'u01', '2017/1/21', 5 ), ( 'u02', '2017/1/23', 6 ), ( 'u03', '2017/1/22', 8 ), ( 'u04', '2017/1/20', 3 ), ( 'u01', '2017/1/23', 6 ), ( 'u01', '2017/2/21', 8 ), ( 'u02', '2017/1/23', 6 ), ( 'u01', '2017/2/22', 4 );select *, sum(sum1) over(partition by userid order by month1 /*rows between unbounded preceding and current row*/ ) as `累积` from(select userid, date_format(replace(visitdate,'/','-'),'yyyy-MM') as month1, sum(visitcount) sum1from test_sql.test1group by userid, date_format(replace(visitdate,'/','-'),'yyyy-MM')) as t;-- 第2题:电商场景TopK统计CREATE TABLE test_sql.test2 ( user_id string, shop string ) ROW format delimited FIELDS TERMINATED BY '\t';INSERT INTO TABLE test_sql.test2 VALUES( 'u1', 'a' ),( 'u2', 'b' ),( 'u1', 'b' ),( 'u1', 'a' ),( 'u3', 'c' ),( 'u4', 'b' ),( 'u1', 'a' ),( 'u2', 'c' ),( 'u5', 'b' ),( 'u4', 'b' ),( 'u6', 'c' ),( 'u2', 'c' ),( 'u1', 'b' ),( 'u2', 'a' ),( 'u2', 'a' ),( 'u3', 'a' ),( 'u5', 'a' ),( 'u5', 'a' ),( 'u5', 'a' );--(1)每个店铺的UV(访客数)-- UV和PV-- PV是访问当前网站所有的次数-- UV是访问当前网站的客户数(需要去重)--(2)每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数select shop, count(distinct user_id) as uvfrom test_sql.test2 group by shop ;--上面的拆解来看,等价于--distinct后可以接多个字段,表示联合去重select shop, count(user_id) as uvfrom(select distinct shop, user_idfrom test_sql.test2 ) as tgroup by shop ;--也等价于select shop, count(user_id) as uvfrom(select shop, user_idfrom test_sql.test2 group by shop, user_id) as tgroup by shop ;select * from(select *, row_number() over (partition by shop order by cnt desc) as rnfrom(select shop,user_id,count(1) as cnt from test_sql.test2 group by shop,user_id ) as t) t2where t2.rn<=3;-- 第3题:订单量统计CREATE TABLE test_sql.test3 ( dt string, order_id string, user_id string, amount DECIMAL ( 10, 2 ) )ROW format delimited FIELDS TERMINATED BY '\t';INSERT overwrite TABLE test_sql.test3 VALUES ('2017-01-01','10029028','1000003251',33.57), ('2017-01-01','10029029','1000003251',33.57), ('2017-01-01','100290288','1000003252',33.57), ('2017-02-02','10029088','1000003251',33.57), ('2017-02-02','100290281','1000003251',33.57), ('2017-02-02','100290282','1000003253',33.57), ('2017-11-02','10290282','100003253',234), ('2018-11-02','10290284','100003243',234);-- (1)给出 2017年每个月的订单数、用户数、总成交金额。-- (2)给出2017年11月的新客数(指在11月才有第一笔订单)select date_format(dt,'yyyy-MM') as month1, count(distinct order_id) as cnt1, count(distinct user_id) as cnt2, sum(amount) as amt from test_sql.test3 where year(dt)=2017group by date_format(dt,'yyyy-MM');select count(user_id) cnt from(select user_id, min(date_format(dt,'yyyy-MM')) min_monthfrom test3 group by user_id) as t where min_month='2017-11';--统计每个月的新客户数select min_month, count(user_id) cntfrom (select user_id, min(date_format(dt, 'yyyy-MM')) min_month from test3 group by user_id) as tgroup by min_month;-- 第4题:大数据排序统计CREATE TABLE test_sql.test4user (user_id string,name string,age int);CREATE TABLE test_sql.test4log (user_id string,url string);INSERT INTO TABLE test_sql.test4user VALUES('001','u1',10),('002','u2',15),('003','u3',15),('004','u4',20),('005','u5',25),('006','u6',35),('007','u7',40),('008','u8',45),('009','u9',50),('0010','u10',65);INSERT INTO TABLE test_sql.test4log VALUES('001','url1'),('002','url1'),('003','url2'),('004','url3'),('005','url3'),('006','url1'),('007','url5'),('008','url7'),('009','url5'),('0010','url1');select * from test_sql.test4user ;select * from test_sql.test4log ;--有一个5000万的用户文件(user_id,name,age),-- 一个2亿记录的用户看电影的记录文件(user_id,url),根据年龄段观看电影的次数进行排序?--取整函数有 round,floor,ceilselect *, round(x,0) as r,--四舍五入 floor(x) as f,--向下取整 ceil(x) as c--向上取整 from(select 15/10 as x union allselect 18/10 as x union allselect 24/10 as x union allselect 27/10 as x ) as t;select type, sum(cnt) as sum1from(select *, concat(floor(age/10)*10,'-',floor(age/10)*10+10) as typefrom test_sql.test4user as a-- join前最好提前减小数据量join (select user_id,count(url) as cnt from test_sql.test4log group by user_id) as bon a.user_id=b.user_id) as tgroup by typeorder by sum(cnt) desc;-- 第5题:活跃用户统计CREATE TABLE test5(dt string,user_id string,age int)ROW format delimited fields terminated BY ',';INSERT overwrite TABLE test_sql.test5 VALUES ('2019-02-11','test_1',23),('2019-02-11','test_2',19),('2019-02-11','test_3',39),('2019-02-11','test_1',23),('2019-02-11','test_3',39),('2019-02-11','test_1',23),('2019-02-12','test_2',19),('2019-02-13','test_1',23),('2019-02-15','test_2',19),('2019-02-16','test_2',19);select * from test_sql.test5 order by dt,user_id;--有日志如下,请写出代码求得所有用户和活跃用户的总数及平均年龄。(活跃用户指连续两天都有访问记录的用户)-- type 总数 平均年龄-- '所有用户' 3 27-- '活跃用户' 1 19with t1 as (select distinct dt, user_id,age from test_sql.test5), t2 as (select *,row_number() over (partition by user_id order by dt) as rn from t1 ), t3 as (select *,date_sub(dt,rn) as dt2 from t2), t4 as (select dt2,user_id,age,count(1) cnt from t3 group by dt2,user_id,age), t5 as (select * from t4 where cnt>=2), t6 as (select distinct user_id,age from t5)select '所有用户' as type, count(user_id) cnt,avg(age) as avg_agefrom (select distinct user_id,age from test_sql.test5) t union allselect '活跃用户' as type, count(user_id) cnt,avg(age) as avg_age from t6;-- 用思路2来分析连续2天登录with t1 as (select distinct dt, user_id from test_sql.test5), t2 as (select *, date_add(dt,1) as dt2, lead(dt,1)over(partition by user_id order by dt) as dt3 from t1)select count(distinct user_id) from t2 where dt2=dt3;-- 第6题:电商购买金额统计实战CREATE TABLE test_sql.test6 ( userid string, money decimal(10,2), paymenttime string, orderid string);INSERT INTO TABLE test_sql.test6 VALUES('001',100,'2017-10-01','123'),('001',200,'2017-10-02','124'),('002',500,'2017-10-01','125'),('001',100,'2017-11-01','126');select * from test_sql.test6 order by userid,paymenttime;--请用sql写出所有用户中在今年10月份第一次购买商品的金额,select userid,paymenttime,moneyfrom(select *, row_number() over (partition by userid order by paymenttime) as rn from test_sql.test6 where date_format(paymenttime,'yyyy-MM')='2017-10' ) as twhere t.rn=1;-- 第7题:教育领域SQL实战CREATE TABLE test_sql.book(book_id string, `SORT` string, book_name string, writer string, OUTPUT string, price decimal(10,2));INSERT INTO TABLE test_sql.book VALUES('001','TP391','信息处理','author1','机械工业出版社','20'),('002','TP392','数据库','author12','科学出版社','15'),('003','TP393','计算机网络','author3','机械工业出版社','29'),('004','TP399','微机原理','author4','科学出版社','39'),('005','C931','管理信息系统','author5','机械工业出版社','40'),('006','C932','运筹学','author6','科学出版社','55');CREATE TABLE test_sql.reader (reader_id string, company string, name string, sex string, grade string, addr string);INSERT INTO TABLE test_sql.reader VALUES('0001','阿里巴巴','jack','男','vp','addr1'),('0002','百度','robin','男','vp','addr2'),('0003','腾讯','tony','男','vp','addr3'),('0004','京东','jasper','男','cfo','addr4'),('0005','网易','zhangsan','女','ceo','addr5'),('0006','搜狐','lisi','女','ceo','addr6');CREATE TABLE test_sql.borrow_log(reader_id string, book_id string, borrow_date string);INSERT INTO TABLE test_sql.borrow_log VALUES ('0001','002','2019-10-14'),('0002','001','2019-10-13'),('0003','005','2019-09-14'),('0004','006','2019-08-15'),('0005','003','2019-10-10'),('0006','004','2019-17-13');select * from test_sql.book;select * from test_sql.reader;select * from test_sql.borrow_log;--(8)考虑到数据安全的需要,需定时将“借阅记录”中数据进行备份,请使用一条SQL语句,-- 在备份用户bak下创建与“借阅记录”表结构完全一致的数据表BORROW_LOG_BAK.-- 井且将“借阅记录”中现有数据全部复制到BORROW_L0G_ BAK中。create table test_sql.BORROW_LOG_BAK as select * from test_sql.borrow_log;select * from test_sql.BORROW_LOG_BAK;--(9)现在需要将原Oracle数据库中数据迁移至Hive仓库,-- 请写出“图书”在Hive中的建表语句(Hive实现,提示:列分隔符|;-- 数据表数据需要外部导入:分区分别以month_part、day_part 命名)CREATE TABLE test_sql.book2( book_id string, `SORT` string, book_name string, writer string, OUTPUT string, price decimal(10, 2))partitioned by (month_part string,day_part string ) row format delimited fields terminated by '|';--(10)Hive中有表A,现在需要将表A的月分区 201505 中-- user_id为20000的user_dinner字段更新为bonc8920,其他用户user_dinner字段数据不变,-- 请列出更新的方法步骤。(Hive实现,提示:Hive中无update语法,请通过其他办法进行数据更新)--A-- user_id user_dinner part-- 20000 aaaaa 201505-- 30000 bbbbb 201505create table A (user_id int,user_dinner string) partitioned by (part string);insert overwrite table A partition (part = '201505')values (20000, 'aaaaa'), (30000, 'bbbbb'), (40000, 'ccccc');select * from A;--update A set user_dinner='bonc8920' where user_id=20000;insert overwrite table A partition (part = '201505')select user_id, if(user_id=20000,'bonc8920',user_dinner) as user_dinnerfrom A where part = '201505';-- 第8题:服务日志SQL统计CREATE TABLE test_sql.test8(`date` string, interface string, ip string);INSERT INTO TABLE test_sql.test8 VALUES('2016-11-09 11:22:05','/api/user/login','110.23.5.23'),('2016-11-09 11:23:10','/api/user/detail','57.3.2.16'),('2016-11-09 23:59:40','/api/user/login','200.6.5.166'),('2016-11-09 11:14:23','/api/user/login','136.79.47.70'),('2016-11-09 11:15:23','/api/user/detail','94.144.143.141'),('2016-11-09 11:16:23','/api/user/login','197.161.8.206'),('2016-11-09 12:14:23','/api/user/detail','240.227.107.145'),('2016-11-09 13:14:23','/api/user/login','79.130.122.205'),('2016-11-09 14:14:23','/api/user/detail','65.228.251.189'),('2016-11-09 14:15:23','/api/user/detail','245.23.122.44'),('2016-11-09 14:17:23','/api/user/detail','22.74.142.137'),('2016-11-09 14:19:23','/api/user/detail','54.93.212.87'),('2016-11-09 14:20:23','/api/user/detail','218.15.167.248'),('2016-11-09 14:24:23','/api/user/detail','20.117.19.75'),('2016-11-09 15:14:23','/api/user/login','183.162.66.97'),('2016-11-09 16:14:23','/api/user/login','108.181.245.147'),('2016-11-09 14:17:23','/api/user/login','22.74.142.137'),('2016-11-09 14:19:23','/api/user/login','22.74.142.137');select * from test_sql.test8;--求11月9号下午14点(14-15点),访问/api/user/login接口的top10的ip地址select ip, count(1) cntfrom test_sql.test8where date_format(`date`, 'yyyy-MM-dd HH') = '2016-11-09 14' and interface = '/api/user/login'group by iporder by cnt desclimit 10;-- 第9题:充值日志SQL实战CREATE TABLE test_sql.test9( dist_id string COMMENT '区组id', account string COMMENT '账号', `money` decimal(10,2) COMMENT '充值金额', create_time string COMMENT '订单时间');INSERT INTO TABLE test_sql.test9 VALUES ('1','11',100006,'2019-01-02 13:00:01'), ('1','22',110000,'2019-01-02 13:00:02'), ('1','33',102000,'2019-01-02 13:00:03'), ('1','44',100300,'2019-01-02 13:00:04'), ('1','55',100040,'2019-01-02 13:00:05'), ('1','66',100005,'2019-01-02 13:00:06'), ('1','77',180000,'2019-01-03 13:00:07'), ('1','88',106000,'2019-01-02 13:00:08'), ('1','99',100400,'2019-01-02 13:00:09'), ('1','12',100030,'2019-01-02 13:00:10'), ('1','13',100003,'2019-01-02 13:00:20'), ('1','14',100020,'2019-01-02 13:00:30'), ('1','15',100500,'2019-01-02 13:00:40'), ('1','16',106000,'2019-01-02 13:00:50'), ('1','17',100800,'2019-01-02 13:00:59'), ('2','18',100800,'2019-01-02 13:00:11'), ('2','19',100030,'2019-01-02 13:00:12'), ('2','10',100000,'2019-01-02 13:00:13'), ('2','45',100010,'2019-01-02 13:00:14'), ('2','78',100070,'2019-01-02 13:00:15');select * from test_sql.test9 order by dist_id , money desc;--请写出SQL语句,查询充值日志表2019年01月02号每个区组下充值额最大的账号,要求结果:--区组id,账号,金额,充值时间select * from(select *, row_number() over (partition by dist_id order by money desc) rnfrom test_sql.test9 where to_date(create_time)='2019-01-02') twhere t.rn=1;-- 第10题:电商分组TopK实战CREATE TABLE test_sql.test10( `dist_id` string COMMENT '区组id', `account` string COMMENT '账号', `gold` int COMMENT '金币');INSERT INTO TABLE test_sql.test10 VALUES ('1','77',18), ('1','88',106), ('1','99',10), ('1','12',13), ('1','13',14), ('1','14',25), ('1','15',36), ('1','16',12), ('1','17',158), ('2','18',12), ('2','19',44), ('2','10',66), ('2','45',80), ('2','78',98);select * from test_sql.test10;select * from(select *, row_number() over (partition by dist_id order by gold desc) rnfrom test_sql.test10 ) twhere t.rn<=10; 发布于 2022-10-02